This is a placeholder page that shows you how to use this template site.
This section is where the user documentation for your project lives - all the information your users need to understand and successfully use your project.
For large documentation sets we recommend adding content under the headings in this section, though if some or all of them don’t apply to your project feel free to remove them or add your own. You can see an example of a smaller Docsy documentation site in the Docsy User Guide, which lives in the Docsy theme repo if you’d like to copy its docs section.
Other content such as marketing material, case studies, and community updates should live in the About and Community pages.
Find out how to use the Docsy theme in the Docsy User Guide. You can learn more about how to organize your documentation (and how we organized this site) in Organizing Your Content.
mdsilo : Lightweight plain-text knowledge silo and networked-writing tool.
VS Code : code editor
Office Suite
LibreOffice : open source office suite (Writer, Calc, Impress, Draw, Math, Base)
Microsoft Office : office suite from Microsoft (Word, Excel, Powerpoint, Access)
Scrivener : word processor
Others
Nimbletext : text batch manipulation
BabelMap : unicode character
V380 : Webcam monitoring
Glance by Mirametrix: object detection
BlueStacks : Android Emulator
BlueStacks X: Bluestack Gaming Platform
Anki : card repetition learning app
Picpick : screen shoot, desktop record, screen ruler, color picker
PDF Tool
CutePDF Writer: pdf writer, pdf printer
ByteScout PDF Multitool* : pdf editor (split, merge, rotate, remove), pdf extractor (table, image), pdf compressor, pdf OCR, pdf converter (image, html), pdf parser
PDFsam Basic: pdf editor (split, combine, merge, rotate)
MuPDF : very lightweight pdf, xps, epub, cbz viewer
Foxit Reader : pdf reader (reflow, rotate), pdf anotation (comment, type, draw, sign, stamp)
SumatraPDF : fast pdf reader
GPL Ghostscript : pdf rendering engine
Free PDF Compressor : pdf compressor
PDF Reader by Xodo : pdf reader (reflow, rotate), pdf compressor, pdf anotation (comment, type, draw, sign, stamp), pdf editor (split, rearrange)
Imron Rosyadi, Vidi Fitriansyah Hidarlan, Farida Asriani, and Rifah Ediati, 2020. A Deep Learning for Varieties Classification of Bulk Samples of Rice, 2020 International Conference on Engineering, Technology and Innovative Researches (ICETIR).
Imron Rosyadi, Fendy Prayogi, Farida Asriani, Rifah Ediati, 2020. Rice Fields Classification among Google Earth Sattelite Images using Convolutional Neural Network, 2020 The 2nd International Conference On Sustainable Agriculture For Rural Development (2nd ICSARD).
Imron Rosyadi, Noer Aditama, Rifah Ediati, 2020. Deep Learning for Rice Quality Classification, 3rd International Conference on Multidisciplinary Approaches for Sustainable Rural Development 2020 (3rd ICMA-SURE 2020).
Hak Kekayaan Intelektual (Intellectual Properties)
Imron Rosyadi, 2020, Metode Penamaan Warna (Color Naming) untuk Komunikasi Warna Bahasa Indonesia. Paten (No Pendaftaran P00202009614)
Imron Rosyadi, 2020, Metode Penyandian (Encoding) dan Pengawasandian (Decoding) Koordinat Lokasi dengan Sandi Suku Kata dan Angka. Paten (No Pendaftaran S00202005863)
Imron Rosyadi, 2020, Sistem Penyandi (Encode), Pengawasandi (Decode) dan Komunikasi Koordinat Lokasi dengan Sandi Suku Kata dan Angka. Paten (No Pendaftaran S00202005862, Berita Paten)
Imron Rosyadi, 2019, Perangkat Lunak Pewarnaan Citra Skala Abu-abu dengan Variasi Fungsi Afinitas. Hak Cipta (No Pencatatan: 000164119).
Mulki Indana Zulfa, Imron Rosyadi, Ari Fadli, Acep Taryana, 2019, Software Monitoring Tugas Akhir di Teknik Elektro Universitas Jenderal Soedirman. Hak Cipta (No Pencatatan: 000164521).
Winasis, Imron Rosyadi, Irfan Ahmad Faqih, 2019, Software Pemantauan Debit Air Saluran Terbuka dengan Sensor Ultrasonik dan Rotary Encoder Berbasis Web Menggunakan Arduino. Hak Cipta (No Pencatatan: 000163870).
Acep Taryana, Azis Wisnu Widhi Nugraha, Imron Rosyadi, Priswanto, 2019, Desain Platform DevOps sebagai Alat Bantu Pengembangan Skripsi Bidang Sistem Tertanam di Jurusan Teknik Elektro. Hak Cipta (No Pencatatan: 000163408).
QuillBot AI: paraphraser, grammar checker, plagiarism checker, summarizer, citation generator, extension (Chrome, Google Docs, MS Word). Premium: $9.95 USD/month
Trinka: grammar checker, publication assistant, consistency checker, extension (Browser, MS Word (Premium)). Free Up to 10,000 words/month, Premium: $20 USD/month
OZDIC.COM - English collocation dictionary. online English collocations dictionary which helps you to find words that often appear together and gives you an idea of how the words are used. free
Kaldi : STT supports hybrid NN-HMM and lattice-free MMI models. Kaldi is used by many people both in research and in production.
Lingvo is the open source version of Google speech recognition toolkit, with support mostly for end-to-end models.
ESPNet is good and well known for end-to-end models as well.
RASR + RETURNN are very good as well, both for end-to-end models and hybrid NN-HMM, but they are for non-commercial applications only (or you need a commercial licence) (disclaimer: I work at the university chair which develops these frameworks).
Cognicull : Cognicull is a learning site that pursues “ease of understanding” and “comfort”. It is designed so that knowledge of mathematics, natural science, and engineering can be gained easily.
Challenges
These map to the learning objectives or learning goals.
Levels
These map to the learning journey and as the learner goes through each level, it signifies a step up in proficiency for them.
Instant feedback
This helps learners know how they are faring against their learning goals and based on this, they can adopt the necessary measures to step up their performance.
Scores
They are indicators of their performance and are closely aligned to offering gratification as well as a sense of accomplishment.
Badges
As the learners go through the learning path and clear certain levels, they are given badges. These reflect affirmations for their significant achievements.
Leaderboards
They are dashboards that are used to provide a pictorial view of the overall progress—including against others. The analytics keeps learners connected to the learning journey and aligned to meeting their terminal objectives.
Competition
This can be leveraged effectively as it helps learners assess where they stand against other peers or competing teams.
Collaboration
This feature not only facilitates team-building but also enables learners to leverage the support of peers or guidance from experts to meet their goals.
Points and currency
Points are a variation on badges, and can also be used as currency within a program. For instance, you can offer learners a point for every comment the leave in the discussion forum, and then let them redeem a certain number of points for rewards and discounts.
Progress bars and level up
Progress bars can help by visualizing their advancements. You can even add a bit of interest by creating “level ups” that unlock new course features.
Anti-cheating Strategy in Testing
make questions brutal and unique (compared to previous year or current groups) if possible
mixing (randomizing) the order of questions,
not giving question titles,
having a pool of subtly different questions (a negation or a different constant slipped in)
make everything open-book, make the questions things that test understanding instead of just recall or design questions that require critical thinking, and allow everyone to use their computers/books/notes/whatever
A (simple) /B (reasoning and analysis) /C (problem with deeper understanding): with different weight for example 50/30/20.
project work
put a lot of emphasis on group work & home work
writing essays
set a tough time limit
curve the results to a desired grade distribution (that is often imposed from above anyway)
use software that can the catch most obvious frauds (i.e. 360 degree room scanning, ban use of phones/second computers etc.)
if the exam requires algorithms, use software analyzing AST of the code produced to catch possible “cooperation”, then decide on those cases individually (i.e. if an algorithm is common, then there is a high chance of very similar AST for non-cooperating people, but if it’s unique, the chance is low)
EasyOCR Ready-to-use OCR with 70+ languages supported. Colab
Constraint Solver
OptaplannerGitHub: OptaPlanner is an AI constraint solver. It optimizes planning and scheduling problems, such as the Vehicle Routing Problem, Employee Rostering, Maintenance Scheduling, Task Assignment, School Timetabling, Cloud Optimization, Conference Scheduling, Job Shop Scheduling, etc.
gatsby - Build blazing fast, modern apps and websites with React.
preact - Fast 3kB React alternative with the same modern API.
react-admin - A frontend Framework for building B2B applications running in the browser on top of REST/GraphQL APIs, using ES6, React and Material Design
LatexDraw : LaTeXDraw is a graphical drawing editor for LaTeX. LaTeXDraw can be used to 1) generate PSTricks code; 2) directly create PDF or PS pictures.
Browserleaks : Web security testing tools to show what kind of personal identity data leaked
IPInfo : Checks what security related information is exposed by browser to any website
Site Information
Site Information Tools : useful information of site (rankings, SEO and linking information, whois data, IP address details, analyse page data, server response headers)
Google Safe Browsing : examines billions of URLs per day looking for unsafe websites
solution : VPN, power tunnel (android), power tunnel pc, green tunnel, wireguard, webproxy, etc
advantage of power tunnel and green tunnel : you will connect through local proxy which mean your quota internet usage would not exceed
the disadvantage : sometimes it not work against DPI filter from ISP
advantage of vpn, wireguard, webproxy : work smoothly against DPI filter or other gov censor
the disadvantage : your internet quota will be exceed, since you connect through remote proxy. There will be extra data need to be carried
openvpn personal recomendation is this, or this
Pose Animator. Pose Animator takes a 2D vector illustration and animates its containing curves in real-time based on the recognition result from PoseNet and FaceMesh. It borrows the idea of skeleton-based animation from computer graphics and applies it to vector characters.
SUDO RM RF : SUccessive DOwnsampling and Resampling of Multi-Resolution Features which enables a more efficient way of separating sources from mixtures
Deep Audio : Audio Source Separation Without Any Training Data
We cannot listen the audio output from playback apps
Use cases:
Record Zoom Webinar to Speechtexter, Google Docs etc.
Audio Input Mixing
Use cases:
Record with multiphttps://raw.githubusercontent.com/irosyadi/vnote.image/master/vnotebook/app/music-audio-tool.md/20211023055947660_4903.pngP) to Audacity
Broadcast with multiple input (our voice + music from AIMP) to Zoom, Youtube etc.
Transcribe (and listen) Zoom Seminar to Speaker and Speechtexter, Google Docs
Translate Youtube Video using Google Translate
Zoom Audio Recording/Transcription
Google Meet Audio Transcription
Open Google Meet, usihttps://raw.githubusercontent.com/irosyadi/vnote.image/master/vnotebook/app/music-audio-tool.md/20211023061101034_12558.pngsing default Mic
But we cannot do both Speechtexter and Google Docs
We cannot do both Speechtexter and Voice Note
We can do both Google Meet and Speechtexter/VoiceNote/Dictanote
We can do both Zoom and Speechtexter/VoiceNote/Dictanote
Mito Mito is an editable spreadsheet in your Jupyter notebook. You can clean, filter, find/replace, and use standard spreadsheet functions in Mito, giving you the visibility and ease of a spreadsheet with the power of Python.
RISE : RISE allows you to instantly turn your Jupyter Notebooks into a slideshow. No out-of-band conversion is needed, switch from jupyter notebook to a live reveal.js-based slideshow in a single keystroke, and back.
GeoNotebook : A Jupyter notebook extension for geospatial visualization and analysis
nbinteract : Python package that provides a command-line tool to generate interactive web pages from Jupyter notebooks
Jupyterhub : Multi-user server for Jupyter notebooks
LaTeXDraw - A vector drawing editor for LaTeX LaTeXDraw is a graphical drawing editor for LaTeX. LaTeXDraw can be used to 1) generate PSTricks code; 2) directly create PDF or PS pictures.
DownThemAll! : The Mass Downloader for your browser
Github
Enhanced GitHub : Display repo size, size of each file, download link and option to copy file contents
Gitako - GitHub file tree : File tree for GitHub, and more than that.
Search Tools
Add custom search engine : Add a custom search engine to the list of available search engines in the search bar.
Selection Context Search : Right click on a selected text and choose the search website from the popup window or the context menu.
Swift Selection Search : Swiftly access your search engines in a popup panel when you select text in a webpage.
Tab Management
Auto Tab Discard : Increase browser speed and reduce memory load and when you have numerous open tabs.
Containerise : Firefox extension to automatically open websites in a container
Containers theme : Change theme color based on your container color
Facebook Container : Facebook Container isolates your Facebook activity from the rest of your web activity in order to prevent Facebook from tracking you outside the Facebook website via third party cookies.
Firefox Multi-Account Containers : Multi-Account Containers helps you keep all the parts of your online life contained in different tabs.
Sidebery : Add-on for managing tabs, containers (contextual identities) and bookmarks in sidebar.
RSS
Awesome RSS : Puts an RSS/Atom subscribe button back in URL bar
Feedbro : Advanced Feed Reader - Read news & blogs or any RSS/Atom/RDF source.
Password Management
Bitwarden - Free Password Manager : A secure and free password manager for all of your devices.
Blocking Tools
Javascript Switcher : Add a button in the url bar to block or enable javascript per-site.
ClearURLs : Remove tracking elements from URLs.
HTTPS Everywhere : Encrypt the Web! Automatically use HTTPS security on many sites.
uBlock Origin : Finally, an efficient blocker. Easy on CPU and memory.
Google Direct : Remove tracking links from Google Search results
Site Enhancement
Refined Hacker News : Add useful features and tweak a little stuff to make the HN experience better without changing the look and feel
Dark Reader : Dark mode for every website. Take care of your eyes, use dark theme for night and daily browsing.
Wikiwand: Wikipedia Modernized : Good old Wikipedia gets a great new look
Violentmonkey : An open source user script manager that supports a lot of browsers
Reddit
Epiverse : View Reddit and Hacker News comments on all webpages.
Thredd - Useful Advice from Reddit : Get reviews for the page you’re reading or recommendations for similar content - crowdsourced from Reddit!
Reddit Enhancement Suite : A suite of modules that enhance your Reddit browsing experience
Research
Find Code for Research Papers - CatalyzeX : Find code implementations for machine learning research papers with code directly on Google, Arxiv, Scholar, Twitter, Github, etc.
Page Information
What Hacker News Says : Easily find Hacker News threads about the page you’re currently browsing.
Browsing Tools
Copy Selection as Markdown : Copy title, URL, and selection as Markdown
markdown-clipper : This extension works like a web clipper, but it downloads articles in a Markdown format.
Open in Sumatra PDF and DJVU Reader : Adds a context menu item to send PDF links directly to Sumatra PDF
Open in VLC™ media player : Adds a context menu to send audio and video streams directly to the well-known VLC™ media player
SingleFile : Save a complete page into a single HTML file
Research
Mendeley Web Importer : Fast, convenient import of references and PDFs to your Mendeley Reference Manager library
NoteBook Buddy : Provides a helping hand when using Jupyter NoteBooks
Time Management
Mind the Time : Keep track of how much time you spend on the web, and where you spend it.
Pomodoro clock : A simple pomodoro clock in your browser to hack your productivity.
zola (MIT) : A fast static site generator in a single binary with everything built-in.
Publii (GPL 3.0) : Publii is a desktop-based CMS for Windows, Mac and Linux that makes creating static websites fast and hassle-free, even for beginners.
Susty (GPL 2.0) : A tiny WordPress theme focused on being as sustainable as possible. Just 6 KB of data transfer.
Logseq, note taking web based local only and GitHub-hosted
Typora, a nicely polished Markdown editor – has the best support for math input I’ve seen
Obsidian, a split-pane Markdown editor focused on bidirectional linking
Zettlr a Markdown editor focused on publishing / academics
RemNote converts your notes into spaced-repetition flash cards, similar to Anki
foambubble, a family of VS Code extensions to help search + organize your notes
Neuron Notes a neat Zettelkasten system written in Haskell, based on GitHub repos
R Studio includes an awesome Markdown publishing experience, similar to Jupyter Notebooks
(coming soon) Athens Research, an open-source alternative to Roam
(coming soon, made by me) Noteworthy, which aims to be an extensible, open-source alternative to Obsidian and Typora, with a focus on wikilinks and excellent math support
Dendron, a hierarchical note-taking editor based on VS Code
kb, a minimal text-oriented command-line note manager
💡 Alternative frontends offer ad-free and light browsing experiences.
💡 Alternative frontends also offer better user experiences than their original apps.
Pattern description is also optional.
Here we need to something extra because above rules will cause this issue. Thanks to einaregilsson for helping me to solve that issue.
A port forward is a way of making a computer on your home or business network accessible to computers on the internet, even though they are behind a router. (portforward)
By default, its only output is its return
code, which is 0 if there are no differences and 1 if the two PDFs differ. If
given the --output-diff option, it produces a PDF file with visually
highlighted differences:
$ diff-pdf --output-diff=diff.pdf a.pdf b.pdf
Copy
Another option is to compare the two files visually in a simple GUI, using
the --view argument:
$ diff-pdf --view a.pdf b.pdf
Copy
This opens a window that lets you view the files’ pages and zoom in on details.
It is also possible to shift the two pages relatively to each other using
Ctrl-arrows (Cmd-arrows on MacOS). This is useful for identifying translation-only differences.
See the output of $ diff-pdf --help for complete list of options.
ESP Home ESPHome is a system to control your ESP8266/ESP32 by simple yet powerful configuration files and control them remotely through Home Automation systems.
MediaPipe Objectron by Google The model was designed for real-time 3D object detection for mobile devices. This model was trained on a fully annotated, real-world 3D dataset and could predict objects’ 3D bounding boxes. GitHub
CIELUV Ch (CIE LCh) or Polar Luv is cylindrical representation of CIELUV (and for CIELAB : Polar Lab)
HCL is implementation of CIELUV Ch
Problem of HCL: HCL tends to specify colors outside of the RGB gamut, which means that some sensible choices of HCL values will generate values outside the (0,0,0)-(1,1,1) RGB cube. More worryingly, the HCL->RGB transformation is discontinuous. Although it lies outside the RGB gamut, clamping the transform to the closest RGB point does not patch the seam in the color space. Example of Clamping
HCL to RGB need conversion chain : HCL->LUV->XYZ->RGB
HSLuv, other implementation of CIELUV Ch which fully maps to RGB. HSLuv is just like LCH except that it stretches the saturated colors for each hue so that any saturation coordinate represents a valid color, unlike LCHs chroma coordinate. The downside is that the colors chroma (colorfulness) can change when you drag the hue slider. HSLuv, is based on CIELCHuv, the cylindrical transformation of CIELUV; the LCH in David Johnstone’s colour picker is CIELCHab, the cylindrical transformation of CIELAB.
Theory of Color: If RGB fits to how screens produce colors, if CIE Lab* fits to how we perceive colors, HCL fits to how we think colors. It is like HSL, but perceptively unbiased.
Unicode is an information technology (IT) standard for the consistent encoding, representation, and handling of text expressed in most of the world’s writing systems. Within Unicode encoding, there are subsets called emoji to represent pictorial expression in characters. While Unicode is an important piece of work, it has some kind of messy structure. That’s why we have puny code.
Google hacking, also named Google dorking or Google advanced search, is a hacker technique that uses Google Search and other Google applications to find security holes in the configuration and computer code that websites use.
Basics. “Google hacking” involves using advanced operators in the Google search engine to locate specific strings of text within search results.
Force an exact-match search. Use this to refine results for ambiguous searches, or to exclude synonyms when searching for single words.
Example:“steve jobs”
OR
Search for X or Y. This will return results related to X or Y, or both. Note: The pipe (|) operator can also be used in place of “OR.”
Examples:jobs OR gates / jobs | gates
AND
Search for X and Y. This will return only results related to both X and Y. Note: It doesn’t really make much difference for regular searches, as Google defaults to “AND” anyway. But it’s very useful when paired with other operators.
Example: jobs AND gates
-
Exclude a term or phrase. In our example, any pages returned will be related to jobs but not Apple (the company).
Example:jobs ‑apple
*
Acts as a wildcard and will match any word or phrase.
Example:steve * apple
( )
Group multiple terms or search operators to control how the search is executed.
Example:(ipad OR iphone) apple
$
Search for prices. Also works for Euro (€), but not GBP (£) 🙁
Example:ipad $329
define:
A dictionary built into Google, basically. This will display the meaning of a word in a card-like result in the SERPs.
Example:define:entrepreneur
cache:
Returns the most recent cached version of a web page (providing the page is indexed, of course).
Example:cache:apple.com
filetype:
Restrict results to those of a certain filetype. E.g., PDF, DOCX, TXT, PPT, etc. Note: The “ext:” operator can also be used—the results are identical.
Example:apple filetype:pdf / apple ext:pdf
site:
Limit results to those from a specific website.
Example:site:apple.com
Find pages with a certain word (or words) in the title. In our example, any results containing the word “apple” in the title tag will be returned.
Example:intitle:apple
allintitle:
Similar to “intitle,” but only results containing all of the specified words in the title tag will be returned.
Example:allintitle:apple iphone
inurl:
Find pages with a certain word (or words) in the URL. For this example, any results containing the word “apple” in the URL will be returned.
Example:inurl:apple
allinurl:
Similar to “inurl,” but only results containing all of the specified words in the URL will be returned.
Example:allinurl:apple iphone
intext:
Find pages containing a certain word (or words) somewhere in the content. For this example, any results containing the word “apple” in the page content will be returned.
Example:intext:apple
allintext:
Similar to “intext,” but only results containing all of the specified words somewhere on the page will be returned.
Example:allintext:apple iphone
AROUND(X)
Proximity search. Find pages containing two words or phrases within X words of each other. For this example, the words “apple” and “iphone” must be present in the content and no further than four words apart.
Example:apple AROUND(4) iphone
weather:
Find the weather for a specific location. This is displayed in a weather snippet, but it also returns results from other “weather” websites.
Example:weather:san francisco
stocks:
See stock information (i.e., price, etc.) for a specific ticker.
Example:stocks:aapl
map:
Force Google to show map results for a locational search.
Example:map:silicon valley
movie:
Find information about a specific movie. Also finds movie show times if the movie is currently showing near you.
Example:movie:steve jobs
in
Convert one unit to another. Works with currencies, weights, temperatures, etc.
Example:$329 in GBP
Note that these suggestions are off the top of my head and surely biased by my own needs.
bash shell basics
Navigating the shell.
Using one of the common editors, such as vim, emacs, or nano. My personal favorite is vim, but that’s probably because I’ve been using it (or its predecessor, vi) longer than most redditors have been alive.
Listing (ls) and deleting (rm) files.
Changing file permissions (chmod).
Using the find command.
Using basic Linux tools in pipelines, such as tr, wc, basename, dirname, etc.
Using awk/gawk. This tool is so incredibly powerful. I use it almost daily.
Using apt. Note that apt-get is the older package manager, and although it’s largely compatible with apt, there are some differences.
Programming
Learn the basics of bash shell programming, including conditional statements, looping structures, variables, etc.
Definitely learn python, with a focus on python3.
php: see Web Dev below.
Learning C and/or C++ are desirable too, but you don’t need this skill immediately. However, knowing these languages will give you better knowledge for compiling packages and eventually writing your own.
Web servers
You won’t go wrong with apache2, but these days, I’m using nginx more often.
SageMath : open-source mathematics software system, builds on top of : NumPy, SciPy, matplotlib, Sympy, Maxima, GAP, FLINT, R and many more and using Python-based language or directly via interfaces or wrappers
Julia
Octave-based Course
An introduction to programming with Octave: OctaveAtBFH.pdf License: CC-BY
Codes used in the lecture notes Codesor in one file at Codes.tgz.
Skyhub : Skyhub provides a way of accessing the libgen scimag / sci-hub torrent archive on a one-off basis. It stands up what looks like a local copy of sci-hub.
This is not a list of free programming books. This is a curated list of open source or open source licensed documents, guides, books which can read, use, modify, translate, redistribute and even rewrite under their license.
Document Template
[TITLE][repository-url] by AUTHOR ([SITE][site-url], LICENSE) - SHORT DESCRIPTION
Structure and Interpretation of Computer Programs (Site, cc-sa)
Programming Languages: Application and Interpretation (Site, cc-nc-sa)
Practical Foundations for Programming Languages (Site, cc-nc-nd)
Open Data Structures (Site, cc) - To provide a high-quality open content data structures textbook that is both mathematically rigorous and provides complete implementation
Algorithms, Etc. (Site, cc-nc-sa) - This page contains lecture notes and other course materials for various algorithms classes Jeff Erickson have taught at the University of Illinois, Urbana-Champaign.
Introduction to Theory of Computation (Site, cc-sa) - This is a free textbook for an undergraduate course on the Theory of Computation, which we have been teaching at Carleton University since 2002
Discrete Structures for Computer Science: Counting, Recursion, and Probability (Site, cc-nc-sa) - This is a free textbook for an undergraduate course on Discrete Structures for Computer Science, which I have been teaching at Carleton University since 2013
graphbook (GNU-FDL) - A GNU-FDL book on algorithmic graph theory by David Joyner, Minh Van Nguyen, and David Phillips. This is an introductory book on algorithmic graph theory
Programming on Parallel Machines (Site, cc-nd) - The purpose of this book is to help you program shared-memory parallel machines without risking your sanity
Natural Language Processing for the Working Programmer (Site, cc) - We will go into many of the techniques that so-called computational linguists use to analyze the structure of human language, and transform it into a form that computers work with
Fundamentals of Programming: With Object Oriented Programming (Site, cc-nc-sa) - This book presents a balanced and flexible approach to the incorporation of object-oriented principles in introductory courses using Python
Introduction to Computing (Site, cc-nc-sa) - This book introduces the most important ideas in computing using the Scheme and Python programming languages. It focuses on how to describe information processes by defining procedures, how to analyze the costs required to carry out a procedure, and the fundamental limits of what can and cannot be computed mechanically
Computer Science from the Bottom Up (Site, cc-sa) - Computer Science from the Bottom Up—A free, online book designed to teach computer science from the bottom end up. Topics covered include binary and binary logic, operating systems internals, toolchain fundamentals and system library fundamentals
Data Compression Explained (Site, custom liscense) - This book is for the reader who wants to understand how data compression works, or who wants to write data compression software.
Data Science and Statistics
LearnDataScience (BSD) - Open Content for self-directed learning in data science
Think Stats (Site, cc-sa) - Probability and Statistics for Programmers
A Brief Introduction to Neural Networks (Site, cc-nc-nd)
Bayesian Methods for Hackers (Site, MIT) - An intro to Bayesian methods and probabilistic programming from a computation/understanding-first, mathematics-second point of view
The Book Of Jupyter (Site, cc) - This is some of the material that covers the advanced Jupyter/IPython SciPy tutorial that is/was/will be given in July 2015
Devops
Ops School Curriculum (Site, cc) - Ops School is a comprehensive program that will help you learn to be an operations engineer
Twelve Factor App (Site, MIT) - The twelve-factor app is a methodology for building software-as-a-service apps
Digital Oceans - Tutorials (Site, cc-nc-sa) - development and sysadmin tutorials
.htaccess Snippets (Public Domain) - A collection of useful .htaccess snippets, all in one place.
Free as in Freedom (2.0) (Site, GNU-FDL) - Free as in Freedom (2.0) is Stallman’s revision of the original biography.
The Daemon, the GNU & the Penguin ~ by Dr. Peter Salus (Site, cc-nc-nd)
Programming
500 Lines or Less (cc & mit) - This is the source for the book 500 Lines or Less, the fourth in the Architecture of Open Source Applications series.
Guides (cc) - Guides for getting things done, programming well, and programming in style.
An App Launch Guide (Site, Public Domain) - This guide goes through all of the necessary steps for validating, building, marketing, and launching your product, specifically focused on app dev.
Build Podcast (Site, Public Domain) - Build Podcast is a show about technology tools for design and development all in the fun spirit of hacking, creating and building stuff!
Mozilla Developer Network (Site, cc-by-sa) - Shared knowledge for the Open Web
The Little Introduction To Programming (Site, cc-nc) - This book will teach you the fundamentals of programming and act as a foundation for whatever your programming goals may be.
The Programming Historian (Site, cc) - The Programming Historian is an online, open-access, peer-reviewed suite of tutorials that help humanists learn a wide range of digital tools, techniques, and workflows to facilitate their research.
North (Site, MIT) - MIT Design and development standards to align and guide your project.
RESTful Web APIs (Site, cc-nc-nd) - Restful Web APIs was the first book-length treatment of RESTful design, and the predecessor to RESTful Web APIs.
DOM Enlightenment (Site, cc-nc-nd) - Exploring the relationship between JavaScript and the modern HTML DOM
http2 explained (Site, cc-nc-nd) - http2 explained is a detailed document explaining and documenting https/2, the successor to the widely popular https/1.1 protocol
Writings and Documentation
Write the Doc (Site, cc) - A place for Sphinx documentation and general writing of things.
CommonMark Spec (Site, cc-sa) - CommonMark is a rationalized version of Markdown syntax, with a spec and BSD-licensed reference implementations in C and JavaScript.
reStructuredText Markup Specification (Site, Public Domain)
Prose for Programmers (cc-nc-nd) - A book to help software developers write better prose
Journalism and Visualization
Data Journalism Handbook (cc-sa) - The Data Journalism Handbook is a free, open source reference book for anyone interested in the emerging field of data journalism
Intro to D3.js (Site, Apache 2.0) - The tutorial provides a quick intro to D3.js, a Javascript library for creating data visualizations in the browser.
The Nature of Code (Site, cc-nc, LGPL) - This book focuses on the programming strategies and techniques behind computer simulations of natural systems using Processing
Data Science 45-min Intros (Public Domain) - Ipython notebook presentations for getting starting with basic programming, statistics and machine learning techniques
Data + Design (Site, cc-nc-sa) - A Simple Introduction to Preparing and Visualizing Information
Introduction to Programming using Fortran 95 (Site, cc-nc-sa) - This text provides an introduction to programming and problem solving using the Fortran 95 programming language.
Learn You a Haskell for Great Good! (Site, cc-nc-sa) - Learn You a Haskell for Great Good! is a hilarious, illustrated guide to this complex functional language
How to learn Haskell (cc0) - This is a recommended path for learning Haskell based on experience helping others
Haskell By Example (Site, cc) - Haskell by Example is a port of Go by Example to Haskell
Javascript
Learning JavaScript Design Patterns (Site, cc-nc-nd) - In this book we will explore applying both classical and modern design patterns to the JavaScript programming language
JavaScript-Garden (Site, MIT) - A collection of documentation about the most quirky parts of the JavaScript language
ECMAScript 6 Features (MIT) - ECMAScript 6, also known as ECMAScript 2015, is the latest version of the ECMAScript standard
React Primer Draft (GNU) - A primer for building Single-Page Applications with React
Angular Style Guide (MIT) - Angular Style Guide: A starting point for Angular development teams to provide consistency through good practices
JavaScript : The Right Way (Site, cc-nc-sa) - This is a guide intended to introduce new developers to JavaScript and help experienced developers learn more about its best practices
Idiomatic JavaScript (cc) - Principles of Writing Consistent, Idiomatic JavaScript
Angular Test Patterns (MIT) - A High-Quality Guide for Testing Angular 1.x Applications
JavaScript Garden (Site, MIT) - A collection of documentation about the most quirky parts of the JavaScript language
Node.js Style Guide (cc-sa) - A guide for styling your node.js / JavaScript code. Fork & adjust to your taste
Node.js Best Practices (Site, MIT) - This is a list of best practices for writing robust Node.js code. It is inspired by other guilds such as Felix Geisendörfer’s Node Style Guide and what is popular within the community
function qualityGuide () { (MIT) - This style guide aims to provide the ground rules for an application’s JavaScript code, such that it’s highly readable and consistent across different developers on a team
The Node Beginner Book (Site, cc-nc-sa) - The Node Beginner Book is a comprehensive introduction to Node.js and some of the more advanced JavaScript topics like functional programming
Understanding ECMAScript 6 (Site, cc-nc-nd) - ECMAScript 6 is coming, are you ready? There’s a lot of new concepts to learn and understand. Get a headstart with this book!
DIY Lisp (BSD) - A hands-on, test driven guide to implementing a simple programming language
Build Your Own Lisp (Site, cc-nc-sa) - Learn C and build your own programming language in under 1000 lines of code!
Objective-C
NYTimes Objective-C Style Guide (MIT) - This style guide outlines the coding conventions of the iOS teams at The New York Times
Ocaml
Real World OCaml (Site, cc-nc-nd) - Real World OCaml is aimed at programmers who have some experience with conventional programming languages, but not specifically with statically typed functional programming
PHP
PHP: The Right Way (Site, by-nc-sa) - An easy-to-read, quick reference for PHP best practices, accepted coding standards, and links to authoritative tutorials around the Web
Dive Into Python 3 (Site, cc-sa) - Dive Into Python is a free Python book for experienced programmers
Explore Flask (Site, Public Domain) - Explore Flask is a book about best practices and patterns for developing web applications with Flask
Full Stack Python (Site, MIT) - Full Stack Python source with Pelican, Bootstrap and Markdown
A Byte of Python (Site, cc-sa) - “A Byte of Python” is a free book on programming using the Python language. It serves as a tutorial or guide to the Python language for a beginner audience
Scala School! (Site, Apache 2.0) - Lessons in the Fundamentals of Scala
Smalltalk
Deep into Pharo (Site, cc-sa) - Deep into Pharo is the second volume of a series of books covering Pharo
Pharo by example (Site, cc-sa) - Pharo by Example, intended for both students and developers, will guide you gently through the Pharo language and environment by means of a series of examples and exercises
Dynamic Web Development with Seaside (Site, cc-nc-sa) - Dynamic Web Development with Seaside, intended for developers, will present the core of Seaside as well as advanced features such as Web 2.0 support and deployment
Squeak by Example (Site, cc-sa) - Squeak by Example, intended for both students and developers, will guide you gently through the Squeak language and environment by means of a series of examples and exercises
GNU Emacs manual (Site, GNU-FDL) - Emacs is the extensible, customizable, self-documenting real-time display editor. This manual describes how to edit with Emacs and some of the ways to customize it
GNU Emacs Lisp Reference Manual (Site, GNU-FDL) - Documentation for Emacs Lisp
Learn Vimscript the Hard Way (Site, custom license) - Learn Vimscript the Hard Way is a book for users of the Vim editor who want to learn how to customize Vim
The Emacs Lisp Style Guide (cc) - This Emacs Lisp style guide recommends best practices so that real-world Emacs Lisp programmers can write code that can be maintained by other real-world Emacs Lisp programmers
A Byte of Vim (Site, cc-sa) - “A Byte of Vim” is a book which aims to help you to learn how to use the Vim editor (version 7), even if all you know is how to use the computer keyboard
Git
Pro Git (Site, cc-nc-sa) - An open source book on Git by Scott Chacon and Ben Straub
A Git Style Guide (cc) - This is a Git Style Guide inspired by How to Get Your Change Into the Linux Kernel, the git man pages and various practices popular among the community.
Git it (Site, BSD) - A workshopper for learning Git and GitHub.
etc.
Gibber User Manual (Site, cc) - Gibber is a creative coding environment that runs in the browser. This book explains why Gibber was created, what its features are and how to use it
Upstart Intro, Cookbook and Best Practises (Site, cc-sa)
점프 투 파이썬 (Site, cc-nc-nd) - 이 책은 파이썬이란 언어를 처음 접해보는 독자들과 프로그래밍을 한 번도 해 본적이 없는 사람들을 대상으로 한다. 프로그래밍을 할 때 사용되는 전문적인 용어들을 알기 쉽게 풀어서 쓰려고 노력하였으며, 파이썬이란 언어의 개별적인 특성만을 강조하지 않고 프로그래밍 전반에 관한 사항을 파이썬이란 언어를 통해 알 수 있도록 알기 쉽게 설명하였다.
Gitbook - A modern publishing toolchain. Simply taking you from ideas to finished, polished books
O’Reilly Open Books - O’Reilly has published a number of Open Books–books with various forms of “open” copyright–over the years. The reasons for “opening” copyright, as well as the specific license agreements under which they are opened, are as varied as our authors
OnlineProgrammingBooks.com - This site lists free eBooks and online books related to programming, computer science, software engineering, web design, mobile app development, networking, databases, information technology, AI, graphics and computer hardware which are provided by publishers or authors on their websites legally
[Efficient Learning Machines: Theories, Concepts, and Applications for Engineers and System Designers] Author : Mariette Awad, Rahul Khanna License: CC-BY
If you’re strong in software engineering, I recommend Machine Learning Mastery with Python by Jason Brownlee as it’s very hands-on in Python and helps you run code to “see” how ML works.
If you’re weak in software engineering and Python, I recommend A Whirlwind Tour Of Python by Jake VanderPlas, and its companion book Python Data Science Handbook.
If you’re strong in architecting / product management, I recommend Building Machine Learning Powered Applications by Emmanuel Ameisen since it explains it more from an SDLC perspective, including things like scoping, design, development, testing, general software engineering best practices, collaboration, etc.
If you’re weak in architecting / product management, I typically recommend User Story Mapping by Jeff Patton and Making Things Happen by Scott Berkun, which are both excellent how-tos with great examples to build on.
If you’re strong in math, I recommend Understanding Machine Learning from Theory to Algorithm by Shalev-Shwartz and Ben-David, as it has all the mathematics for ML and actually has some pseudocode for implementation which helps bridge the gap into actual software development (the book’s title is very accurate!)
For someone who is weak in the math of ML, I recommend Introduction to Statistical Learning by Hastie et al (along with the Python port of the code https://github.com/emredjan/ISL-python ) which I think does just enough hand holding to move someone from “did high school math 20 years ago” to “I understand what these hyperparameters are optimizing for.”
Jadwal dari Bandung 17.00-21.00 WIB, dari Purwokerto 17.00-21.00 WIB
Tiket: 180.000
Xtrans Travel
Kontak Agen: Kantor Pusat Bandung (022- 7316262), Kantor Cabang Shuttle Purwokerto (0281 - 635898)
Jadwal dari Bandung/Purwokerto 08.00, 14.00, dan 20.00 WIB
Pamitran Jaya Travel
Armada: Mitsubishi L300, ELF, ELF Long, Toyota Hiace
Kontak Agen: Bandung (081394480308 dan 081321116168), Purwokerto HP (081394480308 dan 081321116168) (0281)632473 Bandung (022)7316262 Purwokerto +62281632473
Awali dengan membaca pedoman penulisan dan patuhi seluruh pedoman. Untuk Teknik Elektro Unsoed, pedoman yang dipakai adalah podoterus.
Tulis naskah dengan mengaktifkan fitur pemeriksa ejaan (spell checker) bahasa Indonesia pada pengolah kata anda.
Periksa ejaan pada naskah berdasar Pedoman Umum Ejaan Bahasa Indonesia (PUEBI).
Periksa kosakata pada naskah dengan tahapan sebagai berikut.
Jika istilah yang dimaksud terdapat di KBBI, gunakan istilah dalam KBBI.
Jika istilah tersebut tidak ada di KBBI, cari dan gunakan istilah baku berdasarkan dokumen resmi.
Jika istilah baku tidak ada di dalam dokumen resmi atau tidak ada pedomannya, buat penyerapan istilahnya yang tepat.
Jika tidak ditemukan pula istilah dalam bahasa Indonesia yang menyatakan istilah tersebut, silakan tuliskan dengan istilah asing dan dituliskan secara miring. Cantumkan definisi atau maksud dari istilah asing tersebut dalam daftar istilah atau dalam paragraf.
Setiap gambar atau tabel harus dirujuk di dalam paragraf.
Cantumkan setiap sitasi (kutipan, rujukan) yang bersumber dari naskah lain. Cara menuliskan sitasi dengan gaya IEEE adalah seperti contoh berikut.
“Kalimat ini merupakan sitasi dari naskah [12] dan juga bersumber dari rujukan [13].
Teknologi untuk Penulisan Naskah dalam Bahasa Indonesia
Gunakan pengolah kata (word processor) seperti Microsoft Word, Libre Office, atau Google Docs dan maksimalkan semua fitur yang ada. Fitur yang sebaiknya anda kuasai adalah:
Style. Aturstyle seperti normal, heading 1, heading 2, heading 3, caption, dll. Atur penomoran otomatis secara bertingkat (multilevel list) pada heading.
Penomoran daftar. Atur penomoran secara otomatis khususnya dengan metode multilevel list.
Penomoran halaman. Atur penomoran halaman secara otomatis. Gunakan section break untuk mempertahankan urutan penomoran halaman meskipun mengubah format halaman.
Judul tabel dan gambar. Gunakan caption (klik kanan, caption ) untuk melabeli dan menomori tabel dan gambar secara otomatis. Jika diperlukan, atur penomoran tabel dan gambar secara bertingkat dengan memasukkan nomor bab.
Sitasi. Gunakan fitur sitasi (citations and bibliography) yang tersedia pada pengolah kata untuk memasukkan sitasi, mengolah sitasi, dan mengatur sitasi secara otomatis. Untuk menampilkan daftar pustaka dari sitasi secara otomatis, gunakan menu bibliography. Untuk manajemen sitasi lebih lanjut, perangkat lunak sitasi (seperti Zotero dan Mendeley) dapat digunakan.
Daftar isi, daftar tabel, dan daftar gambar. Gunakan fitur table of contents atau table of figures untuk membangkitkan daftar isi, daftar tabel, dan daftar gambar secara otomatis berikut halaman lokasinya.
Referensi silang (cross reference). Gunakan fitur referensi silang untuk mengutip judul gambar dan tabel (caption) secara otomatis.
Perbaruan sitasi, daftar isi, daftar tabel, daftar gambar dan referensi silang. Secara periodik perbarui seluruh referensi (update, pilih semua, klik kanan, update field) untuk menyesuaikan penambahan referensi, perubahan halaman, atau perubahan nomor.
Aktifkan pemeriksa ejaan (spelling checker). Aktifkan fitur pemeriksa ejaan untuk bahasa Indonesia. Mohon diperhatikan bahwa pemeriksa ejaan pada pengolah kata tidak selalu sesuai dengan PUEBI dan KBBI.
Find and Replace. Gunakan fitur find and replace untuk secara cepat memperbaiki kesalahan yang sifatnya massal.
Periksa padanan kata yang tepat dengan menelusuri istilah asingnya pada Wikipedia lalu pada bilah kiri pada menu Languages pilih Bahasa Indonesia untuk mencari padanannya pada bahasa Indonesia.
Kementerian Pendidikan, Kebudayaan, Riset, dan Teknologi
Universitas Jenderal Soedirman
Maksud Naskah
Disusun untuk untuk memenuhi salah satu persyaratan memperoleh gelar Sarjana Teknik pada Program Studi Teknik Elektro, Fakultas Teknik, Universitas Jenderal Soedirman
Diajukan untuk memenuhi salah satu persyaratan memperoleh gelar Sarjana Teknik pada Program Studi Teknik Elektro, Fakultas Teknik, Universitas Jenderal Soedirman
Gaya Penulisan
Gaya Menulis Istilah
Periksa istilah kosakata pada naskah dengan tahapan sebagai berikut.
Jika istilah yang dimaksud terdapat di KBBI, gunakan istilah dalam KBBI.
Jika istilah tersebut tidak ada di KBBI, cari dan gunakan istilah baku berdasarkan dokumen resmi.
Jika istilah baku tidak ada di dalam dokumen resmi atau tidak ada pedomannya, buat penyerapan istilahnya yang tepat.
Jika tidak ditemukan pula istilah dalam bahasa Indonesia yang menyatakan istilah tersebut, silakan tuliskan dengan istilah asing dan dituliskan secara miring.
Cantumkan definisi atau maksud dari istilah dalam suatu paragraf atau dalam daftar istilah.
Tuliskan definisi/maksud istilah saat istilah tersebut pertama kali dituliskan. Selanjutnya definisi/maksud tersebut tak perlu diulang lagi.
Gaya Menulis Naskah
Setiap kalimat harus sempurna (minimal memiliki Subyek dan Predikat).
Paragraf terdiri dari beberapa kalimat. Hindari paragraf hanya dengan satu kalimat.
Setiap paragraf harus memiliki suatu gagasan utama. Gagasan utama dapat diletakkan di awal (deduktif) atau di akhir (induktif) atau awal dan akhir paragraf.
Gaya Menulis Singkatan
Ketika singkatan/akronim sudah diterangkan kepanjangannya pada daftar istilah atau pada paragraf sebelumnya, maka tak perlu diulang kepanjangannya pada paragraf selanjutnya.
Gaya Menulis Gambar/Tabel
Gambar/tabel harus dirujuk dalam naskah dan memiliki posisi sedekat mungkin dengan naskah yang merujuknya.
Nomobr gambar/tabel berurut sesuai dengan urutan perujukannya dalam naskah.
Jika memungkinkan tampilkan gambar/grafik secara berwarna dan jelas dengan resolusi tinggi, jika tidak (hitam putih), pastikan gambar dapat dibedakan dengan jelas dan grafik variabel berbeda memiliki pola yang berbeda.
Usahakan gambar/tabel dalam bentuk landscape.
Pada grafik, semua sumbu harus memiliki label dan (jika ada) satuan.
Pada tabel, semua baris dan kolom membutuhkan judul (header).
Setiap gambar/tabel harus memiliki keterangan (caption)
Gaya Menulis Keterangan (Caption) Gambar/Tabel
Keterangan bersifat deskriptif dan memberikan informasi tambahan terhadap naskah
Ketika menerangkan tabel atau grafik, deskripsikan variabel terkait
Keterangan bersifat singkat dan padat
Kutip sumber dari gambar/tabel jika ada
Keterangan gambar/tabel harus dalam halaman yang sama dengan gambar/tabel-nya
Keterangan dapat berupa judul atau kalimat utuh.
Tips menulis keterangan adalah seperti ketika kita menceritakan ringkas suatu gambar/tabel pada orang lain
Daftar Persiapan Penulisan Naskah
Baca pedoman penulisan.
Pelajari fitur perangkat lunak pengolah kata.
Siapkan dan atur fitur style khususnya heading, normal, dan caption.
Daftar Pemeriksaan Naskah
Periksa penulisan nama dan gelar.
Periksa penulisan nama dan singkatan lembaga dan organisasi.
Periksa penulisan angka dan satuan.
Periksa penulisan huruf kapital dan huruf miring.
Periksa penulisan spasi dalam kalimat dan spasi antar baris.
Periksa penulisan titik (.) dan koma (,).
Periksa penulisan garis miring (/) tanda kurung ((…)) dan kurung siku ([…]).
Periksa penulisan kosakata dan kesesuaiannya dengan KBBI, istilah baku, dan padanan kata.
Periksa nomor halaman dan penulisan nomor dan judul bab, sub-bab, serta caption gambar, dan tabel.
Periksa apakah tabel dan gambar telah dirujuk di dalam naskah (paragraf).
Periksa penulisan sitasi dan daftar pustaka.
Periksa pembuatan daftar pustaka, daftar gambar, dan daftar tabel.
Naskah Laporan Kerja Praktik
Bab 1 : Latar belakang yang mengantarkan kepada judul
konteks (seperti: Indonesia, industri, dll.)
perusahaan (seperti: profil ringkas, kontribusi, dll.)
teknologi (yang menjadi topik laporan kerja praktik)
Bab 2 : Tinjauan perusahaan yang mengantarkan kepada deskripsi divisi/bagian lokasi kegiatan kerja praktik
tinjauan historis
tinjauan manajemen
tinjauan produk
deskripsi divisi/bagian
Bab 3 : Tinjauan pustaka secara generik (tidak spesifik lokasi kegiatan) yang relevan dengan topik laporan
Bab 4 : Pembahasan yang mendeskripsikan topik teknologi dan aktivitas kerja praktik
pembahasan sistem (dari makro ke mikro)
pembahasan teknologi
perangkat keras (piranti) (dari makro ke mikro)
perangkat lunak (dari back-end ke front-end)
metode (prosedur) (dari tahap ke tahap)
pembahasan aktivitas
Bab 5 : Kesimpulan yang menyimpulkan teknologi dan aktivitas kerja praktik, serta saran penulis untuk perbaikan sistem/teknologi pada perusahaan atau mekanisme kerja praktik
5.3 - Pedomaan Ejaan Naskah Bidang Teknik Elektro
Pedomaan Ejaan Naskah Bidang Teknik Elektro
Pedoman ejaan untuk naskah bidang teknik elektro berdasarkan PUEBI. Pedoman ejaan berikut tidak menyebutkan pedoman ejaan selengkap PUEBI, akan tetapi hanya menyebutkan sebagian yang terkait dengan penulisan naskah bidang teknik elektro. Apa yang disebutkan berikut dituliskan berdasarkan pengalaman membimbing penulisan naskah bidang teknik elektro.
Berikut adalah ringkasan ejaan yang benar dan yang salah berdasarkan PUEBI. Sebagai ringkasan, konteks ejaan tidak disampaikan secara lengkap. Untuk memahami pedoman ejaan yang lebih lengkap silakan lanjutkan baca pada sub-bab berikutnya, atau silakan merujuk kepada:
✅ abad XX, ✅ abad ke-20, ✅ abad kedua puluh, ❌ abad ke-XX, ❌ abad ke 20, ❌ abad ke-dua puluh
✅ machine learning (ML), ✅ artificial intelligence (AI), ✅ internet of things (IoT), ✅ convolutional neural network (CNN), ❌ Machine Learning (ML), ❌ Artificial Intelligence (AI), ❌ Internet of Things (IoT), Convolutional Neural Network (CNN)
✅ memiliki surat izin mengemudi (SIM), ✅ memiliki KTP (kartu tanda penduduk), ❌ memiliki Surat Izin Mengemudi (SIM).
✅ Cable News Network (CNN), ✅ Institute of Electrical and Electronics Engineers (IEEE),❌Cable News Network (CNN), ❌ institute of electrical and electronics engineers (IEEE)
✅ tentang radar (radio detection and ranging) dan lidar (light detection and ranging), ❌ tentang radar(radio detection and ranging) dan lidar(light detection and ranging)
✅ Tahun 2010—2013, ✅ Tanggal 5—10 April 2013, ✅ Jakarta—Bandung, ❌ Tahun 2010 - 2013, ❌ Tanggal 5- 10 April 2013, ❌ Jakarta - Bandung
Huruf kapital dipakai sebagai huruf pertama unsur nama orang.
Misalnya:
André-Marie Ampère
Rudolf Diesel
Georg Ohm
Tetapi kapital tidak dipakai ketika menjadi nama orang menjadi nama jenis atau satuan ukuran. Misalnya:
5 ampere
mesin diesel
10 ohm
Huruf kapital dipakai jika satuan ukuran itu disingkat. Misalnya:
5 A
10 V
Huruf kapital dipakai sebagai huruf pertama unsur nama gelar kehormatan, akademik, atau jabatan yang diikuti nama orang, atau jabatan suatu institusi.
Misalnya:
Profesor Suroso
Presiden Joko Widodo
Presiden Indonesia
Direktur IEEE
Tetapi tidak dipakai ketika tidak diikuti nama orang. Misalnya:
para profesor
dua orang direktur
Huruf kapital dipakai sebagai huruf pertama nama bangsa, bahasa, bulan, hari, nama geografi, dan nama peristiwa sejarah
Misalnya:
hari Jumat
bangsa Indonesia
negara Inggris
Perang Dunia II
Danau Toba
Jalan Sungkono
Tetapi tidak kapital ketika menjadi kata turunan atau tidak menjadi kata nama diri. Misalnya:
pengindonesiaan
kejawa-jawaan
jangan sampai terjadi perang dunia
jeruk bali
gula jawa
Huruf pertama setiap kata dalam judul skripsi, judul artikel, nama lembaga, nama organisasi, dan nama dokumen ditulis dengan kapital kecuali kata tugas di, ke, dari, dan, yang, tentang, dan untuk, yang tidak terletak pada posisi awal.
Misalnya:
Pengenalan Isyarat Tangan Sistem Isyarat Bahasa Indonesia (SIBI) dengan Algoritme YOLO
Undang-Undang Dasar Republik Indonesia
Universitas Jenderal Soedirman di Purwokerto
Huruf kapital dipakai sebagai huruf pertama unsur singkatan nama gelar, pangkat, atau sapaan
Huruf miring dipakai untuk menuliskan kata atau ungkapan dalam bahasa daerah atau bahasa asing.
Misalnya:
Klasifikasi wajah dilakukan dengan algoritme convolutional neural network (CNN) yang merupakan bagian dari algoritme deep learning
Merancang alat untuk mendeteksi kematangan buah manggis (Garcinia mangostana).
Tetapi nama diri, seperti nama orang, lembaga, atau organisasi, dalam bahasa asing atau bahasa daerah tidak ditulis dengan huruf miring. Misalnya:
Lembaga penyiaran Cable News Network (CNN) menyiarkan kegiatan Direktur Institute of Electrical and Electronics Engineers (IEEE) Stephen Welby yang menyampaikan perkembangan teknologi convolutional neural network (CNN).
Singkatan nama orang, gelar, sapaan, jabatan, atau pangkat diikuti dengan tanda titik pada setiap unsur singkatan itu.
Misalnya:
S.T. = Sarjana Teknik
M.T. = Magister Teknik
Ph.D. = Philosophy Doctor
Sehingga penulisan singkatan berikut adalah salah:
ST
M. Si
PhD.
Singkatan yang terdiri atas huruf awal setiap kata yang bukan nama diri ditulis dengan huruf kapital tanpa tanda titik.
Misalnya:
PT = Perseroan Terbatas
KTP = Kartu Tanda Penduduk
NIP = Nomor Induk Pegawai
NIM = Nomor Induk Mahasiswa
AI = Artificial Intelligence
Sehingga penulisan singkatan berikut adalah salah:
P.T. atau PT.
NIP. atau N.I.P atau NIP:
Tetapi jika bukan nama diri tidak dituliskan dengan kapital di awal katanya. Misalnya:
Perseroan terbatas (PT) memiliki modal dari saham-saham.
Penelitian tentang artificial intelligence (AI) sekarang semakin populer.
Singkatan yang terdiri atas tiga huruf atau lebih (yang bukan huruf awal setiap kata) diikuti dengan tanda titik.
Misalnya:
sdr. = saudara
dll. = dan lain lain
Jika di akhir kalimat, cukup menggunakan satu titik.
Komponen yang dipakai adalah transistor, resistor, dll.
Singkatan yang terdiri atas dua huruf yang lazim dipakai dalam surat-menyurat masing-masing diikuti oleh tanda titik.
Misalnya:
a.n. = atas nama
s.d. = sampai dengan
Singkatan yang terdiri atas huruf awal setiap kata nama lembaga, organisasi, dan nama dokumen resmi termasuk yang berasal dari bahasa asing ditulis dengan huruf kapital tanpa tanda titik.
Misalnya:
IEEE = Institute of Electrical and Electronics Engineers
BPPT = Badan Pengkajian dan Penerapan Teknologi
FT = Fakultas Teknik
UI = Universitas Indonesia
Lambang kimia, singkatan satuan ukuran, takaran, timbangan, dan mata uang tidak diikuti tanda titik.
Misalnya:
Cu = kuprum
5 cm = sentimeter
10 kVA = kilovolt-ampere (VA ditulis dengan kapital karena singkatan dari nama orang)
3 kg = kilogram
Rp1.000 (singkatan mata uang dituliskan tanpa titik dan bersambung dengan nilainya)
US$100
Sehingga penulisan berikut adalah salah:
5 Km
Rp. 200.000
Akronim nama diri yang terdiri atas huruf awal setiap kata ditulis dengan huruf kapital tanpa tanda titik.
Misalnya:
LIPI = Lembaga Ilmu Pengetahuan Indonesia
Akronim nama diri yang berupa gabungan suku kata atau gabungan huruf dan suku kata dari deret kata ditulis dengan huruf awal kapital.
Misalnya:
Unsoed = Universitas Jenderal Soedirman
Bappenas = Badan Perencanaan Pembangunan Nasional
Faperta = Fakultas Pertanian
Akronim bukan nama diri yang berupa gabungan huruf awal dan suku kata atau gabungan suku kata ditulis dengan huruf kecil.
Tanda titik dipakai di belakang angka atau huruf dalam suatu bagan, ikhtisar, atau daftar.
Misalnya:
I. Pendahuluan
Metode Penelitian
Tetapi tanda titik tidak dipakai pada akhir penomoran digital yang lebih dari satu angka. Misalnya:
Pendahuluan
1.1 Latar Belakang
1.2.1 Rumusan Masalah
III.A.2.b Langkah Penelitian
Tetapi tanda titik tidak dipakai di belakang angka atau angka terakhir dalam penomoran dalam judul tabel, atau gambar. Misalnya:
Tabel 1 Nilai Resistansi pada Komponen
Gambar 2.2 Diagram Topologi Mesh pada Sistem Internet of Things
Bab 1 Pendahuluan
Tanda titik dipakai untuk memisahkan angka jam, menit, dan detik yang menunjukkan waktu atau jangka waktu.
Misalnya:
Proses tersebut berjalan sampai pukul 01.35.20 (pukul 1 lewat 35 menit 20 detik atau pukul 1, 35 menit, 20 detik)
Proses tersebut berjalan selama 01.35.20 jam (1 jam, 35 menit, 20 detik)
Sehingga penulisan waktu dan jangka waktu berikut adalah salah:
Pukul 12:30
Tanda titik dipakai untuk memisahkan bilangan ribuan atau kelipatannya yang menunjukkan jumlah.
Misalnya:
Hambatan pada resistor tersebut adalah sebesar 13.000 ohm
Sehingga perlu berhati-hati ketika memindahkan bilangan yang berasal dari bahasa Inggris yang menggunakan koma (,) sebagai pemisah bilangan ribuan atau kelipatannya.
Tetapi tanda titik tidak dipakai untuk memisahkan bilangan ribuan atau kelipatannya yang tidak menunjukkan jumlah. Misalnya:
Hal ini merujuk kepada Handbook of Electrical Engineering halaman 1305 yang terbit pada tahun 2019.
Tanda koma dipakai di antara unsur-unsur dalam suatu pemerincian atau pembilangan.
Misalnya:
Komponen pasif dalam elektronika adalah resistor, kapasitor, dan induktor.
Tanda koma dipakai sebelum kata penghubung, seperti tetapi, melainkan, dan sedangkan, dalam kalimat majemuk (setara).
Misalnya:
Pengujian melalui simulasi pada perangkat lunak berhasil, tetapi pengujian pada perangkat keras gagal.
Tanda koma dipakai untuk memisahkan anak kalimat yang mendahului induk kalimatnya.
Misalnya:
Apabila diperlukan, pengujian dapat dilakukan hingga lima kali.
Tetapi tanda koma tidak dipakai jika induk kalimat mendahului anak kalimat. Misalnya:
Pengujian dapat dilakukan hingga lima kali apabila diperlukan.
Tanda koma dipakai di belakang kata atau ungkapan penghubung antarkalimat, seperti oleh karena itu, jadi, dengan demikian, sehubungan dengan itu, dan meskipun demikian.
Misalnya:
Pengujian yang kami lakukan dengan teknik tersebut gagal. Oleh karena itu, kami mencoba menggunakan teknik yang lain.
Tanda koma dipakai di antara nama orang dan singkatan gelar akademis yang mengikutinya.
Misalnya:
Eko Murdyantoro, M.A. menyandang gelar Master of Art dari UGM.
Tetapi tidak dipakai untuk singkatan nama diri, keluarga, atau marga.
Eko Murdyantoro M.A. memiliki nama lengkap Eko Murdyantoro Mangku Atmojo.
Tanda koma dipakai sebelum angka desimal atau di antara rupiah dan sen yang dinyatakan dengan angka.
Misalnya:
12,5 m
Rp750,00
Tanda koma dipakai untuk mengapit keterangan tambahan atau keterangan aposisi.
Misalnya:
Semua mahasiswa FT Unsoed, baik Teknik Elektro maupun Teknik Sipil, harus mengikuti upacara penerimaan mahasiswa baru.
Tanda koma dapat dipakai di belakang keterangan yang terdapat pada awal kalimat untuk menghindari salah baca/salah pengertian.
Misalnya:
Dalam pengukuran nilai daya, kita harus memperhatikan posisi kabel powermeter.
Bandingkan dengan,
Dalam pengukuran nilai daya kita harus memperhatikan posisi kabel powermeter.
Tanda titik koma dapat dipakai sebagai pengganti kata penghubung untuk memisahkan kalimat setara yang satu dari kalimat setara yang lain di dalam kalimat majemuk.
Misalnya:
Pengukuran secara otomatis gagal; pengukuran manual pun gagal.
Tanda titik koma dipakai pada akhir perincian yang berupa klausa.
Misalnya:
Syarat penerimaan pegawai di PT PLN adalah
- (1) berkewarganegaraan Indonesia;
- (2) berijazah sarjana S-1 Teknik Elektro;
- (3) berbadan sehat; dan
- (4) bersedia ditempatkan di seluruh wilayah Negara Kesatuan Republik Indonesia.
Ini Paijo. Paijo ingin membeli mobil. Paijo mencoba menghitung berapa rupiah yang harusi dia tabung per bulan untuk bisa membeli mobil. Paijo lalu bertanya kepada temannya, juga mencari informasi di internet: ternyata harga mobil baru berkisar Rp.200 juta, kalau mobil second usia setahunan jatuh di Rp.190 juta, yang usia dua tahunan jatuh di Rp.180 juta dan seterusnya.
Paijo, sang calon pemilik mobil yang cerdas ini, menemukan polanya: jadi, harga mobil itu tergantung dari usianya, dan diperkirakan turun Rp.10 juta per tahun. Tetapi harganya tak akan lebih rendah dari Rp.100 juta.
Dalam istilah pembelajara mesin, Paijo menemukan apa yang disebut regresi – bahwa dia bisa memperkirakan sebuah nilai (harga) berdasarkan data yang diketahui. Banyak orang yang terbiasa melakukan ini, misalnya saat membeli smartphone bekas (second), atau saat belanja beras untuk kepentingan kenduri (apakah per orang dijatah satu atau dua ons beras?).
Seandainya saja kita punya rumus sederhana untuk setiap hal di dunia tentu saja semua akan terasa mudah. Kita tak perlu pusing memperkirakan, atau bertanya, atau menawar. Tetapi sayangnya, hal tersebut tak mungkin.
Kembali ke urusan mobil yang mau dibeli Paijo. Masalahnya adalah saat membeli mobil, Paijo (dan kita juga) akan berhadapan dengan berbagai ragam perincian yang menentukan harga mobil: bulan dan tahun produksi, ragam variasi interior dan eksterior, kondisi mobil, jumlah kilometer, waktu pembelian (karena saat mendekati lebaran biasanya harga naik), dan lain sebagainya. Pada umumnya, kita dan Paijo tak mungkin mengingat dan memperhitungkan semua faktor harga tadi untuk menentukan tawaran harga mobil yang akan diajukan.
Nah karena kita manusia itu malas dan bodoh - apalaig urusannya matematika -, maka kita butuh mesin atau robot untuk membantu kita memperhitungkan harga buat kita, entah harga mobil, harga tanah, atau harga saham. Jadi, kita perkerjakan mesin untuk menghitung itu semua atau bahkan memperkirakan harganya. Maka, kita sediakan sejumlah data kepada si mesin, lalu meminta si mesin untuk mencari pola yang terkait dan menentukan harga sesuatu.
Dan, ternyata bisa. Hal yang paling menyenangkan adalah ternyata terbukti mesin bisa bekerja menghitung dan memperkirakan secara lebih baik daripada kebanyakan orang.
Itulah yang menjadi asal muasal lahirnya pembelajaran mesin (machine learning).
Tiga Komponen Pembelajaran Mesin
Tujuan sebenarnya dari pembelajaran mesin adalah untuk memprediksi hasil berdasarkan data yang disediakan. Semua pekerjaan pembelajaran mesin harus dapat dinyatakan dengan cara seperti ini. Kalau tidak seperti itu berarti sejak awal itu bukan merupakan pekerjaan dari pembelajaran mesin.
Semakin banyak variasi dari sampel yang kita punya, maka akan menjadi lebih mudah bagi mesin untuk mencari pola yang relevan dan memperkirakan hasilnya. Oleh karena itu, kita membutuhkan 3 komponen untuk mengajar mesin untuk bisa belajar.
Data
Kita ingin mesin mendeteksi spam? Maka carilah pesan atau email yang berisi spam. Kita ingin mesin bisa meramalkan harga saham? Maka carilah data harga saham sebanyak-banyaknya. Kita ingin mencari pola pengguna internet? Maka kumpulkan data aktivitas mereka di Facebook (eh Mark Zuckerberg, jangan terus mengumpulkan data kita terus dong!). Semakin banyak variasi dari data kita maka semakin baik hasil peramalannya. Sebagai patokan, puluhan ribu baris data adalah syarat minimum bagi yang menginginkan peramalan yang baik.
Maka ada dua cara utama untuk mendapatkan data: manual dan otomatis. Data yang dikumpulkan secara manual akan memiliki kesalahan yang lebih sedikit akan tetapi akan membutuhkan waktu yang lebih banyak untuk mengumpulkannya sehingga membuat biayanya secara umum lebih mahal.
Pengumpulan data secara otomatis itu secara umum lebih murah, yaitu kita cukup mengumpulkan segala apapun yang kamu dapat kita temukan dan berharap itu data yang kita kumpulkan itu adalah yang terbaik.
Orang pintar seperti misalnya yang bekerja di Google bisa memberdayakan konsumen mereka sendiri untuk memberikan label data bagi mereka secara gratis. Anda ingat ‘ReCaptcha’? Itu loh yang kadang memaksa kita untuk memilih mana gambar lampu lalu lintas, mana gambar mobil dll.? Nah, itulah adalah yang mereka lakukan pada kita. Kita menjadi buruh yang gratis! Keren kan?
Pada dasarnya untuk mengumpulkan data yang bagus (biasanya disebut sebagai dataset) itu sangat sulit. Maka mudah kita pahami, mengapa kita lebih banyak menemukan algoritme atau kode program untuk pembelajaran mesin, tetapi jarang menemukan dataset-nya..
Fitur
Atau dikenal juga dengan istilah parameter atau variabel. Fitur dapat berbentuk jenis kelamin pengguna, harga saham, atau frekuensi kata di dalam sebuah teks. Dengan kata lain, fitur adalah faktor-faktor yang perlu dilihat dan diperhatikan oleh mesin.
Saat data disimpan dalam tabel, fitur dapat dengan mudah diletakkan sebagai nama kolom. Akan tetapi, bagaimana jika kita memiliki koleksi dataset gambar kucing sebesar 100 GB? Kita tidak dapat secara sembrono menggunakan setiap pixel sebagai sebuah fitur. Itu mengapa memilih fitur yang tepat biasanya membutuhkan waktu yang lebih panjang daripada semua waktu yang dibutuhkan dalam berbagai tahapan dari pembelajaran mesin. Hal tersebut juga merupakan sumber kesalahan yang paling utama. Manusia itu selalu subjektif, mereka memilih fitur-fitur yang mereka sukai atau yang mereka anggap penting.
Algoritme
Ini adalah bagian yang paling jelas. Setiap masalah dapat diselesaikan dengan cara yang berbeda. Metode yang kita pilih akan berdampak kepada presisi, unjuk kerja, dan ukuran dari model (algoritme) yang akhirnya kita pakai. Akan tetapi ada ada hal yang penting untuk diperhatikan: jika data kita itu jelek, maka algoritme yang terbaik sekalipun tidak akan menolong. Hal itu disebut sebagai “sampah yang masuk - sampah yang keluar” (garbage in - garbage out). Jadi jangan terlalu memberikan perhatian yang yang terlalu besar kepada persentase akurasi, akan tetapi usahakan untuk mendapatkan data yang lebih banyak terlebih dahulu.
Once I saw an article titled “Will neural networks replace machine learning?” on some hipster media website. These media guys always call any shitty linear regression at least artificial intelligence, almost SkyNet. Here is a simple picture to show who is who.
Artificial intelligence is the name of a whole knowledge field, similar to biology or chemistry.
Machine Learning is a part of artificial intelligence. An important part, but not the only one.
Neural Networks are one of machine learning types. A popular one, but there are other good guys in the class.
Deep Learning is a modern method of building, training, and using neural networks. Basically, it’s a new architecture. Nowadays in practice, no one separates deep learning from the “ordinary networks”. We even use the same libraries for them. To not look like a dumbass, it’s better just name the type of network and avoid buzzwords.
The general rule is to compare things on the same level. That’s why the phrase “will neural nets replace machine learning” sounds like “will the wheels replace cars”. Dear media, it’s compromising your reputation a lot.
Machine can
Machine cannot
Forecast
Create something new
Memorize
Get smart really fast
Reproduce
Go beyond their task
Choose best item
Kill all humans
If you are too lazy for long reads, take a look at the picture below to get some understanding.
Always important to remember — there is never a sole way to solve a problem in the machine learning world. There are always several algorithms that fit, and you have to choose which one fits better. Everything can be solved with a neural network, of course, but who will pay for all these GeForces?
Let’s start with a basic overview. Nowadays there are four main directions in machine learning.
The first methods came from pure statistics in the ’50s. They solved formal math tasks — searching for patterns in numbers, evaluating the proximity of data points, and calculating vectors’ directions.
Nowadays, half of the Internet is working on these algorithms. When you see a list of articles to “read next” or your bank blocks your card at random gas station in the middle of nowhere, most likely it’s the work of one of those little guys.
Big tech companies are huge fans of neural networks. Obviously. For them, 2% accuracy is an additional 2 billion in revenue. But when you are small, it doesn’t make sense. I heard stories of the teams spending a year on a new recommendation algorithm for their e-commerce website, before discovering that 99% of traffic came from search engines. Their algorithms were useless. Most users didn’t even open the main page.
Despite the popularity, classical approaches are so natural that you could easily explain them to a toddler. They are like basic arithmetic — we use it every day, without even thinking.
Classical machine learning is often divided into two categories – Supervised and Unsupervised Learning.
In the first case, the machine has a “supervisor” or a “teacher” who gives the machine all the answers, like whether it’s a cat in the picture or a dog. The teacher has already divided (labeled) the data into cats and dogs, and the machine is using these examples to learn. One by one. Dog by cat.
Unsupervised learning means the machine is left on its own with a pile of animal photos and a task to find out who’s who. Data is not labeled, there’s no teacher, the machine is trying to find any patterns on its own. We’ll talk about these methods below.
Clearly, the machine will learn faster with a teacher, so it’s more commonly used in real-life tasks. There are two types of such tasks: classification – an object’s category prediction, and regression – prediction of a specific point on a numeric axis.
“Splits objects based at one of the attributes known beforehand. Separate socks by based on color, documents based on language, music by genre”
Today used for:
– Spam filtering
– Language detection
– A search of similar documents
– Sentiment analysis
– Recognition of handwritten characters and numbers
– Fraud detection
From here onward you can comment with additional information for these sections. Feel free to write your examples of tasks. Everything is written here based on my own subjective experience.
Machine learning is about classifying things, mostly. The machine here is like a baby learning to sort toys: here’s a robot, here’s a car, here’s a robo-car… Oh, wait. Error! Error!
In classification, you always need a teacher. The data should be labeled with features so the machine could assign the classes based on them. Everything could be classified — users based on interests (as algorithmic feeds do), articles based on language and topic (that’s important for search engines), music based on genre (Spotify playlists), and even your emails.
In spam filtering the Naive Bayes algorithm was widely used. The machine counts the number of “viagra” mentions in spam and normal mail, then it multiplies both probabilities using the Bayes equation, sums the results and yay, we have Machine Learning.
Later, spammers learned how to deal with Bayesian filters by adding lots of “good” words at the end of the email. Ironically, the method was called Bayesian poisoning. Naive Bayes went down in history as the most elegant and first practically useful one, but now other algorithms are used for spam filtering.
Here’s another practical example of classification. Let’s say you need some money on credit. How will the bank know if you’ll pay it back or not? There’s no way to know for sure. But the bank has lots of profiles of people who took money before. They have data about age, education, occupation and salary and – most importantly – the fact of paying the money back. Or not.
Using this data, we can teach the machine to find the patterns and get the answer. There’s no issue with getting an answer. The issue is that the bank can’t blindly trust the machine answer. What if there’s a system failure, hacker attack or a quick fix from a drunk senior.
To deal with it, we have Decision Trees. All the data automatically divided to yes/no questions. They could sound a bit weird from a human perspective, e.g., whether the creditor earns more than $128.12? Though, the machine comes up with such questions to split the data best at each step.
That’s how a tree is made. The higher the branch — the broader the question. Any analyst can take it and explain afterward. He may not understand it, but explain easily! (typical analyst)
Decision trees are widely used in high responsibility spheres: diagnostics, medicine, and finances.
The two most popular algorithms for forming the trees are CART and C4.5.
Pure decision trees are rarely used today. However, they often set the basis for large systems, and their ensembles even work better than neural networks. We’ll talk about that later.
When you google something, that’s precisely the bunch of dumb trees which are looking for a range of answers for you. Search engines love them because they’re fast.
Support Vector Machines (SVM) is rightfully the most popular method of classical classification. It was used to classify everything in existence: plants by appearance in photos, documents by categories, etc.
The idea behind SVM is simple – it’s trying to draw two lines between your data points with the largest margin between them. Look at the picture:
There’s one very useful side of the classification — anomaly detection. When a feature does not fit any of the classes, we highlight it. Now that’s used in medicine — on MRIs, computers highlight all the suspicious areas or deviations of the test. Stock markets use it to detect abnormal behaviour of traders to find the insiders. When teaching the computer the right things, we automatically teach it what things are wrong.
Today, neural networks are more frequently used for classification. Well, that’s what they were created for.
The rule of thumb is the more complex the data, the more complex the algorithm. For text, numbers, and tables, I’d choose the classical approach. The models are smaller there, they learn faster and work more clearly. For pictures, video and all other complicated big data things, I’d definitely look at neural networks.
Just five years ago you could find a face classifier built on SVM. Today it’s easier to choose from hundreds of pre-trained networks. Nothing has changed for spam filters, though. They are still written with SVM. And there’s no good reason to switch from it anywhere.
Even my website has SVM-based spam detection in comments ¯_(ツ)_/¯
“Draw a line through these dots. Yep, that’s the machine learning”
Regression is basically classification where we forecast a number instead of category. Examples are car price by its mileage, traffic by time of the day, demand volume by growth of the company etc. Regression is perfect when something depends on time.
Everyone who works with finance and analysis loves regression. It’s even built-in to Excel. And it’s super smooth inside — the machine simply tries to draw a line that indicates average correlation. Though, unlike a person with a pen and a whiteboard, machine does so with mathematical accuracy, calculating the average interval to every dot.
When the line is straight — it’s a linear regression, when it’s curved – polynomial. These are two major types of regression. The other ones are more exotic. Logistic regression is a black sheep in the flock. Don’t let it trick you, as it’s a classification method, not regression.
It’s okay to mess with regression and classification, though. Many classifiers turn into regression after some tuning. We can not only define the class of the object but memorize how close it is. Here comes a regression.
If you want to get deeper into this, check these series: Machine Learning for Humans. I really love and recommend it!
Unsupervised was invented a bit later, in the ’90s. It is used less often, but sometimes we simply have no choice.
Labeled data is luxury. But what if I want to create, let’s say, a bus classifier? Should I manually take photos of million fucking buses on the streets and label each of them? No way, that will take a lifetime, and I still have so many games not played on my Steam account.
There’s a little hope for capitalism in this case. Thanks to social stratification, we have millions of cheap workers and services like Mechanical Turk who are ready to complete your task for $0.05. And that’s how things usually get done here.
Or you can try to use unsupervised learning. But I can’t remember any good practical application for it, though. It’s usually useful for exploratory data analysis but not as the main algorithm. Specially trained meatbag with Oxford degree feeds the machine with a ton of garbage and watches it. Are there any clusters? No. Any visible relations? No. Well, continue then. You wanted to work in data science, right?
“Divides objects based on unknown features. Machine chooses the best way”
Nowadays used:
For market segmentation (types of customers, loyalty)
Clustering is a classification with no predefined classes. It’s like dividing socks by color when you don’t remember all the colors you have. Clustering algorithm trying to find similar (by some features) objects and merge them in a cluster. Those who have lots of similar features are joined in one class. With some algorithms, you even can specify the exact number of clusters you want.
An excellent example of clustering — markers on web maps. When you’re looking for all vegan restaurants around, the clustering engine groups them to blobs with a number. Otherwise, your browser would freeze, trying to draw all three million vegan restaurants in that hipster downtown.
Apple Photos and Google Photos use more complex clustering. They’re looking for faces in photos to create albums of your friends. The app doesn’t know how many friends you have and how they look, but it’s trying to find the common facial features. Typical clustering.
Another popular issue is image compression. When saving the image to PNG you can set the palette, let’s say, to 32 colors. It means clustering will find all the “reddish” pixels, calculate the “average red” and set it for all the red pixels. Fewer colors — lower file size — profit!
However, you may have problems with colors like Cyan◼︎-like colors. Is it green or blue? Here comes the K-Means algorithm.
It randomly sets 32 color dots in the palette. Now, those are centroids. The remaining points are marked as assigned to the nearest centroid. Thus, we get kind of galaxies around these 32 colors. Then we’re moving the centroid to the center of its galaxy and repeat that until centroids stop moving.
All done. Clusters defined, stable, and there are exactly 32 of them. Here is a more real-world explanation:
Searching for the centroids is convenient. Though, in real life clusters not always circles. Let’s imagine you’re a geologist. And you need to find some similar minerals on the map. In that case, the clusters can be weirdly shaped and even nested. Also, you don’t even know how many of them to expect. 10? 100?
K-means does not fit here, but DBSCAN can be helpful. Let’s say, our dots are people at the town square. Find any three people standing close to each other and ask them to hold hands. Then, tell them to start grabbing hands of those neighbors they can reach. And so on, and so on until no one else can take anyone’s hand. That’s our first cluster. Repeat the process until everyone is clustered. Done.
A nice bonus: a person who has no one to hold hands with — is an anomaly.
It all looks cool in motion:
Just like classification, clustering could be used to detect anomalies. User behaves abnormally after signing up? Let the machine ban him temporarily and create a ticket for the support to check it. Maybe it’s a bot. We don’t even need to know what “normal behavior” is, we just upload all user actions to our model and let the machine decide if it’s a “typical” user or not.
This approach doesn’t work that well compared to the classification one, but it never hurts to try.
“Assembles specific features into more high-level ones”
Previously these methods were used by hardcore data scientists, who had to find “something interesting” in huge piles of numbers. When Excel charts didn’t help, they forced machines to do the pattern-finding. That’s how they got Dimension Reduction or Feature Learning methods.
Projecting 2D-data to a line (PCA)
It is always more convenient for people to use abstractions, not a bunch of fragmented features. For example, we can merge all dogs with triangle ears, long noses, and big tails to a nice abstraction — “shepherd”. Yes, we’re losing some information about the specific shepherds, but the new abstraction is much more useful for naming and explaining purposes. As a bonus, such “abstracted” models learn faster, overfit less and use a lower number of features.
These algorithms became an amazing tool for Topic Modeling. We can abstract from specific words to their meanings. This is what Latent semantic analysis (LSA) does. It is based on how frequently you see the word on the exact topic. Like, there are more tech terms in tech articles, for sure. The names of politicians are mostly found in political news, etc.
Yes, we can just make clusters from all the words at the articles, but we will lose all the important connections (for example the same meaning of battery and accumulator in different documents). LSA will handle it properly, that’s why its called “latent semantic”.
So we need to connect the words and documents into one feature to keep these latent connections — it turns out that Singular decomposition (SVD) nails this task, revealing useful topic clusters from seen-together words.
Recommender Systems and Collaborative Filtering is another super-popular use of the dimensionality reduction method. Seems like if you use it to abstract user ratings, you get a great system to recommend movies, music, games and whatever you want.
It’s barely possible to fully understand this machine abstraction, but it’s possible to see some correlations on a closer look. Some of them correlate with user’s age — kids play Minecraft and watch cartoons more; others correlate with movie genre or user hobbies.
Machines get these high-level concepts even without understanding them, based only on knowledge of user ratings. Nicely done, Mr.Computer. Now we can write a thesis on why bearded lumberjacks love My Little Pony.
This includes all the methods to analyze shopping carts, automate marketing strategy, and other event-related tasks. When you have a sequence of something and want to find patterns in it — try these thingys.
Say, a customer takes a six-pack of beers and goes to the checkout. Should we place peanuts on the way? How often do people buy them together? Yes, it probably works for beer and peanuts, but what other sequences can we predict? Can a small change in the arrangement of goods lead to a significant increase in profits?
Same goes for e-commerce. The task is even more interesting there — what is the customer going to buy next time?
No idea why rule-learning seems to be the least elaborated upon category of machine learning. Classical methods are based on a head-on look through all the bought goods using trees or sets. Algorithms can only search for patterns, but cannot generalize or reproduce those on new examples.
In the real world, every big retailer builds their own proprietary solution, so nooo revolutions here for you. The highest level of tech here — recommender systems. Though, I may be not aware of a breakthrough in the area. Let me know in the comments if you have something to share.
“Throw a robot into a maze and let it find an exit”
Finally, we get to something looks like real artificial intelligence. In lots of articles reinforcement learning is placed somewhere in between of supervised and unsupervised learning. They have nothing in common! Is this because of the name?
Reinforcement learning is used in cases when your problem is not related to data at all, but you have an environment to live in. Like a video game world or a city for self-driving car.
Neural network plays Mario
Knowledge of all the road rules in the world will not teach the autopilot how to drive on the roads. Regardless of how much data we collect, we still can’t foresee all the possible situations. This is why its goal is to minimize error, not to predict all the moves.
Surviving in an environment is a core idea of reinforcement learning. Throw poor little robot into real life, punish it for errors and reward it for right deeds. Same way we teach our kids, right?
More effective way here — to build a virtual city and let self-driving car to learn all its tricks there first. That’s exactly how we train auto-pilots right now. Create a virtual city based on a real map, populate with pedestrians and let the car learn to kill as few people as possible. When the robot is reasonably confident in this artificial GTA, it’s freed to test in the real streets. Fun!
There may be two different approaches — Model-Based and Model-Free.
Model-Based means that car needs to memorize a map or its parts. That’s a pretty outdated approach since it’s impossible for the poor self-driving car to memorize the whole planet.
In Model-Free learning, the car doesn’t memorize every movement but tries to generalize situations and act rationally while obtaining a maximum reward.
Remember the news about AI beating a top player at the game of Go? Despite shortly before this it being proved that the number of combinations in this game is greater than the number of atoms in the universe.
This means the machine could not remember all the combinations and thereby win Go (as it did chess). At each turn, it simply chose the best move for each situation, and it did well enough to outplay a human meatbag.
This approach is a core concept behind Q-learning and its derivatives (SARSA & DQN). ‘Q’ in the name stands for “Quality” as a robot learns to perform the most “qualitative” action in each situation and all the situations are memorized as a simple markovian process.
Such a machine can test billions of situations in a virtual environment, remembering which solutions led to greater reward. But how can it distinguish previously seen situations from a completely new one? If a self-driving car is at a road crossing and the traffic light turns green — does it mean it can go now? What if there’s an ambulance rushing through a street nearby?
The answer today is “no one knows”. There’s no easy answer. Researchers are constantly searching for it but meanwhile only finding workarounds. Some would hardcode all the situations manually that let them solve exceptional cases, like the trolley problem. Others would go deep and let neural networks do the job of figuring it out. This led us to the evolution of Q-learning called Deep Q-Network (DQN). But they are not a silver bullet either.
Reinforcement Learning for an average person would look like a real artificial intelligence. Because it makes you think wow, this machine is making decisions in real life situations! This topic is hyped right now, it’s advancing with incredible pace and intersecting with a neural network to clean your floor more accurately. Amazing world of technologies!
Off-topic. When I was a student, genetic algorithms (link has cool visualization) were really popular. This is about throwing a bunch of robots into a single environment and making them try reaching the goal until they die. Then we pick the best ones, cross them, mutate some genes and rerun the simulation. After a few milliard years, we will get an intelligent creature. Probably. Evolution at its finest.
Genetic algorithms are considered as part of reinforcement learning and they have the most important feature proved by decade-long practice: no one gives a shit about them.
Humanity still couldn’t come up with a task where those would be more effective than other methods. But they are great for student experiments and let people get their university supervisors excited about “artificial intelligence” without too much labour. And youtube would love it as well.
“Bunch of stupid trees learning to correct errors of each other”
Nowadays is used for:
Everything that fits classical algorithm approaches (but works better)
It’s time for modern, grown-up methods. Ensembles and neural networks are two main fighters paving our path to a singularity. Today they are producing the most accurate results and are widely used in production.
However, the neural networks got all the hype today, while the words like “boosting” or “bagging” are scarce hipsters on TechCrunch.
Despite all the effectiveness the idea behind these is overly simple. If you take a bunch of inefficient algorithms and force them to correct each other’s mistakes, the overall quality of a system will be higher than even the best individual algorithms.
You’ll get even better results if you take the most unstable algorithms that are predicting completely different results on small noise in input data. Like Regression and Decision Trees. These algorithms are so sensitive to even a single outlier in input data to have models go mad.
In fact, this is what we need.
We can use any algorithm we know to create an ensemble. Just throw a bunch of classifiers, spice it up with regression and don’t forget to measure accuracy. From my experience: don’t even try a Bayes or kNN here. Although “dumb”, they are really stable. That’s boring and predictable. Like your ex.
Instead, there are three battle-tested methods to create ensembles.
Stacking Output of several parallel models is passed as input to the last one which makes a final decision. Like that girl who asks her girlfriends whether to meet with you in order to make the final decision herself.
Emphasis here on the word “different”. Mixing the same algorithms on the same data would make no sense. The choice of algorithms is completely up to you. However, for final decision-making model, regression is usually a good choice.
Based on my experience stacking is less popular in practice, because two other methods are giving better accuracy.
Bagging aka Bootstrap AGGregatING. Use the same algorithm but train it on different subsets of original data. In the end — just average answers.
Data in random subsets may repeat. For example, from a set like “1-2-3” we can get subsets like “2-2-3”, “1-2-2”, “3-1-2” and so on. We use these new datasets to teach the same algorithm several times and then predict the final answer via simple majority voting.
The most famous example of bagging is the Random Forest algorithm, which is simply bagging on the decision trees (which were illustrated above). When you open your phone’s camera app and see it drawing boxes around people’s faces — it’s probably the results of Random Forest work. Neural networks would be too slow to run real-time yet bagging is ideal given it can calculate trees on all the shaders of a video card or on these new fancy ML processors.
In some tasks, the ability of the Random Forest to run in parallel is more important than a small loss in accuracy to the boosting, for example. Especially in real-time processing. There is always a trade-off.
Boosting Algorithms are trained one by one sequentially. Each subsequent one paying most of its attention to data points that were mispredicted by the previous one. Repeat until you are happy.
Same as in bagging, we use subsets of our data but this time they are not randomly generated. Now, in each subsample we take a part of the data the previous algorithm failed to process. Thus, we make a new algorithm learn to fix the errors of the previous one.
The main advantage here — a very high, even illegal in some countries precision of classification that all cool kids can envy. The cons were already called out — it doesn’t parallelize. But it’s still faster than neural networks. It’s like a race between a dump truck and a racecar. The truck can do more, but if you want to go fast — take a car.
If you want a real example of boosting — open Facebook or Google and start typing in a search query. Can you hear an army of trees roaring and smashing together to sort results by relevancy? That’s because they are using boosting.
“We have a thousand-layer network, dozens of video cards, but still no idea where to use it. Let’s generate cat pics!”
If no one has ever tried to explain neural networks to you using “human brain” analogies, you’re happy. Tell me your secret. But first, let me explain it the way I like.
Any neural network is basically a collection of neurons and connections between them. Neuron is a function with a bunch of inputs and one output. Its task is to take all numbers from its input, perform a function on them and send the result to the output.
Here is an example of a simple but useful in real life neuron: sum up all numbers from the inputs and if that sum is bigger than N — give 1 as a result. Otherwise — zero.
Connections are like channels between neurons. They connect outputs of one neuron with the inputs of another so they can send digits to each other. Each connection has only one parameter — weight. It’s like a connection strength for a signal. When the number 10 passes through a connection with a weight 0.5 it turns into 5.
These weights tell the neuron to respond more to one input and less to another. Weights are adjusted when training — that’s how the network learns. Basically, that’s all there is to it.
To prevent the network from falling into anarchy, the neurons are linked by layers, not randomly. Within a layer neurons are not connected, but they are connected to neurons of the next and previous layers. Data in the network goes strictly in one direction — from the inputs of the first layer to the outputs of the last.
If you throw in a sufficient number of layers and put the weights correctly, you will get the following: by applying to the input, say, the image of handwritten digit 4, black pixels activate the associated neurons, they activate the next layers, and so on and on, until it finally lights up the exit in charge of the four. The result is achieved.
When doing real-life programming nobody is writing neurons and connections. Instead, everything is represented as matrices and calculated based on matrix multiplication for better performance. My favourite video on this and its sequel below describe the whole process in an easily digestible way using the example of recognizing hand-written digits. Watch them if you want to figure this out.
A network that has multiple layers that have connections between every neuron is called a perceptron (MLP) and considered the simplest architecture for a novice. I didn’t see it used for solving tasks in production.
After we constructed a network, our task is to assign proper ways so neurons will react correctly to incoming signals. Now is the time to remember that we have data that is samples of ‘inputs’ and proper ‘outputs’. We will be showing our network a drawing of the same digit 4 and tell it ‘adapt your weights so whenever you see this input your output would emit 4’.
To start with, all weights are assigned randomly. After we show it a digit it emits a random answer because the weights are not correct yet, and we compare how much this result differs from the right one. Then we start traversing network backward from outputs to inputs and tell every neuron ‘hey, you did activate here but you did a terrible job and everything went south from here downwards, let’s keep less attention to this connection and more of that one, mkay?’.
After hundreds of thousands of such cycles of ‘infer-check-punish’, there is a hope that the weights are corrected and act as intended. The science name for this approach is Backpropagation, or a ‘method of backpropagating an error’. Funny thing it took twenty years to come up with this method. Before this we still taught neural networks somehow.
My second favorite vid is describing this process in depth, but it’s still very accessible.
A well trained neural network can fake the work of any of the algorithms described in this chapter (and frequently works more precisely). This universality is what made them widely popular. Finally we have an architecture of human brain they said we just need to assemble lots of layers and teach them on any possible data they hoped. Then the first AI winter started, then it thawed, and then another wave of disappointment hit.
It turned out networks with a large number of layers required computation power unimaginable at that time. Nowadays any gamer PC with geforces outperforms the datacenters of that time. So people didn’t have any hope then to acquire computation power like that and neural networks were a huge bummer.
And then ten years ago deep learning rose.
In 2012 convolutional neural networks acquired an overwhelming victory in ImageNet competition that made the world suddenly remember about methods of deep learning described in the ancient 90s. Now we have video cards!
Differences of deep learning from classical neural networks were in new methods of training that could handle bigger networks. Nowadays only theoretics would try to divide which learning to consider deep and not so deep. And we, as practitioners are using popular ‘deep’ libraries like Keras, TensorFlow & PyTorch even when we build a mini-network with five layers. Just because it’s better suited than all the tools that came before. And we just call them neural networks.
Convolutional neural networks are all the rage right now. They are used to search for objects on photos and in videos, face recognition, style transfer, generating and enhancing images, creating effects like slow-mo and improving image quality. Nowadays CNNs are used in all the cases that involve pictures and videos. Even in your iPhone several of these networks are going through your nudes to detect objects in those. If there is something to detect, heh.
Image above is a result produced by Detectron that was recently open-sourced by Facebook
A problem with images was always the difficulty of extracting features out of them. You can split text by sentences, lookup words’ attributes in specialized vocabularies, etc. But images had to be labeled manually to teach the machine where cat ears or tails were in this specific image. This approach got the name ‘handcrafting features’ and used to be used almost by everyone.
There are lots of issues with the handcrafting.
First of all, if a cat had its ears down or turned away from the camera: you are in trouble, the neural network won’t see a thing.
Secondly, try naming on the spot 10 different features that distinguish cats from other animals. I for one couldn’t do it, but when I see a black blob rushing past me at night — even if I only see it in the corner of my eye — I would definitely tell a cat from a rat. Because people don’t look only at ear form or leg count and account lots of different features they don’t even think about. And thus cannot explain it to the machine.
So it means the machine needs to learn such features on its own, building on top of basic lines. We’ll do the following: first, we divide the whole image into 8x8 pixel blocks and assign to each a type of dominant line – either horizontal [-], vertical [|] or one of the diagonals [/]. It can also be that several would be highly visible — this happens and we are not always absolutely confident.
Output would be several tables of sticks that are in fact the simplest features representing objects edges on the image. They are images on their own but built out of sticks. So we can once again take a block of 8x8 and see how they match together. And again and again…
This operation is called convolution, which gave the name for the method. Convolution can be represented as a layer of a neural network, because each neuron can act as any function.
When we feed our neural network with lots of photos of cats it automatically assigns bigger weights to those combinations of sticks it saw the most frequently. It doesn’t care whether it was a straight line of a cat’s back or a geometrically complicated object like a cat’s face, something will be highly activating.
As the output, we would put a simple perceptron which will look at the most activated combinations and based on that differentiate cats from dogs.
The beauty of this idea is that we have a neural net that searches for the most distinctive features of the objects on its own. We don’t need to pick them manually. We can feed it any amount of images of any object just by googling billions of images with it and our net will create feature maps from sticks and learn to differentiate any object on its own.
For this I even have a handy unfunny joke:
Give your neural net a fish and it will be able to detect fish for the rest of its life. Give your neural net a fishing rod and it will be able to detect fishing rods for the rest of its life…
The second most popular architecture today. Recurrent networks gave us useful things like neural machine translation (here is my post about it), speech recognition and voice synthesis in smart assistants. RNNs are the best for sequential data like voice, text or music.
Remember Microsoft Sam, the old-school speech synthesizer from Windows XP? That funny guy builds words letter by letter, trying to glue them up together. Now, look at Amazon Alexa or Assistant from Google. They don’t only say the words clearly, they even place the right accents!
Neural Net is trying to speak
All because modern voice assistants are trained to speak not letter by letter, but on whole phrases at once. We can take a bunch of voiced texts and train a neural network to generate an audio-sequence closest to the original speech.
In other words, we use text as input and its audio as the desired output. We ask a neural network to generate some audio for the given text, then compare it with the original, correct errors and try to get as close as possible to ideal.
Sounds like a classical learning process. Even a perceptron is suitable for this. But how should we define its outputs? Firing one particular output for each possible phrase is not an option — obviously.
Here we’ll be helped by the fact that text, speech or music are sequences. They consist of consecutive units like syllables. They all sound unique but depend on previous ones. Lose this connection and you get dubstep.
We can train the perceptron to generate these unique sounds, but how will it remember previous answers? So the idea is to add memory to each neuron and use it as an additional input on the next run. A neuron could make a note for itself - hey, we had a vowel here, the next sound should sound higher (it’s a very simplified example).
That’s how recurrent networks appeared.
This approach had one huge problem - when all neurons remembered their past results, the number of connections in the network became so huge that it was technically impossible to adjust all the weights.
When a neural network can’t forget, it can’t learn new things (people have the same flaw).
The first decision was simple: limit the neuron memory. Let’s say, to memorize no more than 5 recent results. But it broke the whole idea.
A much better approach came later: to use special cells, similar to computer memory. Each cell can record a number, read it or reset it. They were called long and short-term memory (LSTM) cells.
Now, when a neuron needs to set a reminder, it puts a flag in that cell. Like “it was a consonant in a word, next time use different pronunciation rules”. When the flag is no longer needed, the cells are reset, leaving only the “long-term” connections of the classical perceptron. In other words, the network is trained not only to learn weights but also to set these reminders.
Simple, but it works!
CNN + RNN = Fake Obama
You can take speech samples from anywhere. BuzzFeed, for example, took Obama’s speeches and trained a neural network to imitate his voice. As you see, audio synthesis is already a simple task. Video still has issues, but it’s a question of time.
There are many more network architectures in the wild. I recommend a good article called Neural Network Zoo, where almost all types of neural networks are collected and briefly explained.
Menulis adalah ekspresi dari gagasan yang lahir atas perenungan atau respon atas fenomena.
Menulis adalah leverage untuk mengubah seseorang bahkan mungkin peradaban.
Tahap I: Pendahuluan yang Menggigit
Topik yang Meyakinkan
Topik yang kuat lahir dari letupan pikiran yang memaksa kita untuk “tidak bisa tidak, ini harus dituliskan”.
Topik yang kuat bisa didorong dengan dua hal:
Menentukan tujuan tulisan kita:
Membuka mata orang, menunjukkan apa yang selama ini dipahami salah.
Menuliskan apa yang banyak orang pikirkan, tapi tak pernah tertuliskan.
Merangkaikan gejala yang muncul, meprediksikan apa yang akan terjadi.
Menguraikan gagasan raksasa menjadi hal-hal yang mudah dilakukan.
Memberikan solusi atas problem yang rumit.
Menceritakan kisah emosional menegangkan untuk memberikan makna dan pelajaran.
Memadukan tujuan tulisan dengan motivasi internal kita:
Apakah menuliskannya itu menjadi cara mengungkapkan dan meluapkan apa yang ada di dada kita?
Apakah menuliskannya itu membantu mengubah gerutuan kita menjadi sesuatu yang sistematis dan rasional?
Apakah menuliskannya itu akan mendorong orang lain melakukan hal yang kita anggap penting.
Apakah kita terobsesi dengan topik tulisan kita dan ingin orang lain juga bersemangat seperti kita?
Tujuan tulisan memperjelas apa yang mau kita raih, motivasi memastikan kita mencapainya.
Temukan Pancing yang Tepat
Pendahuluan adalah untuk memancing pembaca terus membaca. Ia membangun kepercayaan. Bukan sekadar gimmick.
Apa itu pancing? Pancing adalah tulisan setengah matang yang dapat berupa:
Pertanyaan - menanyakan sesuatu yang menarik, tapi tidak dijawab
Naratif - menuliskan suatu cerita, tapi tidak disimpulkan
Temuan - menyampaikan temuan baru, tetapi hanya secuil bagian saja yang disampaikan
Argumen - menyampaikan klaim yang besar, tapi tidak disebutkan alasannya.
Pancing berfungsi untuk:
mempertajam pendahuluan
membantu menemukan apa yang kita dan pembaca inginkan untuk diteruskan
Contoh pancing naratif:
Saat ini pukul 3 dini hari, dan tak seorang pun yang lain yang terlihat dalam jarang pandang kami.
Dari lereng gunung ini kami bergantian berteriak, tapi yang terdengar hanya pantulan suara kami sendiri.
Kami mencoba untuk bergerak, tetapi jari kami yang membeku membuat kami tak bisa ke manapun.
Apa yang seperti akan menjadi akhir bagi kehidupan kami, ternyata akan menjadi titik awal hidup kami.
Dan ini adalah apa yang terjadi kemudian.
Contoh pancing temuan
Peneliti menemukan bahwa ternyata 50% pasien Covid tak bisa merasakan bau dan rasa.
30% di antara mereka berakhir dengan kematian, tak bisa merasakan apapun.
Yang tersisa menjadi sebuah pengetahuan baru, tentang apa yang menjadi kunci untuk bertahan hidup sebagai penderita Covid.
5.7 - Istilah Baku di Bidang Teknik Elektro
Istilah Baku di Bidang Teknik Elektro
Istilah baku di bidang teknik elektro berdasar KBBI dan Pedoman Pembentukan Istilah.
preposisi “di” adalah penanda tempat, sedangkan “pada” adalah penanda kata-kata yang menyatakan makhluk hidup (orang, binatang), benda abstrak (waktu, situasi).
preposisi “pada” berubah menjadi “kepada” dan preposisi “di” menjadi “ke” jika menandakan suatu arah atau tujuan.
Kata sinonim
linear dan linier
Kata berikut (ternyata) kosa kata bahasa Indonesia
Judul klaim itu boleh sama dengan yang lain, yang penting klaimnya
Bidang Teknik Invensi
Invensi biasanya dua:
produk
proses
aplikasi/penggunaan
atau gabungannya
Bagian ini menyebutkan tentang invensi itu adalah produk, proses, atau keduanya
Latar Belakang Invensi
Penelusuran atas invensi terdahulu.
Menunjukkan kekurangan invensi terdahulu.
Menunjukkan kelebihan invensi sekarang.
Uraian Singkat Invensi
Menguraikan invensi secara umum
Sebagai cermin atas klaim.
Lebih rinci dari bidang teknik invensi dengan menyebutkan detil.
Semua fitur esensial diuraikan di urain singkat: konsentrasi, suhu dll.
Luas ke spesifik
Maka biasanya, dokumen invensi dibuat dari belakang (dari klaim)
Abstrak
200 kata atau 1 halaman
Uraian Singkat Gambar
Cukup menunjukkan Gambar ke
Dibutuhkan agar saat di Pengadilan jadi jelas
Uraian Lengkap Invensi
Awali dengan Definisi
Konsistensi Penulisan
Klaim
Klaim menentukan perlindungan
Penggunaan
Elektro:
produk yang dicirikan oleh mekanisme
dicirikan lagi oleh fungsi
Drafter itu harus seluas-luasnya, pemeriksa sesempit-sempitnya
Computer Vision has become ubiquitous in our society, with applications in search, image understanding, apps, mapping, medicine, drones, and self-driving cars. Core to many of these applications are visual recognition tasks such as image classification, localization and detection. Recent developments in neural network (aka “deep learning”) approaches have greatly advanced the performance of these state-of-the-art visual recognition systems. This course is a deep dive into details of the deep learning architectures with a focus on learning end-to-end models for these tasks, particularly image classification. During the 10-week course, students will learn to implement, train and debug their own neural networks and gain a detailed understanding of cutting-edge research in computer vision. The final assignment will involve training a multi-million parameter convolutional neural network and applying it on the largest image classification dataset (ImageNet). We will focus on teaching how to set up the problem of image recognition, the learning algorithms (e.g. backpropagation), practical engineering tricks for training and fine-tuning the networks and guide the students through hands-on assignments and a final course project. Much of the background and materials of this course will be drawn from the ImageNet Challenge.
01. Introduction to CNN for visual recognition
A brief history of Computer vision starting from the late 1960s to 2017.
Computer vision problems includes image classification, object localization, object detection, and scene understanding.
Imagenet is one of the biggest datasets in image classification available right now.
Starting 2012 in the Imagenet competition, CNN (Convolutional neural networks) is always winning.
CNN actually has been invented in 1997 by Yann Lecun.
02. Image classification
Image classification problem has a lot of challenges like illumination and viewpoints.
An image classification algorithm can be solved with K nearest neighborhood (KNN) but it can poorly solve the problem. The properties of KNN are:
Hyperparameters of KNN are: k and the distance measure
K is the number of neighbors we are comparing to.
Distance measures include:
L2 distance (Euclidean distance)
Best for non coordinate points
L1 distance (Manhattan distance)
Best for coordinate points
Hyperparameters can be optimized using Cross-validation as following (In our case we are trying tp predict K):
Split your dataset into f folds.
Given predicted hyperparameters:
Train your algorithm with f-1 folds and test it with the remain flood. and repeat this with every fold.
Choose the hyperparameters that gives the best training values (Average over all folds)
Linear SVM classifier is an option for solving the image classification problem, but the curse of dimensions makes it stop improving at some point.
Logistic regression is a also a solution for image classification problem, but image classification problem is non linear!
Linear classifiers has to run the following equation: Y = wX + b
shape of w is the same as x and shape of b is 1.
We can add 1 to X vector and remove the bias so that: Y = wX
shape of x is oldX+1 and w is the same as x
We need to know how can we get w’s and b’s that makes the classifier runs at best.
03. Loss function and optimization
In the last section we talked about linear classifier but we didn’t discussed how we could train the parameters of that model to get best w’s and b’s.
We need a loss function to measure how good or bad our current parameters.
Loss=L[i]=(f(X[i],W),Y[i])Loss_for_all=1/N*Sum(Li(f(X[i],W),Y[i]))# Indicates the average
Then we find a way to minimize the loss function given some parameters. This is called optimization.
Loss function for a linear SVM classifier:
L[i] = Sum where all classes except the predicted class (max(0, s[j] - s[y[i]] + 1))
We call this the hinge loss.
Loss function means we are happy if the best prediction are the same as the true value other wise we give an error with 1 margin.
Example:
Given this example we want to compute the loss of this image.
Final loss is 695.45 which is big and reflects that the cat score needs to be the best over all classes as its the lowest value now. We need to minimize that loss.
Its OK for the margin to be 1. But its a hyperparameter too.
If your loss function gives you zero, are this value is the same value for your parameter? No there are a lot of parameters that can give you best score.
You’ll sometimes hear about people instead using the squared hinge loss SVM (or L2-SVM). that penalizes violated margins more strongly (quadratically instead of linearly). The unsquared version is more standard, but in some datasets the squared hinge loss can work better.
We add regularization for the loss function so that the discovered model don’t overfit the data.
Loss=L=1/N*Sum(Li(f(X[i],W),Y[i]))+lambda*R(W)
Where R is the regularizer, and lambda is the regularization term.
There are different regularizations techniques:
Regularizer
Equation
Comments
L2
R(W) = Sum(W^2)
Sum all the W squared
L1
R(W) = Sum(lWl)
Sum of all Ws with abs
Elastic net (L1 + L2)
R(W) = beta * Sum(W^2) + Sum(lWl)
Dropout
No Equation
Regularization prefers smaller Ws over big Ws.
Regularizations is called weight decay. biases should not included in regularization.
Softmax loss (Like linear regression but works for more than 2 classes):
* ```python
Loss = -logP(Y = y[i]|X = x[i])
```
*
* Log of the probability of the good class. We want it to be near 1 thats why we added a minus.
* Softmax loss is called cross-entropy loss.
Consider this numerical problem when you are computing Softmax:
* ```python
f = np.array([123, 456, 789]) # example with 3 classes and each having large scores
p = np.exp(f) / np.sum(np.exp(f)) # Bad: Numeric problem, potential blowup
# instead: first shift the values of f so that the highest number is 0:
f -= np.max(f) # f becomes [-666, -333, 0]
p = np.exp(f) / np.sum(np.exp(f)) # safe to do, gives the correct answer
```
*
Optimization:
How we can optimize loss functions we discussed?
Strategy one:
Get a random parameters and try all of them on the loss and get the best loss. But its a bad idea.
Our goal is to compute the gradient of each parameter we have.
Numerical gradient: Approximate, slow, easy to write. (But its useful in debugging.)
Analytic gradient: Exact, Fast, Error-prone. (Always used in practice)
After we compute the gradient of our parameters, we compute the gradient descent:
* ```python
W = W - learning_rate * W_grad
```
*
* learning_rate is so important hyper parameter you should get the best value of it first of all the hyperparameters.
* stochastic gradient descent:
* Instead of using all the date, use a mini batch of examples (32/64/128 are commonly used) for faster results.
04. Introduction to Neural network
Computing the analytic gradient for arbitrary complex functions:
What is a Computational graphs?
Used to represent any function. with nodes.
Using Computational graphs can easy lead us to use a technique that called back-propagation. Even with complex models like CNN and RNN.
Back-propagation simple example:
Suppose we have f(x,y,z) = (x+y)z
Then graph can be represented this way:
* ```
X
\
(+)--> q ---(*)--> f
/ /
Y /
/
/
Z---------/
```
*
* We made an intermediate variable `q` to hold the values of `x+y`
* Then we have:
*
* ```python
q = (x+y) # dq/dx = 1 , dq/dy = 1
f = qz # df/dq = z , df/dz = q
```
*
* Then:
*
* ```python
df/dq = z
df/dz = q
df/dx = df/dq * dq/dx = z * 1 = z # Chain rule
df/dy = df/dq * dq/dy = z * 1 = z # Chain rule
```
*
So in the Computational graphs, we call each operation f. For each f we calculate the local gradient before we go on back propagation and then we compute the gradients in respect of the loss function using the chain rule.
In the Computational graphs you can split each operation to as simple as you want but the nodes will be a lot. if you want the nodes to be smaller be sure that you can compute the gradient of this node.
A bigger example:
Hint: the back propagation of two nodes going to one node from the back is by adding the two derivatives.
Modularized implementation: forward/ backward API (example multiply code):
* ```python
class MultuplyGate(object):
"""
x,y are scalars
"""
def forward(x,y):
z = x*y
self.x = x # Cache
self.y = y # Cache
# We cache x and y because we know that the derivatives contains them.
return z
def backward(dz):
dx = self.y * dz #self.y is dx
dy = self.x * dz
return [dx, dy]
```
*
If you look at a deep learning framework you will find it follow the Modularized implementation where each class has a definition for forward and backward. For example:
Multiplication
Max
Plus
Minus
Sigmoid
Convolution
So to define neural network as a function:
(Before) Linear score function: f = Wx
(Now) 2-layer neural network: f = W2*max(0,W1*x)
Where max is the RELU non linear function
(Now) 3-layer neural network: f = W3*max(0,W2*max(0,W1*x)
And so on..
Neural networks is a stack of some simple operation that forms complex operations.
05. Convolutional neural networks (CNNs)
Neural networks history:
First perceptron machine was developed by Frank Rosenblatt in 1957. It was used to recognize letters of the alphabet. Back propagation wasn’t developed yet.
Multilayer perceptron was developed in 1960 by Adaline/Madaline. Back propagation wasn’t developed yet.
Back propagation was developed in 1986 by Rumeelhart.
There was a period which nothing new was happening with NN. Cause of the limited computing resources and data.
In 2006 Hinton released a paper that shows that we can train a deep neural network using Restricted Boltzmann machines to initialize the weights then back propagation.
The first strong results was in 2012 by Hinton in speech recognition. And the Alexnet “Convolutional neural networks” that wins the image net in 2012 also by Hinton’s team.
After that NN is widely used in various applications.
Convolutional neural networks history:
Hubel & Wisel in 1959 to 1968 experiments on cats cortex found that there are a topographical mapping in the cortex and that the neurons has hireical organization from simple to complex.
In 1998, Yann Lecun gives the paper Gradient-based learning applied to document recognition that introduced the Convolutional neural networks. It was good for recognizing zip letters but couldn’t run on a more complex examples.
In 2012 AlexNet used the same Yan Lecun architecture and won the image net challenge. The difference from 1998 that now we have a large data sets that can be used also the power of the GPUs solved a lot of performance problems.
Starting from 2012 there are CNN that are used for various tasks (Here are some applications):
Image classification.
Image retrieval.
Extracting features using a NN and then do a similarity matching.
Object detection.
Segmentation.
Each pixel in an image takes a label.
Face recognition.
Pose recognition.
Medical images.
Playing Atari games with reinforcement learning.
Galaxies classification.
Street signs recognition.
Image captioning.
Deep dream.
ConvNet architectures make the explicit assumption that the inputs are images, which allows us to encode certain properties into the architecture.
There are a few distinct types of Layers in ConvNet (e.g. CONV/FC/RELU/POOL are by far the most popular)
Each Layer may or may not have parameters (e.g. CONV/FC do, RELU/POOL don’t)
Each Layer may or may not have additional hyperparameters (e.g. CONV/FC/POOL do, RELU doesn’t)
How Convolutional neural networks works?
A fully connected layer is a layer in which all the neurons is connected. Sometimes we call it a dense layer.
If input shape is (X, M) the weighs shape for this will be (NoOfHiddenNeurons, X)
Convolution layer is a layer in which we will keep the structure of the input by a filter that goes through all the image.
We do this with dot product: W.T*X + b. This equation uses the broadcasting technique.
So we need to get the values of W and b
We usually deal with the filter (W) as a vector not a matrix.
We call output of the convolution activation map. We need to have multiple activation map.
Example if we have 6 filters, here are the shapes:
Input image (32,32,3)
filter size (5,5,3)
We apply 6 filters. The depth must be three because the input map has depth of three.
Output of Conv. (28,28,6)
if one filter it will be (28,28,1)
After RELU (28,28,6)
Another filter (5,5,6)
Output of Conv. (24,24,10)
It turns out that convNets learns in the first layers the low features and then the mid-level features and then the high level features.
After the Convnets we can have a linear classifier for a classification task.
In Convolutional neural networks usually we have some (Conv ==> Relu)s and then we apply a pool operation to downsample the size of the activation.
What is stride when we are doing convolution:
While doing a conv layer we have many choices to make regarding the stride of which we will take. I will explain this by examples.
Stride is skipping while sliding. By default its 1.
Given a matrix with shape of (7,7) and a filter with shape (3,3):
If stride is 1 then the output shape will be (5,5)# 2 are dropped
If stride is 2 then the output shape will be (3,3)# 4 are dropped
If stride is 3 it doesn’t work.
A general formula would be ((N-F)/stride +1)
If stride is 1 then O = ((7-3)/1)+1 = 4 + 1 = 5
If stride is 2 then O = ((7-3)/2)+1 = 2 + 1 = 3
If stride is 3 then O = ((7-3)/3)+1 = 1.33 + 1 = 2.33# doesn't work
In practice its common to zero pad the border. # Padding from both sides.
Give a stride of 1 its common to pad to this equation: (F-1)/2 where F is the filter size
Example F = 3 ==> Zero pad with 1
Example F = 5 ==> Zero pad with 2
If we pad this way we call this same convolution.
Adding zeros gives another features to the edges thats why there are different padding techniques like padding the corners not zeros but in practice zeros works!
We do this to maintain our full size of the input. If we didn’t do that the input will be shrinking too fast and we will lose a lot of data.
Example:
If we have input of shape (32,32,3) and ten filters with shape is (5,5) with stride 1 and pad 2
Output size will be (32,32,10)# We maintain the size.
Size of parameters per filter = 5*5*3 + 1 = 76
All parameters = 76 * 10 = 76
Number of filters is usually common to be to the power of 2. # To vectorize well.
So here are the parameters for the Conv layer:
Number of filters K.
Usually a power of 2.
Spatial content size F.
3,5,7 ….
The stride S.
Usually 1 or 2 (If the stride is big there will be a downsampling but different of pooling)
Amount of Padding
If we want the input shape to be as the output shape, based on the F if 3 its 1, if F is 5 the 2 and so on.
Pooling makes the representation smaller and more manageable.
Pooling Operates over each activation map independently.
Example of pooling is the maxpooling.
Parameters of max pooling is the size of the filter and the stride"
Example 2x2 with stride 2# Usually the two parameters are the same 2 , 2
Also example of pooling is average pooling.
In this case it might be learnable.
06. Training neural networks I
As a revision here are the Mini batch stochastic gradient descent algorithm steps:
Loop:
Sample a batch of data.
Forward prop it through the graph (network) and get loss.
Backprop to calculate the gradients.
Update the parameters using the gradients.
Activation functions:
Different choices for activation function includes Sigmoid, tanh, RELU, Leaky RELU, Maxout, and ELU.
Sigmoid:
Squashes the numbers between [0,1]
Used as a firing rate like human brains.
Sigmoid(x) = 1 / (1 + e^-x)
Problems with sigmoid:
big values neurons kill the gradients.
Gradients are in most cases near 0 (Big values/small values), that kills the updates if the graph/network are large.
Not Zero-centered.
Didn’t produce zero-mean data.
exp() is a bit compute expensive.
just to mention. We have a more complex operations in deep learning like convolution.
Tanh:
Squashes the numbers between [-1,1]
Zero centered.
Still big values neurons “kill” the gradients.
Tanh(x) is the equation.
Proposed by Yann Lecun in 1991.
RELU (Rectified linear unit):
RELU(x) = max(0,x)
Doesn’t kill the gradients.
Only small values that are killed. Killed the gradient in the half
Computationally efficient.
Converges much faster than Sigmoid and Tanh (6x)
More biologically plausible than sigmoid.
Proposed by Alex Krizhevsky in 2012 Toronto university. (AlexNet)
Problems:
Not zero centered.
If weights aren’t initialized good, maybe 75% of the neurons will be dead and thats a waste computation. But its still works. This is an active area of research to optimize this.
To solve the issue mentioned above, people might initialize all the biases by 0.01
Leaky RELU:
leaky_RELU(x) = max(0.01x,x)
Doesn’t kill the gradients from both sides.
Computationally efficient.
Converges much faster than Sigmoid and Tanh (6x)
Will not die.
PRELU is placing the 0.01 by a variable alpha which is learned as a parameter.
Exponential linear units (ELU):
* ```
ELU(x) = { x if x > 0
alpah *(exp(x) -1) if x <= 0
# alpah are a learning parameter
}
```
*
* It has all the benefits of RELU
* Closer to zero mean outputs and adds some robustness to noise.
* problems
* `exp()` is a bit compute expensive.
Maxout activations:
maxout(x) = max(w1.T*x + b1, w2.T*x + b2)
Generalizes RELU and Leaky RELU
Doesn’t die!
Problems:
oubles the number of parameters per neuron
In practice:
Use RELU. Be careful for your learning rates.
Try out Leaky RELU/Maxout/ELU
Try out tanh but don’t expect much.
Don’t use sigmoid!
Data preprocessing:
Normalize the data:
# Zero centered data. (Calculate the mean for every input).# On of the reasons we do this is because we need data to be between positive and negative and not all the be negative or positive. X-=np.mean(X,axis=1)# Then apply the standard deviation. Hint: in images we don't do this.X/=np.std(X,axis=1)
To normalize images:
Subtract the mean image (E.g. Alexnet)
Mean image shape is the same as the input images.
Or Subtract per-channel mean
Means calculate the mean for each channel of all images. Shape is 3 (3 channels)
Weight initialization:
What happened when initialize all Ws with zeros?
All the neurons will do exactly the same thing. They will have the same gradient and they will have the same update.
So if W’s of a specific layer is equal the thing described happened
First idea is to initialize the w’s with small random numbers:
* ```python
W = 0.01 * np.random.rand(D, H)
# Works OK for small networks but it makes problems with deeper networks!
```
*
* The standard deviations is going to zero in deeper networks. and the gradient will vanish sooner in deep networks.
*
* ```python
W = 1 * np.random.rand(D, H)
# Works OK for small networks but it makes problems with deeper networks!
```
*
* The network will explode with big numbers!
Xavier initialization:
* ```python
W = np.random.rand(in, out) / np.sqrt(in)
```
*
* It works because we want the variance of the input to be as the variance of the output.
* But it has an issue, It breaks when you are using RELU.
He initialization (Solution for the RELU issue):
* ```python
W = np.random.rand(in, out) / np.sqrt(in/2)
```
*
* Solves the issue with RELU. Its recommended when you are using RELU
Proper initialization is an active area of research.
Batch normalization:
is a technique to provide any layer in a Neural Network with inputs that are zero mean/unit variance.
It speeds up the training. You want to do this a lot.
Made by Sergey Ioffe and Christian Szegedy at 2015.
We make a Gaussian activations in each layer. by calculating the mean and the variance.
Usually inserted after (fully connected or Convolutional layers) and (before nonlinearity).
Steps (For each output of a layer)
5. First we compute the mean and variance^2 of the batch for each feature.
6. We normalize by subtracting the mean and dividing by square root of (variance^2 + epsilon)
epsilon to not divide by zero
Then we make a scale and shift variables: Result = gamma * normalizedX + beta
gamma and beta are learnable parameters.
it basically possible to say “Hey!! I don’t want zero mean/unit variance input, give me back the raw input - it’s better for me.”
Hey shift and scale by what you want not just the mean and variance!
The algorithm makes each layer flexible (It chooses which distribution it wants)
We initialize the BatchNorm Parameters to transform the input to zero mean/unit variance distributions but during training they can learn that any other distribution might be better.
During the running of the training we need to calculate the globalMean and globalVariance for each layer by using weighted average.
Benefits of Batch Normalization:
Networks train faster.
Allows higher learning rates.
helps reduce the sensitivity to the initial starting weights.
Makes more activation functions viable.
Provides some regularization.
Because we are calculating mean and variance for each batch that gives a slight regularization effect.
In conv layers, we will have one variance and one mean per activation map.
Batch normalization have worked best for CONV and regular deep NN, But for recurrent NN and reinforcement learning its still an active research area.
Its challengey in reinforcement learning because the batch is small.
Baby sitting the learning process
Preprocessing of data.
Choose the architecture.
Make a forward pass and check the loss (Disable regularization). Check if the loss is reasonable.
Add regularization, the loss should go up!
Disable the regularization again and take a small number of data and try to train the loss and reach zero loss.
You should overfit perfectly for small datasets.
Take your full training data, and small regularization then try some value of learning rate.
If loss is barely changing, then the learning rate is small.
If you got NAN then your NN exploded and your learning rate is high.
Get your learning rate range by trying the min value (That can change) and the max value that doesn’t explode the network.
Do Hyperparameters optimization to get the best hyperparameters values.
Hyperparameter Optimization
Try Cross validation strategy.
Run with a few ephocs, and try to optimize the ranges.
Its best to optimize in log space.
Adjust your ranges and try again.
Its better to try random search instead of grid searches (In log space)
07. Training neural networks II
Optimization algorithms:
Problems with stochastic gradient descent:
if loss quickly in one direction and slowly in another (For only two variables), you will get very slow progress along shallow dimension, jitter along steep direction. Our NN will have a lot of parameters then the problem will be more.
Local minimum or saddle points
If SGD went into local minimum we will stuck at this point because the gradient is zero.
Also in saddle points the gradient will be zero so we will stuck.
Saddle points says that at some point:
Some gradients will get the loss up.
Some gradients will get the loss down.
And that happens more in high dimensional (100 million dimension for example)
The problem of deep NN is more about saddle points than about local minimum because deep NN has high dimensions (Parameters)
Mini batches are noisy because the gradient is not taken for the whole batch.
SGD + momentum:
Build up velocity as a running mean of gradients:
* ```python
# Computing weighted average. rho best is in range [0.9 - 0.99]
V[t+1] = rho * v[t] + dx
x[t+1] = x[t] - learningRate * V[t+1]
```
*
* `V[0]` is zero.
* Solves the saddle point and local minimum problems.
* It overshoots the problem and returns to it back.
Nestrov momentum:
* ```python
dx = compute_gradient(x)
old_v = v
v = rho * v - learning_rate * dx
x+= -rho * old_v + (1+rho) * v
```
*
* Doesn't overshoot the problem but slower than SGD + momentum
AdaGrad
* ```python
grad_squared = 0
while(True):
dx = compute_gradient(x)
# here is a problem, the grad_squared isn't decayed (gets so large)
grad_squared += dx * dx
x -= (learning_rate*dx) / (np.sqrt(grad_squared) + 1e-7)
```
*
RMSProp
* ```python
grad_squared = 0
while(True):
dx = compute_gradient(x)
#Solved ADAgra
grad_squared = decay_rate * grad_squared + (1-grad_squared) * dx * dx
x -= (learning_rate*dx) / (np.sqrt(grad_squared) + 1e-7)
```
*
* People uses this instead of AdaGrad
Adam
Calculates the momentum and RMSProp as the gradients.
It need a Fixing bias to fix starts of gradients.
Is the best technique so far runs best on a lot of problems.
With beta1 = 0.9 and beta2 = 0.999 and learning_rate = 1e-3 or 5e-4 is a great starting point for many models!
Learning decay
Ex. decay learning rate by half every few epochs.
To help the learning rate not to bounce out.
Learning decay is common with SGD+momentum but not common with Adam.
Dont use learning decay from the start at choosing your hyperparameters. Try first and check if you need decay or not.
All the above algorithms we have discussed is a first order optimization.
Second order optimization
Use gradient and Hessian to from quadratic approximation.
Step to the minima of the approximation.
What is nice about this update?
It doesn’t has a learning rate in some of the versions.
But its unpractical for deep learning
Has O(N^2) elements.
Inverting takes O(N^3).
L-BFGS is a version of second order optimization
Works with batch optimization but not with mini-batches.
In practice first use ADAM and if it didn’t work try L-BFGS.
Some says all the famous deep architectures uses SGS + Nestrov momentum
Regularization
So far we have talked about reducing the training error, but we care about most is how our model will handle unseen data!
What if the gab of the error between training data and validation data are too large?
This error is called high variance.
Model Ensembles:
Algorithm:
Train multiple independent models of the same architecture with different initializations.
At test time average their results.
It can get you extra 2% performance.
It reduces the generalization error.
You can use some snapshots of your NN at the training ensembles them and take the results.
Regularization solves the high variance problem. We have talked about L1, L2 Regularization.
Some Regularization techniques are designed for only NN and can do better.
Drop out:
In each forward pass, randomly set some of the neurons to zero. Probability of dropping is a hyperparameter that are 0.5 for almost cases.
So you will chooses some activation and makes them zero.
It works because:
It forces the network to have redundant representation; prevent co-adaption of features!
If you think about this, It ensemble some of the models in the same model!
At test time we might multiply each dropout layer by the probability of the dropout.
Sometimes at test time we don’t multiply anything and leave it as it is.
With drop out it takes more time to train.
Data augmentation:
Another technique that makes Regularization.
Change the data!
For example flip the image, or rotate it.
Example in ResNet:
Training: Sample random crops and scales:
Pick random L in range [256,480]
Resize training image, short side = L
Sample random 224x244 patch.
Testing: average a fixed set of crops
4. Resize image at 5 scales: {224, 256, 384, 480, 640}
5. For each size, use 10 224x224 crops: 4 corners + center + flips
Apply Color jitter or PCA
Translation, rotation, stretching.
Drop connect
Like drop out idea it makes a regularization.
Instead of dropping the activation, we randomly zeroing the weights.
Fractional Max Pooling
Cool regularization idea. Not commonly used.
Randomize the regions in which we pool.
Stochastic depth
New idea.
Eliminate layers, instead on neurons.
Has the similar effect of drop out but its a new idea.
Transfer learning:
Some times your data is overfitted by your model because the data is small not because of regularization.
You need a lot of data if you want to train/use CNNs.
Steps of transfer learning
Train on a big dataset that has common features with your dataset. Called pretraining.
Freeze the layers except the last layer and feed your small dataset to learn only the last layer.
Not only the last layer maybe trained again, you can fine tune any number of layers you want based on the number of data you have
Guide to use transfer learning:
* | | Very Similar dataset | very different dataset |
| ----------------------- | ---------------------------------- | ---------------------------------------- |
| **very little dataset** | Use Linear classifier on top layer | You're in trouble.. Try linear classifier from different stages |
| **quite a lot of data** | Finetune a few layers | Finetune a large layers |
*
Transfer learning is the normal not an exception.
08. Deep learning software
This section changes a lot every year in CS231n due to rabid changes in the deep learning softwares.
CPU vs GPU
GPU The graphics card was developed to render graphics to play games or make 3D media,. etc.
NVIDIA vs AMD
Deep learning choose NVIDIA over AMD GPU because NVIDIA is pushing research forward deep learning also makes it architecture more suitable for deep learning.
CPU has fewer cores but each core is much faster and much more capable; great at sequential tasks. While GPUs has more cores but each core is much slower “dumber”; great for parallel tasks.
GPU cores needs to work together. and has its own memory.
Matrix multiplication is from the operations that are suited for GPUs. It has MxN independent operations that can be done on parallel.
Convolution operation also can be paralyzed because it has independent operations.
Programming GPUs frameworks:
CUDA (NVIDIA only)
Write c-like code that runs directly on the GPU.
Its hard to build a good optimized code that runs on GPU. Thats why they provided high level APIs.
Higher level APIs: cuBLAS, cuDNN, etc
CuDNN has implemented back prop. , convolution, recurrent and a lot more for you!
In practice you won’t write a parallel code. You will use the code implemented and optimized by others!
OpenCl
Similar to CUDA, but runs on any GPU.
Usually Slower .
Haven’t much support yet from all deep learning softwares.
There are a lot of courses for learning parallel programming.
If you aren’t careful, training can bottleneck on reading dara and transferring to GPU. So the solutions are:
Read all the data into RAM. # If possible
Use SSD instead of HDD
Use multiple CPU threads to prefetch data!
While the GPU are computing, a CPU thread will fetch the data for you.
A lot of frameworks implemented that for you because its a little bit painful!
Deep learning Frameworks
Its super fast moving!
Currently available frameworks:
Tensorflow (Google)
Caffe (UC Berkeley)
Caffe2 (Facebook)
Torch (NYU / Facebook)
PyTorch (Facebook)
Theano (U monteral)
Paddle (Baidu)
CNTK (Microsoft)
MXNet (Amazon)
The instructor thinks that you should focus on Tensorflow and PyTorch.
The point of deep learning frameworks:
Easily build big computational graphs.
Easily compute gradients in computational graphs.
Run it efficiently on GPU (cuDNN - cuBLAS)
Numpy doesn’t run on GPU.
Most of the frameworks tries to be like NUMPY in the forward pass and then they compute the gradients for you.
Tensorflow (Google)
Code are two parts:
Define computational graph.
Run the graph and reuse it many times.
Tensorflow uses a static graph architecture.
Tensorflow variables live in the graph. while the placeholders are feed each run.
Global initializer function initializes the variables that lives in the graph.
Use predefined optimizers and losses.
You can make a full layers with layers.dense function.
Keras (High level wrapper):
Keras is a layer on top pf Tensorflow, makes common things easy to do.
So popular!
Trains a full deep NN in a few lines of codes.
There are a lot high level wrappers:
Keras
TFLearn
TensorLayer
tf.layers #Ships with tensorflow
tf-Slim #Ships with tensorflow
tf.contrib.learn #Ships with tensorflow
Sonnet # New from deep mind
Tensorflow has pretrained models that you can use while you are using transfer learning.
Tensorboard adds logging to record loss, stats. Run server and get pretty graphs!
It has distributed code if you want to split your graph on some nodes.
Tensorflow is actually inspired from Theano. It has the same inspirations and structure.
PyTorch (Facebook)
Has three layers of abstraction:
Tensor: ndarray but runs on GPU #Like numpy arrays in tensorflow
Variable: Node in a computational graphs; stores data and gradient #Like Tensor, Variable, Placeholders
Module: A NN layer; may store state or learnable weights#Like tf.layers in tensorflow
In PyTorch the graphs runs in the same loop you are executing which makes it easier for debugging. This is called a dynamic graph.
In PyTorch you can define your own autograd functions by writing forward and backward for tensors. Most of the times it will implemented for you.
Torch.nn is a high level api like keras in tensorflow. You can create the models and go on and on.
You can define your own nn module!
Also Pytorch contains optimizers like tensorflow.
It contains a data loader that wraps a Dataset and provides minbatches, shuffling and multithreading.
PyTorch contains the best and super easy to use pretrained models
PyTorch contains Visdom that are like tensorboard. but Tensorboard seems to be more powerful.
PyTorch is new and still evolving compared to Torch. Its still in beta state.
PyTorch is best for research.
Tensorflow builds the graph once, then run them many times (Called static graph)
In each PyTorch iteration we build a new graph (Called dynamic graph)
Static vs dynamic graphs:
Optimization:
With static graphs, framework can optimize the graph for you before it runs.
Serialization
Static: Once graph is built, can serialize it and run it without the code that built the graph. Ex use the graph in c++
Dynamic: Always need to keep the code around.
Conditional
Is easier in dynamic graphs. And more complicated in static graphs.
Loops:
Is easier in dynamic graphs. And more complicated in static graphs.
Tensorflow fold make dynamic graphs easier in Tensorflow through dynamic batching.
Dynamic graph applications include: recurrent networks and recursive networks.
Caffe2 uses static graphs and can train model in python also works on IOS and Android
Tensorflow/Caffe2 are used a lot in production especially on mobile.
09. CNN architectures
This section talks about the famous CNN architectures. Focuses on CNN architectures that won ImageNet competition since 2012.
Also we will discuss some interesting architectures as we go.
The first ConvNet that was made was LeNet-5 architectures are:by Yann Lecun at 1998.
Architecture are: CONV-POOL-CONV-POOL-FC-FC-FC
Each conv filters was 5x5 applied at stride 1
Each pool was 2x2 applied at stride 2
It was useful in Digit recognition.
In particular the insight that image features are distributed across the entire image, and convolutions with learnable parameters are an effective way to extract similar features at multiple location with few parameters.
It contains exactly 5 layers
In 2010 Dan Claudiu Ciresan and Jurgen Schmidhuber published one of the very fist implementations of GPU Neural nets. This implementation had both forward and backward implemented on a a NVIDIA GTX 280 graphic processor of an up to 9 layers neural network.
Contains exactly 8 layers the first 5 are Convolutional and the last 3 are fully connected layers.
AlexNet accuracy error was 16.4%
For example if the input is 227 x 227 x3 then these are the shapes of the of the outputs at each layer:
CONV1 (96 11 x 11 filters at stride 4, pad 0)
Output shape (55,55,96), Number of weights are (11*11*3*96)+96 = 34944
MAXPOOL1 (3 x 3 filters applied at stride 2)
Output shape (27,27,96), No Weights
NORM1
Output shape (27,27,96), We don’t do this any more
CONV2 (256 5 x 5 filters at stride 1, pad 2)
MAXPOOL2 (3 x 3 filters at stride 2)
NORM2
CONV3 (384 3 x 3 filters ar stride 1, pad 1)
CONV4 (384 3 x 3 filters ar stride 1, pad 1)
CONV5 (256 3 x 3 filters ar stride 1, pad 1)
MAXPOOL3 (3 x 3 filters at stride 2)
Output shape (6,6,256)
FC6 (4096)
FC7 (4096)
FC8 (1000 neurons for class score)
Some other details:
First use of RELU.
Norm layers but not used any more.
heavy data augmentation
Dropout 0.5
batch size 128
SGD momentum 0.9
Learning rate 1e-2 reduce by 10 at some iterations
7 CNN ensembles!
AlexNet was trained on GTX 580 GPU with only 3 GB which wasn’t enough to train in one machine so they have spread the feature maps in half. The first AlexNet was distributed!
Its still used in transfer learning in a lot of tasks.
We show how a multiscale and sliding window approach can be efficiently implemented within a ConvNet. We also introduce a novel deep learning approach to localization by learning to predict object boundaries.
The great advantage of VGG was the insight that multiple 3 × 3 convolution in sequence can emulate the effect of larger receptive fields, for examples 5 × 5 and 7 × 7.
Used the simple 3 x 3 Conv all through the network.
3 (3 x 3) filters has the same effect as 7 x 7
The Architecture contains several CONV layers then POOL layer over 5 times and then the full connected layers.
It has a total memory of 96MB per image for only forward propagation!
Most memory are in the earlier layers
Total number of parameters are 138 million
Most of the parameters are in the fully connected layers
Has a similar details in training like AlexNet. Like using momentum and dropout.
VGG19 are an upgrade for VGG16 that are slightly better but with more memory
The bottleneck solution will make a total operations of 358M on this example which is good compared with the naive implementation.
So GoogleNet stacks this Inception module multiple times to get a full architecture of a network that can solve a problem without the Fully connected layers.
Just to mention, it uses an average pooling layer at the end before the classification step.
Full architecture:
In February 2015 Batch-normalized Inception was introduced as Inception V2. Batch-normalization computes the mean and standard-deviation of all feature maps at the output of a layer, and normalizes their responses with these values.
In December 2015 they introduced a paper “Rethinking the Inception Architecture for Computer Vision” which explains the older inception models well also introducing a new version V3.
The first GoogleNet and VGG was before batch normalization invented so they had some hacks to train the NN and converge well.
152-layer model for ImageNet. Winner by 3.57% which is more than human level error.
This is also the very first time that a network of > hundred, even 1000 layers was trained.
Swept all classification and detection competitions in ILSVRC’15 and COCO’15!
What happens when we continue stacking deeper layers on a “plain” Convolutional neural network?
The deeper model performs worse, but it’s not caused by overfitting!
The learning stops performs well somehow because deeper NN are harder to optimize!
The deeper model should be able to perform at least as well as the shallower model.
A solution by construction is copying the learned layers from the shallower model and setting additional layers to identity mapping.
Residual block:
Microsoft came with the Residual block which has this architecture:
* ```python
# Instead of us trying To learn a new representation, We learn only Residual
Y = (W2* RELU(W1x+b1) + b2) + X
```
*
* Say you have a network till a depth of N layers. You only want to add a new layer if you get something extra out of adding that layer.
* One way to ensure this new (N+1)th layer learns something new about your network is to also provide the input(x) without any transformation to the output of the (N+1)th layer. This essentially drives the new layer to learn something different from what the input has already encoded.
* The other advantage is such connections help in handling the Vanishing gradient problem in very deep networks.
With the Residual block we can now have a deep NN of any depth without the fearing that we can’t optimize the network.
ResNet with a large number of layers started to use a bottleneck layer similar to the Inception bottleneck to reduce the dimensions.
Full ResNet architecture:
Stack residual blocks.
Every residual block has two 3 x 3 conv layers.
Additional conv layer at the beginning.
No FC layers at the end (only FC 1000 to output classes)
Periodically, double number of filters and downsample spatially using stride 2 (/2 in each dimension)
Training ResNet in practice:
Batch Normalization after every CONV layer.
Xavier/2 initialization from He et al.
SGD + Momentum (0.9)
Learning rate: 0.1, divided by 10 when validation error plateaus
Mini-batch size 256
Weight decay of 1e-5
No dropout used.
Inception-v4: Resnet + Inception and was founded in 2016.
The complexity comparing over all the architectures:
VGG: Highest memory, most operations.
GoogLeNet: most efficient.
ResNets Improvements:
(2016) Identity Mappings in Deep Residual Networks
(2017) SqueezeNet: AlexNet-level Accuracy With 50x Fewer Parameters and <0.5Mb Model Size
Good for production.
It is a re-hash of many concepts from ResNet and Inception, and show that after all, a better design of architecture will deliver small network sizes and parameters without needing complex compression algorithms.
Conclusion:
ResNet current best default.
Trend towards extremely deep networks
In the last couple of years, some models all using the shortcuts like “ResNet” to eaisly flow the gradients.
10. Recurrent Neural networks
Vanilla Neural Networks “Feed neural networks”, input of fixed size goes through some hidden units and then go to output. We call it a one to one network.
Recurrent Neural Networks RNN Models:
One to many
Example: Image Captioning
image ==> sequence of words
Many to One
Example: Sentiment Classification
sequence of words ==> sentiment
Many to many
Example: Machine Translation
seq of words in one language ==> seq of words in another language
Example: Video classification on frame level
RNNs can also work for Non-Sequence Data (One to One problems)
It worked in Digit classification through taking a series of “glimpses”
Recurrent core cell that take an input x and that cell has an internal state that are updated each time it reads an input.
The RNN block should return a vector.
We can process a sequence of vectors x by applying a recurrence formula at every time step:
* ```python
h[t] = fw (h[t-1], x[t]) # Where fw is some function with parameters W
```
*
* The same function and the same set of parameters are used at every time step.
(Vanilla) Recurrent Neural Network:
* ```
h[t] = tanh (W[h,h]*h[t-1] + W[x,h]*x[t]) # Then we save h[t]
y[t] = W[h,y]*h[t]
```
*
* This is the simplest example of a RNN.
RNN works on a sequence of related data.
Recurrent NN Computational graph:
h0 are initialized to zero.
Gradient of W is the sum of all the W gradients that has been calculated!
A many to many graph:
Also the last is the sum of all losses and the weights of Y is one and is updated through summing all the gradients!
A many to one graph:
A one to many graph:
sequence to sequence graph:
Encoder and decoder philosophy.
Examples:
Suppose we are building words using characters. We want a model to predict the next character of a sequence. Lets say that the characters are only [h, e, l, o] and the words are [hello]
Training:
Only the third prediction here is true. The loss needs to be optimized.
We can train the network by feeding the whole word(s).
Testing time:
At test time we work with a character by character. The output character will be the next input with the other saved hidden activations.
This link contains all the code but uses Truncated Backpropagation through time as we will discuss.
Backpropagation through time Forward through entire sequence to compute loss, then backward through entire sequence to compute gradient.
But if we choose the whole sequence it will be so slow and take so much memory and will never converge!
So in practice people are doing “Truncated Backpropagation through time” as we go on we Run forward and backward through chunks of the sequence instead of whole sequence
Then Carry hidden states forward in time forever, but only backpropagate for some smaller number of steps.
Example on image captioning:
They use token to finish running.
The biggest dataset for image captioning is Microsoft COCO.
Image Captioning with Attention is a project in which when the RNN is generating captions, it looks at a specific part of the image not the whole image.
Image Captioning with Attention technique is also used in “Visual Question Answering” problem
Multilayer RNNs is generally using some layers as the hidden layer that are feed into again. LSTM is a multilayer RNNs.
Backward flow of gradients in RNN can explode or vanish. Exploding is controlled with gradient clipping. Vanishing is controlled with additive interactions (LSTM)
LSTM stands for Long Short Term Memory. It was designed to help the vanishing gradient problem on RNNs.
It consists of:
f: Forget gate, Whether to erase cell
i: Input gate, whether to write to cell
g: Gate gate (?), How much to write to cell
o: Output gate, How much to reveal cell
The LSTM gradients are easily computed like ResNet
The LSTM is keeping data on the long or short memory as it trains means it can remember not just the things from last layer but layers.
Highway networks is something between ResNet and LSTM that is still in research.
Better/simpler architectures are a hot topic of current research
Better understanding (both theoretical and empirical) is needed.
RNN is used for problems that uses sequences of related inputs more. Like NLP and Speech recognition.
11. Detection and Segmentation
So far we are talking about image classification problem. In this section we will talk about Segmentation, Localization, Detection.
Semantic Segmentation
We want to Label each pixel in the image with a category label.
As you see the cows in the image, Semantic Segmentation Don’t differentiate instances, only care about pixels.
The first idea is to use a sliding window. We take a small window size and slide it all over the picture. For each window we want to label the center pixel.
It will work but its not a good idea because it will be computational expensive!
Very inefficient! Not reusing shared features between overlapping patches.
In practice nobody uses this.
The second idea is designing a network as a bunch of Convolutional layers to make predictions for pixels all at once!
Input is the whole image. Output is the image with each pixel labeled.
We need a lot of labeled data. And its very expensive data.
It needs a deep Conv. layers.
The loss is cross entropy between each pixel provided.
Data augmentation are good here.
The problem with this implementation that convolutions at original image resolution will be very expensive.
So in practice we don’t see something like this right now.
The third idea is based on the last idea. The difference is that we are downsampling and upsampling inside the network.
We downsample because using the whole image as it is very expensive. So we go on multiple layers downsampling and then upsampling in the end.
Downsampling is an operation like Pooling and strided convolution.
Upsampling is like “Nearest Neighbor” or “Bed of Nails” or “Max unpooling”
* **Max unpooling** is depending on the earlier steps that was made by max pooling. You fill the pixel where max pooling took place and then fill other pixels by zero.
* Max unpooling seems to be the best idea for upsampling.
* There are an idea of Learnable Upsampling called "**Transpose Convolution**"
* Rather than making a convolution we make the reverse.
* Also called:
* Upconvolution.
* Fractionally strided convolution
* Backward strided convolution
* Learn the artimitic of the upsampling please refer to chapter 4 in this [paper](https://arxiv.org/abs/1603.07285).
Classification + Localization:
In this problem we want to classify the main object in the image and its location as a rectangle.
We assume there are one object.
We will create a multi task NN. The architecture are as following:
Convolution network layers connected to:
FC layers that classify the object. # The plain classification problem we know
FC layers that connects to a four numbers (x,y,w,h)
We treat Localization as a regression problem.
This problem will have two losses:
Softmax loss for classification
Regression (Linear loss) for the localization (L2 loss)
Loss = SoftmaxLoss + L2 loss
Often the first Conv layers are pretrained NNs like AlexNet!
This technique can be used in so many other problems like: Human Pose Estimation.
Object Detection
A core idea of computer vision. We will talk by details in this problem.
The difference between “Classification + Localization” and this problem is that here we want to detect one or mode different objects and its locations!
First idea is to use a sliding window
Worked well and long time.
The steps are:
Apply a CNN to many different crops of the image, CNN classifies each crop as object or background.
The problem is we need to apply CNN to huge number of locations and scales, very computationally expensive!
The brute force sliding window will make us take thousands of thousands of time.
Region Proposals will help us deciding which region we should run our NN at:
Find blobby image regions that are likely to contain objects.
Relatively fast to run; e.g. Selective Search gives 1000 region proposals in a few seconds on CPU
So now we can apply one of the Region proposals networks and then apply the first idea.
There is another idea which is called R-CNN
The idea is bad because its taking parts of the image -With Region Proposalsif different sizes and feed it to CNN after scaling them all to one size. Scaling is bad
Also its very slow.
Fast R-CNN is another idea that developed on R-CNN
It uses one CNN to do everything.
Faster R-CNN does its own region proposals by Inserting Region Proposal Network (RPN) to predict proposals from features.
The fastest of the R-CNNs.
Another idea is Detection without Proposals: YOLO / SSD
YOLO stands for you only look once.
YOLO/SDD is two separate algorithms.
Faster but not as accurate.
Takeaways
Faster R-CNN is slower but more accurate.
SSD/YOLO is much faster but not as accurate.
Denese Captioning
Denese Captioning is “Object Detection + Captioning”
Rather than we want to predict the bounding box, we want to know which pixel label but also distinguish them.
There are a lot of ideas.
There are a new idea “Mask R-CNN”
Like R-CNN but inside it we apply the Semantic Segmentation
There are a lot of good results out of this paper.
It sums all the things that we have discussed in this lecture.
Performance of this seems good.
12. Visualizing and Understanding
We want to know what’s going on inside ConvNets?
People want to trust the black box (CNN) and know how it exactly works and give and good decisions.
A first approach is to visualize filters of the first layer.
Maybe the shape of the first layer filter is 5 x 5 x 3, and the number of filters are 16. Then we will have 16 different “colored” filter images.
It turns out that these filters learns primitive shapes and oriented edges like the human brain does.
These filters really looks the same on each Conv net you will train, Ex if you tried to get it out of AlexNet, VGG, GoogleNet, or ResNet.
This will tell you what is the first convolution layer is looking for in the image.
We can visualize filters from the next layers but they won’t tell us anything.
Maybe the shape of the first layer filter is 5 x 5 x 20, and the number of filters are 16. Then we will have 16*20 different “gray” filter images.
In AlexNet, there was some FC layers in the end. If we took the 4096-dimensional feature vector for an image, and collecting these feature vectors.
If we made a nearest neighbors between these feature vectors and get the real images of these features we will get something very good compared with running the KNN on the images directly!
This similarity tells us that these CNNs are really getting the semantic meaning of these images instead of on the pixels level!
We can make a dimensionality reduction on the 4096 dimensional feature and compress it to 2 dimensions.
This can be made by PCA, or t-SNE.
t-SNE are used more with deep learning to visualize the data. Example can be found here.
We can Visualize the activation maps.
For example if CONV5 feature map is 128 x 13 x 13, We can visualize it as 128 13 x 13 gray-scale images.
One of these features are activated corresponding to the input, so now we know that this particular map are looking for something.
There are something called Maximally Activating Patches that can help us visualize the intermediate features in Convnets
The steps of doing this is as following:
We choose a layer then a neuron
Ex. We choose Conv5 in AlexNet which is 128 x 13 x 13 then pick channel (Neuron) 17/128
Run many images through the network, record values of chosen channel.
Visualize image patches that correspond to maximal activations.
We will find that each neuron is looking into a specific part of the image.
Extracted images are extracted using receptive field.
Another idea is Occlusion Experiments
We mask part of the image before feeding to CNN, draw heat-map of probability (Output is true) at each mask location
It will give you the most important parts of the image in which the Conv. Network has learned from.
Saliency Maps tells which pixels matter for classification
Like Occlusion Experiments but with a completely different approach
We Compute gradient of (unnormalized) class score with respect to image pixels, take absolute value and max over RGB channels. It will get us a gray image that represents the most important areas in the image.
This can be used for Semantic Segmentation sometimes.
(guided) backprop Makes something like Maximally Activating Patches but unlike it gets the pixels in which we are caring of.
In this technique choose a channel like Maximally Activating Patches and then compute gradient of neuron value with respect to image pixels
Images come out nicer if you only backprop positive gradients through each RELU (guided backprop)
Gradient Ascent
Generate a synthetic image that maximally activates a neuron.
Reverse of gradient decent. Instead of taking the minimum it takes the maximum.
We want to maximize the neuron with the input image. So here instead we are trying to learn the image that maximize the activation:
* ```python
# R(I) is Natural image regularizer, f(I) is the neuron value.
I *= argmax(f(I)) + R(I)
```
*
Steps of gradient ascent
Initialize image to zeros.
Forward image to compute current scores.
Backprop to get gradient of neuron value with respect to image pixels.
Make a small update to the image
R(I) may equal to L2 of generated image.
To get a better results we use a better regularizer:
penalize L2 norm of image; also during optimization periodically:
Gaussian blur image
Clip pixels with small values to 0
Clip pixels with small gradients to 0
A better regularizer makes out images cleaner!
The results in the latter layers seems to mean something more than the other layers.
We can fool CNN by using this procedure:
Start from an arbitrary image. # Random picture based on nothing.
Pick an arbitrary class. # Random class
Modify the image to maximize the class.
Repeat until network is fooled.
Results on fooling the network is pretty surprising!
For human eyes they are the same, but it fooled the network by adding just some noise!
DeepDream: Amplify existing features
Google released deep dream on their website.
What its actually doing is the same procedure as fooling the NN that we discussed, but rather than synthesizing an image to maximize a specific neuron, instead try to amplify the neuron activations at some layer in the network.
Steps:
Forward: compute activations at chosen layer. # form an input image (Any image)
Set gradient of chosen layer equal to its activation.
Equivalent to I* = arg max[I] sum(f(I)^2)
Backward: Compute gradient on image.
Update image.
The code of deep dream is online you can download and check it yourself.
Feature Inversion
Gives us to know what types of elements parts of the image are captured at different layers in the network.
Given a CNN feature vector for an image, find a new image that:
Matches the given feature vector.
looks natural (image prior regularization)
Texture Synthesis
Old problem in computer graphics.
Given a sample patch of some texture, can we generate a bigger image of the same texture?
There is an algorithm which doesn’t depend on NN:
Wei and Levoy, Fast Texture Synthesis using Tree-structured Vector Quantization, SIGGRAPH 2000
Its a really simple algorithm
The idea here is that this is an old problem and there are a lot of algorithms that has already solved it but simple algorithms doesn’t work well on complex textures!
An idea of using NN has been proposed on 2015 based on gradient ascent and called it “Neural Texture Synthesis”
It depends on something called Gram matrix.
Neural Style Transfer = Feature + Gram Reconstruction
Gatys, Ecker, and Bethge, Image style transfer using Convolutional neural networks, CVPR 2016
Clustering, dimensionality reduction, feature learning, density estimation
Autoencoders are a Feature learning technique.
It contains an encoder and a decoder. The encoder downsamples the image while the decoder upsamples the features.
The loss are L2 loss.
Density estimation is where we want to learn/estimate the underlaying distribution for the data!
There are a lot of research open problems in unsupervised learning compared with supervised learning!
Generative Models
Given training data, generate new samples from same distribution.
Addresses density estimation, a core problem in unsupervised learning.
We have different ways to do this:
Explicit density estimation: explicitly define and solve for the learning model.
Learn model that can sample from the learning model without explicitly defining it.
Why Generative Models?
Realistic samples for artwork, super-resolution, colorization, etc
Generative models of time-series data can be used for simulation and planning (reinforcement learning applications!)
Training generative models can also enable inference of latent representations that can be useful as general features
Taxonomy of Generative Models:
In this lecture we will discuss: PixelRNN/CNN, Variational Autoencoder, and GANs as they are the popular models in research now.
PixelRNN and PixelCNN
In a full visible belief network we use the chain rule to decompose likelihood of an image x into product of 1-d distributions
p(x) = sum(p(x[i]| x[1]x[2]....x[i-1]))
Where p(x) is the Likelihood of image x and x[i] is Probability of i’th pixel value given all previous pixels.
To solve the problem we need to maximize the likelihood of training data but the distribution is so complex over pixel values.
Also we will need to define ordering of previous pixels.
PixelRNN
Founded by [van der Oord et al. 2016]
Dependency on previous pixels modeled using an RNN (LSTM)
Generate image pixels starting from corner
Drawback: sequential generation is slow! because you have to generate pixel by pixel!
PixelCNN
Also Founded by [van der Oord et al. 2016]
Still generate image pixels starting from corner.
Dependency on previous pixels now modeled using a CNN over context region
Training is faster than PixelRNN (can parallelize convolutions since context region values known from training images)
Generation must still proceed sequentially still slow.
There are some tricks to improve PixelRNN & PixelCNN.
PixelRNN and PixelCNN can generate good samples and are still active area of research.
Autoencoders
Unsupervised approach for learning a lower-dimensional feature representation from unlabeled training data.
Consists of Encoder and decoder.
The encoder:
Converts the input x to the features z. z should be smaller than x to get only the important values out of the input. We can call this dimensionality reduction.
The encoder can be made with:
Linear or non linear layers (earlier days days)
Deep fully connected NN (Then)
RELU CNN (Currently we use this on images)
The decoder:
We want the encoder to map the features we have produced to output something similar to x or the same x.
The decoder can be made with the same techniques we made the encoder and currently it uses a RELU CNN.
The encoder is a conv layer while the decoder is deconv layer! Means Decreasing and then increasing.
The loss function is L2 loss function:
L[i] = |y[i] - y'[i]|^2
After training we though away the decoder.# Now we have the features we need
We can use this encoder we have to make a supervised model.
The value of this it can learn a good feature representation to the input you have.
A lot of times we will have a small amount of data to solve problem. One way to tackle this is to use an Autoencoder that learns how to get features from images and train your small dataset on top of that model.
The question is can we generate data (Images) from this Autoencoder?
Variational Autoencoders (VAE)
Probabilistic spin on Autoencoders - will let us sample from the model to generate data!
We have z as the features vector that has been formed using the encoder.
We then choose prior p(z) to be simple, e.g. Gaussian.
Reasonable for hidden attributes: e.g. pose, how much smile.
Conditional p(x|z) is complex (generates image) => represent with neural network
But we cant compute integral for P(z)p(x|z)dz as the following equation:
After resolving all the equations that solves the last equation we should get this:
Variational Autoencoder are an approach to generative models but Samples blurrier and lower quality compared to state-of-the-art (GANs)
Active areas of research:
More flexible approximations, e.g. richer approximate posterior instead of diagonal Gaussian
Incorporating structure in latent variables
Generative Adversarial Networks (GANs)
GANs don’t work with any explicit density function!
Instead, take game-theoretic approach: learn to generate from training distribution through 2-player game.
Yann LeCun, who oversees AI research at Facebook, has called GANs:
The coolest idea in deep learning in the last 20 years
Problem: Want to sample from complex, high-dimensional training distribution. No direct way to do this as we have discussed!
Solution: Sample from a simple distribution, e.g. random noise. Learn transformation to training distribution.
So we create a noise image which are drawn from simple distribution feed it to NN we will call it a generator network that should learn to transform this into the distribution we want.
Training GANs: Two-player game:
Generator network: try to fool the discriminator by generating real-looking images.
Discriminator network: try to distinguish between real and fake images.
If we are able to train the Discriminator well then we can train the generator to generate the right images.
The loss function of GANs as minimax game are here:
The label of the generator network will be 0 and the real images are 1.
To train the network we will do:
Gradient ascent on discriminator.
Gradient ascent on generator but with different loss.
You can read the full algorithm with the equations here:
Aside: Jointly training two networks is challenging, can be unstable. Choosing objectives with better loss landscapes helps training is an active area of research.
Convolutional Architectures:
Generator is an upsampling network with fractionally-strided convolutions Discriminator is a Convolutional network.
Guidelines for stable deep Conv GANs:
Replace any pooling layers with strided convs (discriminator) and fractional-strided convs with (Generator).
Use batch norm for both networks.
Remove fully connected hidden layers for deeper architectures.
Use RELU activation in generator for all layers except the output which uses Tanh
Use leaky RELU in discriminator for all the layers.
2017 is the year of the GANs! it has exploded and there are some really good results.
Active areas of research also is GANs for all kinds of applications.
Reinforcement learning problems are involving an agent interacting with an environment, which provides numeric reward signals.
Steps are:
Environment –> State s[t] –> Agent –> Action a[t] –> Environment –> Reward r[t] + Next state s[t+1] –> Agent –> and so on..
Our goal is learn how to take actions in order to maximize reward.
An example is Robot Locomotion:
Objective: Make the robot move forward
State: Angle and position of the joints
Action: Torques applied on joints
1 at each time step upright + forward movement
Another example is Atari Games:
Deep learning has a good state of art in this problem.
Objective: Complete the game with the highest score.
State: Raw pixel inputs of the game state.
Action: Game controls e.g. Left, Right, Up, Down
Reward: Score increase/decrease at each time step
Go game is another example which AlphaGo team won in the last year (2016) was a big achievement for AI and deep learning because the problem was so hard.
We can mathematically formulate the RL (reinforcement learning) by using Markov Decision Process
Markov Decision Process
Defined by (S, A, R, P, Y) where:
S: set of possible states.
A: set of possible actions
R: distribution of reward given (state, action) pair
P: transition probability i.e. distribution over next state given (state, action) pair
Y: discount factor # How much we value rewards coming up soon verses later on.
Algorithm:
At time step t=0, environment samples initial state s[0]
Then, for t=0 until done:
Agent selects action a[t]
Environment samples reward from R with (s[t], a[t])
Environment samples next state from P with (s[t], a[t])
Agent receives reward r[t] and next state s[t+1]
A policy pi is a function from S to A that specifies what action to take in each state.
The value function at state s, is the expected cumulative reward from following the policy from state s:
V[pi](s) = Sum(Y^t * r[t], t>0) given s0 = s, pi
The Q-value function at state s and action a, is the expected cumulative reward from taking action a in state s and then following the policy:
Q[pi](s,a) = Sum(Y^t * r[t], t>0) given s0 = s,a0 = a, pi
The optimal Q-value function Q* is the maximum expected cumulative reward achievable from a given (state, action) pair:
Q*[s,a] = Max(for all of pi on (Sum(Y^t * r[t], t>0) given s0 = s,a0 = a, pi))
Bellman equation
Important thing is RL.
Given any state action pair (s,a) the value of this pair is going to be the reward that you are going to get r plus the value of the state that you end in.
Q*[s,a] = r + Y * max Q*(s',a') given s,a # Hint there is no policy in the equation
The optimal policy pi* corresponds to taking the best action in any state as specified by Q*
We can get the optimal policy using the value iteration algorithm that uses the Bellman equation as an iterative update
Due to the huge space dimensions in real world applications we will use a function approximator to estimate Q(s,a). E.g. a neural network! this is called Q-learning
Any time we have a complex function that we cannot represent we use Neural networks!
Q-learning
The first deep learning algorithm that solves the RL.
Use a function approximator to estimate the action-value function
If the function approximator is a deep neural network => deep q-learning
The loss function:
Now lets consider the “Playing Atari Games” problem:
Our total reward are usually the reward we are seeing in the top of the screen.
Q-network Architecture:
Learning from batches of consecutive samples is a problem. If we recorded a training data and set the NN to work with it, if the data aren’t enough we will go to a high bias error. so we should use “experience replay” instead of consecutive samples where the NN will try the game again and again until it masters it.
Continually update a replay memory table of transitions (s[t] , a[t] , r[t] , s[t+1]) as game (experience) episodes are played.
Train Q-network on random minibatches of transitions from the replay memory, instead of consecutive samples.
If we need to continue Pruning we go to step 2 again else we stop.
Weight Sharing
The idea is that we want to make the numbers is our models less.
Trained Quantization:
Example: all weight values that are 2.09, 2.12, 1.92, 1.87 will be replaced by 2
To do that we can make k means clustering on a filter for example and reduce the numbers in it. By using this we can also reduce the number of operations that are used from calculating the gradients.
After Trained Quantization the Weights are Discrete.
Trained Quantization can reduce the number of bits we need for a number in each layer significantly.
Pruning + Trained Quantization can Work Together to reduce the size of the model.
Huffman Coding
We can use Huffman Coding to reduce/compress the number of bits of the weight.
In-frequent weights: use more bits to represent.
Frequent weights: use less bits to represent.
Using Pruning + Trained Quantization + Huffman Coding is called deep compression.
SqueezeNet
All the models we have talked about till now was using a pretrained models. Can we make a new arcitecutre that saves memory and computations?
SqueezeNet gets the alexnet accurecy with 50x fewer parameters and 0.5 model size.
SqueezeNet can even be further compressed by applying deep compression on them.
Models are now more energy efficient and has speed up a lot.
Deep compression was applied in Industry through facebook and Baidu.
Quantization
Algorithm (Quantizing the Weight and Activation):
Train with float.
Quantizing the weight and activation:
Gather the statistics for weight and activation.
Choose proper radix point position.
Fine-tune in float format.
Convert to fixed-point format.
Low Rank Approximation
Is another size reduction algorithm that are used for CNN.
Idea is decompose the conv layer and then try both of the composed layers.
Binary / Ternary Net
Can we only use three numbers to represent weights in NN?
The size will be much less with only -1, 0, 1.
This is a new idea that was published in 2017 “Zhu, Han, Mao, Dally. Trained Ternary Quantization, ICLR’17”
Works after training.
They have tried it on AlexNet and it has reached almost the same error as AlexNet.
Number of operation will increase per register: https://xnor.ai/
Winograd Transformation
Based on 3x3 WINOGRAD Convolutions which makes less operations than the ordiany convolution
cuDNN 5 uses the WINOGRAD Convolutions which has improved the speed.
Part 2: Hardware for Efficient Inference
There are a lot of ASICs that we developed for deep learning. All in which has the same goal of minimize memory access.
Eyeriss MIT
DaDiannao
TPU Google (Tensor processing unit)
It can be put to replace the disk in the server.
Up to 4 cards per server.
Power consumed by this hardware is a lot less than a GPU and the size of the chip is less.
EIE Standford
By Han at 2016 [et al. ISCA’16]
We don’t save zero weights and make quantization for the numbers from the hardware.
He says that EIE has a better Throughput and energy efficient.
Part 3: Algorithms for Efficient Training
Parallelization
Data Parallel–Run multiple inputs in parallel
Ex. Run two images in the same time!
Run multiple training examples in parallel.
Limited by batch size.
Gradients have to be applied by a master node.
Model Parallel
Split up the Model–i.e. the network
Split model over multiple processors By layer.
Hyper-Parameter Parallel
Try many alternative networks in parallel.
Easy to get 16-64 GPUs training one model in parallel.
Mixed Precision with FP16 and FP32
We have discussed that if we use 16 bit real numbers all over the model the energy cost will be less by x4.
Can we use a model entirely with 16 bit number? We can partially do this with mixed FP16 and FP32. We use 16 bit everywhere but at some points we need the FP32.
By example in multiplying FP16 by FP16 we will need FP32.
After you train the model you can be a near accuracy of the famous models like AlexNet and ResNet.
Model Distillation
The question is can we use a senior (Good) trained neural network(s) and make them guide a student (New) neural network?
For more information look at Hinton et al. Dark knowledge / Distilling the Knowledge in a Neural Network
DSD: Dense-Sparse-Dense Training
Han et al. “DSD: Dense-Sparse-Dense Training for Deep Neural Networks”, ICLR 2017
Has a better regularization.
The idea is Train the model lets call this the Dense, we then apply Pruning to it lets call this sparse.
DSD produces same model architecture but can find better optimization solution arrives at better local minima, and achieves higher prediction accuracy.
After the above two steps we go connect the remain connection and learn them again (To dense again).
This improves the performace a lot in many deep learning models.
Part 4: Hardware for Efficient Training
GPUs for training:
Nvidia PASCAL GP100 (2016)
Nvidia Volta GV100 (2017)
Can make mixed precision operations!
So powerful.
The new neclar bomb!
Google Announced “Google Cloud TPU” on May 2017!
Cloud TPU delivers up to 180 teraflops to train and run machine learning models.
One of our new large-scale translation models used to take a full day to train on 32 of the best commercially-available GPUs—now it trains to the same accuracy in an afternoon using just one eighth of a TPU pod.
We have moved from PC Era ==> Mobile-First Era ==> AI-First Era
16. Adversarial Examples and Adversarial Training
What are adversarial examples?
Since 2013, deep neural networks have matched human performance at..
Face recognition
Object recognition
Captcha recognition
Because its accuracy was higher than humans, Websites tried to find another solution than Captcha.
And other tasks..
Before 2013 no body was surprised if they saw a computer made a mistake! But now the deep learning exists and its so important to know the problems and the causes.
Adversarial are problems and unusual mistake that deep learning make.
This topic wasn’t hot until deep learning can now do better and better than human!
An adversarial is an example that has been carefully computed to to be misclassified.
In a lot of cases the adversarial image isn’t changed much compared to the original image from the human perspective.
So the first story was in 2013. When Szegedy had a CNN that can classify images very well.
He wanted to understand more about how CNN works to improve it.
He give an image of an object and by using gradient ascent he tried to update the images so that it can be another object.
Strangely he found that the result image hasn’t changed much from the human perspective!
If you tried it you won’t notify any change and you will think that this is a bug! but it isn’t if you go for the image you will notice that they are completely different!
These mistakes can be found in almost any deep learning algorithm we have studied!
It turns out that RBF (Radial Basis Network) can resist this.
Deep Models for Density Estimation can resist this.
Not just for neural nets can be fooled:
Linear models
Logistic regression
Softmax regression
SVMs
Decision trees
Nearest neighbors
Why do adversarial happen?
In the process in trying to understand what is happening, in 2016 they thought it was from overfitting models in the high dimensional data case.
Because in such high dimensions we could have some random errors which can be found.
So if we trained a model with another parameters it should not make the same mistake?
They found that not right. Models are reaching to the same mistakes so it doesn’t mean its overfitting.
In the previous mentioned experiment the found that the problem is caused by systematic thing not a random.
If they add some vector to an example it would misclassified to any model.
Maybe they are coming from underfitting not overfitting.
Modern deep nets are very piecewise linear
Rectified linear unit
Carefully tuned sigmoid # Most of the time we are inside the linear curve
Maxout
LSTM
Relation between the parameter and the output are non linear because it’s multiplied together thats what make training NN difficult, while mapping from linear from input and output are linear and much easier.
How can adversarial be used to compromise machine learning systems?
If we are experimenting how easy a NN to fool, We want to make sure we are actually fooling it not just changing the output class, and if we are attackers we want to make this behavior to the NN (Get hole).
When we build Adversarial example we use the max norm constrain to perturbation.
The fast gradient sign method:
This method comes from the fact that almost all NN are using a linear activations (Like RELU) the assumption we have told before.
No pixel can be changed more than some amount epsilon.
Fast way is to take the gradient of the cost you used to train the network with respect to the input and then take the sign of that gradient multiply this by epsilon.
Equation:
Xdash = x + epslion * (sign of the gradient)
Where Xdash is the adversarial example and x is the normal example
So it can be detected by just using the sign (direction) and some epsilon.
Some attacks are based on ADAM optimizer.
Adversarial examples are not random noises!
NN are trained on some distribution and behaves well in that distribution. But if you shift this distribution the NN won’t answer the right answers. They will be so easy to fool.
deep RL can also be fooled.
Attack of the weights:
In linear models, We can take the learned weights image, take the signs of the image and add it to any example to force the class of the weights to be true. Andrej Karpathy, “Breaking Linear Classifiers on ImageNet”
It turns out that some of the linaer models performs well (We cant get advertisal from them easily)
In particular Shallow RBFs network resist adversarial perturbation # By The fast gradient sign method
The problem is RBFs doesn’t get so much accuracy on the datasets because its just a shallow model and if you tried to get this model deeper the gradients will become zero in almost all the layers.
RBFs are so difficult to train even with batch norm. algorithm.
Ian thinks if we have a better hyper parameters or a better optimization algorithm that gradient decent we will be able to train RBFs and solve the adversarial problem!
We also can use another model to fool current model. Ex use an SVM to fool a deep NN.
For more details follow the paper: “Papernot 2016”
Transferability Attack
Target model with unknown weights, machine learning algorithm, training set; maybe non differentiable
Make your training set from this model using inputs from you, send them to the model and then get outputs from the model
Train you own model. “Following some table from Papernot 2016”
Create an Adversarial example on your model.
Use these examples against the model you are targeting.
You are almost likely to get good results and fool this target!
In Transferability Attack to increase your probability by 100% of fooling a network, You can make more than just one model may be five models and then apply them. “(Liu et al, 2016)”
Adversarial Examples are works for human brain also! for example images that tricks your eyes. They are a lot over the Internet.
In practice some researches have fooled real models from (MetaMind, Amazon, Google)
Someone has uploaded some perturbation into facebook and facebook was fooled :D
What are the defenses?
A lot of defenses Ian tried failed really bad! Including:
Ensembles
Weight decay
Dropout
Adding noise at train time or at test time
Removing perturbation with an autoencoder
Generative modeling
Universal approximator theorem
Whatever shape we would like our classification function to have a big enough NN can make it.
We could have train a NN that detects the Adversarial!
Linear models & KNN can be fooled easier than NN. Neural nets can actually become more secure than other models. Adversarial trained neural nets have the best empirical success rate on adversarial examples of any machine learning model.
Deep NNs can be trained with non linear functions but we will just need a good optimization technique or solve the problem with using such linear activator like “RELU”
How to use adversarial examples to improve machine learning, even when there is no adversary?
Universal engineering machine (model-based optimization) #Is called Universal engineering machine by Ian
For example:
Imagine that we want to design a car that are fast.
We trained a NN to look at the blueprints of a car and tell us if the blueprint will make us a fast car or not.
The idea here is to optimize the input to the network so that the output will max this could give us the best blueprint for a car!
Make new inventions by finding input that maximizes model’s predicted performance.
Right now by using adversarial examples we are just getting the results we don’t like but if we have solve this problem we can have the fastest car, the best GPU, the best chair, new drugs…..
The whole adversarial is an active area of research especially defending the network!
Conclusion
Attacking is easy
Defending is difficult
Adversarial training provides regularization and semi-supervised learning
The out-of-domain input problem is a bottleneck for model-based optimization generally
There are a Github code that can make you learn everything about adversarial by code (Built above tensorflow):
Himanshu Singh & Yunis Ahmad Lone, Deep Neuro-Fuzzy Systems With Python: With Case Studies and Applications From the Industry [website][python download]
Hung T. Nguyen & Nadipuram R. Prasad & Carol L. Walker & Elbert A. Walker, A First Course in Fuzzy and Neural Control [website]
Referensi Tambahan
Roland S Burns, Advanced Control Engineering (Chapter 10) [website]
Ali Zilouchian & Mo Jamshidi, Intelligent Control Systems Using Soft Computing Methodologies, [website][ebook download]
Adrian A. Hopgood, Intelligent Systems for Engineers and Scientists, websites
Adedeji Bodunde Badiru, Fuzzy Engineering Expert Systems With Neural Network Applications
Ahmad M. Ibrahim, Fuzzy Logic for Embedded Systems Applications [website]
Erdal Kayacan & Mojtaba Ahmadieh, Fuzzy Neural Networks for Real Time Control Applications: Concepts, Modeling and Algorithms for Fast Learning [website]
James M. Keller & Derong Liu & David B Fogel, Fundamentals of Computational Intelligence: Neural Networks, Fuzzy Systems, and Evolutionary Computation [website]
Steven L Brunton & J Nathan Kutz, Data-Driven Science and Engineering: Machine Learning, Dynamical Systems, and Control [website][ebook download][MATLAB Codeand Data][Python Codeand Data]
Selanjutnya anda akan berinteraksi dengan Jupyter Notebook di ICCT
Klik folder ICCT pada Jupyter Notebook, lalu klik Table-of-Contents-ICCT.ipynb
Klik salah satu link, misalnya 1.1.1 Complex Numbers in Cartesian Form di folder 1.1 Complex Numbers
Pada link tersebut, anda berada di Jupyter Notebook M-01_Complex_numbers_Cartesian_form.ipynb
Tidak perlu terlalu panik dengan kode Python yang muncul.
Pilih menu lalu
Silakan baca Notebook-nya, pahami penjelasan atau penugasannya.
Lalu anda secara interaktif melakukan pengubahan berbagai menu di dalam Notebook.
Anda dapat pula unduh atau screenshoot citranya.
Jika sudah cukup dan selesai, pilih menu lalu untuk mematikan Jupyter Notebook. Biasakan untuk melakukan hal ini setiap kali selesai bekerja dengan Jupyter Notebook.
A computer program is said to learn from experience E with respect to some task T and some performance measure P if its performance on T, as measured by P, improves with experience E. Suppose we feed a learning algorithm a lot of historical weather data, and have it learn to predict weather. What would be a reasonable choice for P?
🗹 The probability of it correctly predicting a future date’s weather.
☐ The weather prediction task.
☐ The process of the algorithm examining a large amount of historical weather data.
☐ None of these.
A computer program is said to learn from experience E with respect to some task T and some performance measure P if its performance on T, as measured by P, improves with experience E. Suppose we feed a learning algorithm a lot of historical weather data, and have it learn to predict weather. In this setting, what is T?
🗹 The weather prediction task.
☐ None of these.
☐ The probability of it correctly predicting a future date’s weather.
☐ The process of the algorithm examining a large amount of historical weather data.
Suppose you are working on weather prediction, and use a learning algorithm to predict tomorrow’s temperature (in degrees Centigrade/Fahrenheit).
Would you treat this as a classification or a regression problem?
🗹 Regression
☐ Classification
Suppose you are working on weather prediction, and your weather station makes one of three predictions for each day’s weather: Sunny, Cloudy or Rainy. You’d like to use a learning algorithm to predict tomorrow’s weather.
Would you treat this as a classification or a regression problem?
☐ Regression
🗹 Classification
Suppose you are working on stock market prediction, and you would like to predict the price of a particular stock tomorrow (measured in dollars). You want to use a learning algorithm for this.
Would you treat this as a classification or a regression problem?
🗹 Regression
☐ Classification
Suppose you are working on stock market prediction. You would like to predict whether or not a certain company will declare bankruptcy within the next 7 days (by training on data of similar companies that had previously been at risk of bankruptcy).
Would you treat this as a classification or a regression problem?
Regression
🗹 Classification
Suppose you are working on stock market prediction, Typically tens of millions of shares of Microsoft stock are traded (i.e., bought/sold) each day. You would like to predict the number of Microsoft shares that will be traded tomorrow.
Would you treat this as a classification or a regression problem?
🗹 Regression
Classification
Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case, assume some appropriate dataset is available for your algorithm to learn from.
🗹 Given historical data of children’s ages and heights, predict children’s height as a function of their age.
🗹 Given 50 articles written by male authors, and 50 articles written by female authors, learn to predict the gender of a new manuscript’s author (when the identity of this author is unknown).
Take a collection of 1000 essays written on the US Economy, and find a way to automatically group these essays into a small number of groups of essays that are somehow “similar” or “related”.
Examine a large collection of emails that are known to be spam email, to discover if there are sub-types of spam mail.
Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case, assume some appropriate dataset is available for your algorithm to learn from.
☐ Given data on how 1000 medical patients respond to an experimental drug (such as effectiveness of the treatment, side effects, etc.), discover whether there are different categories or “types” of patients in terms of how they respond to the drug, and if so what these categories are.
☐ Given a large dataset of medical records from patients suffering from heart disease, try to learn whether there might be different clusters of such patients for which we might tailor separate treatments.
🗹 Have a computer examine an audio clip of a piece of music, and classify whether or not there are vocals (i.e., a human voice singing) in that audio clip, or if it is a clip of only musical instruments (and no vocals).
🗹 Given genetic (DNA) data from a person, predict the odds of him/her developing diabetes over the next 10 years.
Some of the problems below are best addressed using a supervised learning algorithm, and the others with an unsupervised learning algorithm. Which of the following would you apply supervised learning to? (Select all that apply.) In each case, assume some appropriate dataset is available for your algorithm to learn from.
☐ Take a collection of 1000 essays written on the US Economy, and find a way to automatically group these essays into a small number of groups of essays that are somehow “similar” or “related”.
🗹 Given genetic (DNA) data from a person, predict the odds of him/her developing diabetes over the next 10 years.
☐ Examine a large collection of emails that are known to be spam email, to discover if there are sub-types of spam mail.
🗹 Examine the statistics of two football teams, and predict which team will win tomorrow’s match (given historical data of teams’ wins/losses to learn from).
Which of these is a reasonable definition of machine learning?
☐ Machine learning is the science of programming computers.
☐ Machine learning learns from labeled data.
☐ Machine learning is the field of allowing robots to act intelligently.
🗹 Machine learning is the field of study that gives computers the ability to learn without being explicitly programmed.
Linear Regression with One Variable :
Consider the problem of predicting how well a student does in her second year of college/university, given how well she did in her first year. Specifically, let x be equal to the number of “A” grades (including A-. A and A+ grades) that a student receives in their first year of college (freshmen year). We would like to predict the value of y, which we define as the number of “A” grades they get in their second year (sophomore year).
Here each row is one training example. Recall that in linear regression, our hypothesis is $h_\theta(x)=\theta_0+\theta_1x$ to denote the number of training examples.
For the training set given above (note that this training set may also be referenced in other questions in this $m$)? In the box below, please enter your answer (which should be a number between 0 and 10).
4
Many substances that can burn (such as gasoline and alcohol) have a chemical structure based on carbon atoms; for this reason they are called hydrocarbons. A chemist wants to understand how the number of carbon atoms in a molecule affects how much energy is released when that molecule combusts (meaning that it is burned). The chemist obtains the dataset below. In the column on the right, “kJ/mol” is the unit measuring the amount of energy released.
You would like to use linear regression $h_\theta(x) = \theta_0 + \theta_1x$ to estimate the amount of energy released (y) as a function of the number of carbon atoms (x). Which of the following do you think will be the values you obtain for $\theta_0$ and $\theta_1$ ? You should be able to select the right answer without actually implementing linear regression.
☐ $\theta_0$ = −569.6, $\theta_1$ = 530.9
☐ $\theta_0$ = −1780.0, $\theta_1$ = −530.9
🗹 $\theta_0$ = −569.6, $\theta_1$ = −530.9
☐ $\theta_0$ = −1780.0, $\theta_1$ = 530.9
For this question, assume that we are using the training set from Q1.
Recall our definition of the cost function was $J(\theta_0, \theta_1 ) = \frac{1}{2m} \sum_{i=1}^{m} (h (x^{(i)} ) - y^{(i)})^2$
What is $J(0,1)$? In the box below,
please enter your answer (Simplify fractions to decimals when entering answer, and ‘.’ as the decimal delimiter e.g., 1.5).
0.5
Suppose we set $\theta_0 = 0, \theta_1 = 1.5$ in the linear regression hypothesis from Q1. What is $h_\theta(2)$ ?
3
Suppose we set $\theta_0 = -2, \theta_1 = 0.5$ in the linear regression hypothesis from Q1. What is $h_\theta(6)$?
1
Let $f$ be some function so that $f(\theta_0 , \theta_1 )$ outputs a number. For this problem, f is some arbitrary/unknown smooth function (not necessarily the cost function of linear regression, so f may have local optima).
Suppose we use gradient descent to try to minimize $f(\theta_0 , \theta_1 )$ as a function of $\theta_0$ and $\theta_1$.
Which of the following statements are true? (Check all that apply.)
🗹 If $\theta_0$ and $\theta_1$ are initialized at the global minimum, then one iteration will not change their values.
☐ Setting the learning rate $\alpha$ to be very small is not harmful, and can only speed up the convergence of gradient descent.
☐ No matter how $\theta_0$ and $\theta_1$ are initialized, so long as $\alpha$ is sufficiently small, we can safely expect gradient descent to converge to the same solution.
🗹 If the first few iterations of gradient descent cause $f(\theta_0 , \theta_1)$ to increase rather than decrease, then the most likely cause is that we have set the learning rate $\alpha$ to too large a value.
In the given figure, the cost function $J(\theta_0, \theta_1)$ has been plotted against $\theta_0$ and $\theta_1$, as shown in ‘Plot 2’. The contour plot for the same cost function is given in ‘Plot 1’. Based on the figure, choose the correct options (check all that apply).
☐ If we start from point B, gradient descent with a well-chosen learning rate will eventually help us reach at or near point A, as the value of cost function $J(\theta_0, \theta_1)$ is maximum at point A.
☐ If we start from point B, gradient descent with a well-chosen learning rate will eventually help us reach at or near point C, as the value of cost function $J(\theta_0, \theta_1)$ is minimum at point C.
🗹 Point P (the global minimum of plot 2) corresponds to point A of Plot 1.
🗹 If we start from point B, gradient descent with a well-chosen learning rate will eventually help us reach at or near point A, as the value of cost function $J(\theta_0, \theta_1)$ is minimum at A.
☐ Point P (The global minimum of plot 2) corresponds to point C of Plot 1.
Suppose that for some linear regression problem (say, predicting housing prices as in the lecture), we have some training set, and for our training set we managed to find some $\theta_0, \theta_1$, such that $J(\theta_0 , \theta_1) = 0$.
Which of the statements below must then be true? (Check all that apply.)
☐ Gradient descent is likely to get stuck at a local minimum and fail to find the global minimum.
☐ For this to be true, we must have $\theta_0 = 0$ and $\theta_1 = 0$
so that $h_{\theta}(x) = 0$
☐ For this to be true, we must have $y^{(i)} = 0$ for every value of $i = 1, 2,…,m$.
🗹 Our training set can be fit perfectly by a straight line, i.e., all of our training examples lie perfectly on some straight line.
Week 4
Logistic Regression :
Suppose that you have trained a logistic regression classifier, and it outputs on a new example a prediction $h_\theta(x) = 0.2$. This means (check all that apply):
☐ Our estimate for P(y = 1|x; θ) is 0.8.
🗹 Our estimate for P(y = 0|x; θ) is 0.8.
🗹 Our estimate for P(y = 1|x; θ) is 0.2.
☐ Our estimate for P(y = 0|x; θ) is 0.2.
Suppose you have the following training set, and fit a logistic regression classifier $h_\theta(x) = g(\theta_0 + \theta_1x_1 + \theta_2x_2)$.
Which of the following are true? Check all that apply.
🗹 Adding polynomial features (e.g., instead using $h_\theta(x) = g(\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1^2 + \theta_4 x_1 x_2 + \theta_5 x_2^2 ))$ could increase how well we can fit the training data.
🗹 At the optimal value of θ (e.g., found by fminunc), we will have $J(θ) ≥ 0$.
☐ Adding polynomial features (e.g., instead using $h_\theta(x) = g(\theta_0 + \theta_1 x_1 + \theta_2 x_2 + \theta_3 x_1^2 + \theta_4 x_1 x_2 + \theta_5 x_2^2 ))$ would increase $J(θ)$ because we are now summing over more terms.
☐ If we train gradient descent for enough iterations, for some examples $x^{(i)}$ in the training set it is possible to obtain $h_\theta(x^{(i)} ) > 1$.
For logistic regression, the gradient is given by $\frac{\partial }{\partial \theta_j } J(\theta) = \frac{1}{m} \sum_{i=1}^{m}(h_\theta(x^{(i)})-y^{i})x^{(i)}_j$. Which of these is a correct gradient descent update for logistic regression with a learning rate of $\alpha$ ? Check all that apply.
🗹 $\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m (h_\theta(x^{(i)-y^i}) x^{(i)}_j$ (simultaneously update for all j).
🗹 $\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m \left(\frac{1}{1+e^{-\theta^Tx^{(i)}}}-y^{(i)}\right) x^{(i)}_j$ (simultaneously update for all j).
☐ $\theta_j := \theta_j - \alpha \frac{1}{m} \sum_{i=1}^m (h_\theta(x^{(i)-y^i}) x^{(i)}$ (simultaneously update for all j).
Which of the following statements are true? Check all that apply.
🗹 The one-vs-all technique allows you to use logistic regression for problems in which each $y^{(i)}$ comes from a fixed, discrete set of values.
☐ For logistic regression, sometimes gradient descent will converge to a local minimum (and fail to find the global minimum). This is the reason we prefer more advanced optimization algorithms such as fminunc (conjugate gradient/BFGS/L-BFGS/etc).
🗹 The cost function $J(\theta)$ for logistic regression trained with $m \geq 1$ examples is always greater than or equal to zero.
☐ Since we train one classifier when there are two classes, we train two classifiers when there are three classes (and we do one-vs-all classification).
Suppose you train a logistic classifier $h_\theta(x) = g(\theta_0 + \theta_1x_1 + \theta_2x_2)$. Suppose $\theta_0 = 6$, $\theta_1 = -1$, $\theta_2 = 0$. Which of the following figures represents the decision boundary found by your classifier?
🗹 Figure:
☐ Figure:
☐ Figure:
☐ Figure:
Regularization
You are training a classification model with logistic regression. Which of the following statements are true? Check all that apply.
☐ Introducing regularization to the model always results in equal or better performance on the training set.
☐ Introducing regularization to the model always results in equal or better performance on examples not in the training set.
🗹 Adding a new feature to the model always results in equal or better performance on the training set.
☐ Adding many new features to the model helps prevent overfitting on the training set.
Suppose you ran logistic regression twice, once with $\lambda = 0$, and once with $\lambda = 1$. One of the times, you got parameters $\theta = \begin{bmatrix} 74.81\ 45.05 \end{bmatrix}$, and the other time you got $\theta = \begin{bmatrix} 1.37\ 0.51 \end{bmatrix}$. However, you forgot which value of $\lambda$ corresponds to which value of $\theta$. Which one do you think corresponds to $\lambda = 1$?
Which of the following statements about regularization are true? Check all that apply.
☐ Using a very large value of $\lambda$ hurt the performance of your hypothesis; the only reason we do not set $\lambda$ to be too large is to avoid numerical problems.
☐ Because logistic regression outputs values $0 \leq h_\theta(x) \leq 1$, its range of output values can only be “shrunk” slightly by regularization anyway, so regularization is generally not helpful for it.
🗹 Consider a classification problem. Adding regularization may cause your classifier to incorrectly classify some training examples (which it had correctly classified when not using regularization, i.e. when $\lambda = 0$).
☐ Using too large a value of $\lambda$ can cause your hypothesis to overfit the data; this can be avoided by reducing $\lambda$.
Which of the following statements about regularization are true? Check all that apply.
☐ Using a very large value of $\lambda$ hurt the performance of your hypothesis; the only reason we do not set $\lambda$ to be too large is to avoid numerical problems.
☐ Because logistic regression outputs values $0 \leq h_\theta(x) \leq 1$, its range of output values can only be “shrunk” slightly by regularization anyway, so regularization is generally not helpful for it.
☐ Because regularization causes $J(\theta)$ to no longer be convex, gradient descent may not always converge to the global minimum (when $\lambda > 0$, and when using an appropriate learning rate $\alpha$).
🗹 Using too large a value of $\lambda$ can cause your hypothesis to underfit the data; this can be avoided by reducing $\lambda$.
In which one of the following figures do you think the hypothesis has overfit the training set?
🗹 Figure:
☐ Figure:
☐ Figure:
☐ Figure:
In which one of the following figures do you think the hypothesis has underfit the training set?
🗹 Figure:
☐ Figure:
☐ Figure:
☐ Figure:
Week 5
Neural Networks - Representation :
Which of the following statements are true? Check all that apply.
🗹 Any logical function over binary-valued (0 or 1) inputs $x_1$ and $x_2$ can be (approximately) represented using some neural network.
☐ Suppose you have a multi-class classification problem with three classes, trained with a 3 layer network. Let $a^{(3)}1 = (h\theta(x))_1$ be the activation of the first output unit, and similarly $a^{(3)}2 = (h\theta(x))_2$ and $a^{(3)}3 = (h\theta(x))_3$. Then for any input x, it must be the case that $a^{(3)}_1 + a^{(3)}_2 + a^{(3)}_3 = 1$.
☐ A two layer (one input layer, one output layer; no hidden layer) neural network can represent the XOR function.
🗹 The activation values of the hidden units in a neural network, with the sigmoid activation function applied at every layer, are always in the range (0, 1).
Consider the following neural network which takes two binary-valued inputs
$x_1,x_2 \ \epsilon \ {0,1}$ and outputs $h_\theta(x)$. Which of the following logical functions does it (approximately) compute?
🗹 AND
☐ NAND (meaning “NOT AND”)
☐ OR
☐ XOR (exclusive OR)
Consider the following neural network which takes two binary-valued inputs
$x_1,x_2 \ \epsilon \ {0,1}$ and outputs $h_\theta(x)$. Which of the following logical functions does it (approximately) compute?
☐ AND
☐ NAND (meaning “NOT AND”)
🗹 OR
☐ XOR (exclusive OR)
Consider the neural network given below. Which of the following equations correctly computes the activation $a_1^{(3)}$? Note: $g(z)$ is the sigmoid activation function.
You have the following neural network:
You’d like to compute the activations of the hidden layer $a^{(2)} \ \epsilon \ R^3$. One way to do
so is the following Octave code:
You want to have a vectorized implementation of this (i.e., one that does not use for loops). Which of the following implementations correctly compute ? Check all
that apply.
🗹 z = Theta1 * x; a2 = sigmoid (z);
☐ a2 = sigmoid (x * Theta1);
☐ a2 = sigmoid (Theta2 * x);
☐ z = sigmoid(x); a2 = sigmoid (Theta1 * z);
You are using the neural network pictured below and have learned the parameters $\theta^{(1)} = \begin{bmatrix} 1 & 1 & 2.4\ 1 & 1.7 & 3.2 \end{bmatrix}$ (used to compute $a^{(2)}$) and $\theta^{(2)} = \begin{bmatrix} 1 & 0.3 & -1.2 \end{bmatrix}$ (used to compute $a^{(3)}$ as a function of $a^{(2)}$). Suppose you swap the parameters for the first hidden layer between its two units so $\theta^{(1)} = \begin{bmatrix} 1 & 1.7 & 3.2 \ 1 & 1 & 2.4 \end{bmatrix}$ and also swap the output layer so $\theta^{(2)} = \begin{bmatrix} 1 & -1.2 & 0.3 \end{bmatrix}$. How will this change the value of the output $h_\theta(x)$?
🗹 It will stay the same.
☐ It will increase.
☐ It will decrease
☐ Insufficient information to tell: it may increase or decrease.
Neural Networks: Learning :
You are training a three layer neural network and would like to use backpropagation to compute the gradient of the cost function. In the backpropagation algorithm, one of the steps is to update $\Delta_{ij}^{(2)} := \Delta_{ij}^{(2)} + \delta_i^{(3)} * (a^{(2)})_j$
for every i,j. Which of the following is a correct vectorization of this step?
Suppose Theta1 is a 5x3 matrix, and Theta2 is a 4x6 matrix. You set thetaVec = [Theta1( : ), Theta2( : )]. Which of the following correctly recovers ?
🗹 reshape(thetaVec(16 : 39), 4, 6)
☐ reshape(thetaVec(15 : 38), 4, 6)
☐ reshape(thetaVec(16 : 24), 4, 6)
☐ reshape(thetaVec(15 : 39), 4, 6)
☐ reshape(thetaVec(16 : 39), 6, 4)
Let $J(\theta) = 2\theta^3 + 2$. Let $\theta = 1$, and $\epsilon = 0.01$. Use the formula $\frac{J{(\theta + \epsilon)}-J{(\theta - \epsilon)}}{2\epsilon}$ to numerically compute an approximation to the derivative at $\theta = 1$. What value do you get? (When $\theta = 1$, the true/exact derivative is $\frac{\mathrm{d} J(\theta)}{\mathrm{d} \theta} = 6$.)
☐ 8
🗹 6.0002
☐ 6
☐ 5.9998
Which of the following statements are true? Check all that apply.
🗹 For computational efficiency, after we have performed gradient checking to verify that our backpropagation code is correct, we usually disable gradient checking before using backpropagation to train the network.
☐ Computing the gradient of the cost function in a neural network has the same efficiency when we use backpropagation or when we numerically compute it using the method of gradient checking.
🗹 Using gradient checking can help verify if one’s implementation of backpropagation is bug-free.
☐ Gradient checking is useful if we are using one of the advanced optimization methods (such as in fminunc) as our optimization algorithm. However, it serves little purpose if we are using gradient descent.
Which of the following statements are true? Check all that apply.
🗹 If we are training a neural network using gradient descent, one reasonable “debugging” step to make sure it is working is to plot $J(\theta)$ as a function of the number of iterations, and make sure it is decreasing (or at least non-increasing) after each iteration.
☐ Suppose you have a three layer network with parameters $\theta^{(1)}$ (controlling the function mapping from the inputs to the hidden units) and $\theta^{(2)}$ (controlling the mapping from the hidden units to the outputs). If we set all the elements of $\theta^{(1)}$ to be 0, and all the elements of $\theta^{(2)}$ to be 1, then this suffices for symmetry breaking, since the neurons are no longer all computing the same function of the input.
🗹 Suppose you are training a neural network using gradient descent. Depending on your random initialization, your algorithm may converge to different local optima (i.e., if you run the algorithm twice with different random initializations, gradient descent may converge to two different solutions).
☐ If we initialize all the parameters of a neural network to ones instead of zeros, this will suffice for the purpose of “symmetry breaking” because the parameters are no longer symmetrically equal to zero.
Week 6
Advice for Applying Machine Learning :
You train a learning algorithm, and find that it has unacceptably high error on the test set. You plot the learning curve, and obtain the figure below. Is the algorithm suffering from high bias, high variance, or neither?
☐ High variance
☐ Neither
🗹 High bias
You train a learning algorithm, and find that it has unacceptably high error on the test set. You plot the learning curve, and obtain the figure below. Is the algorithm suffering from high bias, high variance, or neither?
🗹 High variance
☐ Neither
☐ High bias
Suppose you have implemented regularized logistic regression to classify what object is in an image (i.e., to do object recognition). However, when you test your hypothesis on a new set of images, you find that it makes unacceptably large errors with its predictions on the new images. However, your hypothesis performs well (has low error) on the training set. Which of the following are promising steps to take? Check all that apply.
NOTE: Since the hypothesis performs well (has low error) on the training set, it is suffering from high variance (overfitting)
☐ Try adding polynomial features.
☐ Use fewer training examples.
🗹 Try using a smaller set of features.
🗹 Get more training examples.
☐ Try evaluating the hypothesis on a cross validation set rather than the test set.
☐ Try decreasing the regularization parameter λ.
🗹 Try increasing the regularization parameter λ.
Suppose you have implemented regularized logistic regression to predict what items customers will purchase on a web shopping site. However, when you test your hypothesis on a new set of customers, you find that it makes unacceptably large errors in its predictions. Furthermore, the hypothesis performs poorly on the training set. Which of the following might be promising steps to take? Check all that apply.
NOTE: Since the hypothesis performs poorly on the training set, it is suffering from high bias (underfitting)
☐ Try increasing the regularization parameter λ.
🗹 Try decreasing the regularization parameter λ.
☐ Try evaluating the hypothesis on a cross validation set rather than the test set.
☐ Use fewer training examples.
🗹 Try adding polynomial features.
☐ Try using a smaller set of features.
🗹 Try to obtain and use additional features.
Which of the following statements are true? Check all that apply.
☐ Suppose you are training a regularized linear regression model. The recommended way to choose what value of regularization parameter to use is to choose the value of which gives the lowest test set error.
☐ Suppose you are training a regularized linear regression model.The recommended way to choose what value of regularization parameter to use is to choose the value of which gives the lowest training set error.
🗹 The performance of a learning algorithm on the training set will typically be better than its performance on the test set.
🗹 Suppose you are training a regularized linear regression model. The recommended way to choose what value of regularization parameter to use is to choose the value of which gives the lowest cross validation error.
🗹 A typical split of a dataset into training, validation and test sets might be 60% training set, 20% validation set, and 20% test set.
☐ Suppose you are training a logistic regression classifier using polynomial features and want to select what degree polynomial (denoted in the lecture videos) to use. After training the classifier on the entire training set, you decide to use a subset of the training examples as a validation set. This will work just as well as having a validation set that is separate (disjoint) from the training set.
☐ It is okay to use data from the test set to choose the regularization parameter λ, but not the model parameters (θ).
🗹 Suppose you are using linear regression to predict housing prices, and your dataset comes sorted in order of increasing sizes of houses. It is then important to randomly shuffle the dataset before splitting it into training, validation and test sets, so that we don’t have all the smallest houses going into the training set, and all the largest houses going into the test set.
Which of the following statements are true? Check all that apply.
🗹 A model with more parameters is more prone to overfitting and typically has higher variance.
☐ If the training and test errors are about the same, adding more features will not help improve the results.
🗹 If a learning algorithm is suffering from high bias, only adding more training examples may not improve the test error significantly.
🗹 If a learning algorithm is suffering from high variance, adding more training examples is likely to improve the test error.
🗹 When debugging learning algorithms, it is useful to plot a learning curve to understand if there is a high bias or high variance problem.
☐ If a neural network has much lower training error than test error, then adding more layers will help bring the test error down because we can fit the test set better.
Kalman and Bayesian Filters in Python. A textbook and accompanying filtering library on the topic of Kalman filtering and other related Bayesian filtering techniques.
Classify human movements using Dynamic Time Warping & K Nearest Neighbors: Signals from a smart phone gyroscope and accelerometer are used to classify if the person is running, walking, sitting standing etc. This IPython notebook contains a python implementation of DTW and KNN algorithms along with explanations and a practical application.
Signal: Filtering, STFT, and Laplace Transform Filtering signal with a butterworth low-pass filter and plotting the STFT of it with a Hanning window and then plotting the Laplace transform.
Anda akan berinteraksi dengan Jupyter Notebook di ICCT
Klik folder ICCT pada Jupyter Notebook, lalu klik Table-of-Contents-ICCT.ipynb
Klik kanan, open di new tab file Link 1.1.1 Complex Numbers in Cartesian Form di folder 1.1 Complex Numbers
Anda berada di Jupyter Notebook M-01_Complex_numbers_Cartesian_form.ipynb
Pilih menu lalu
Silakan baca Notebook-nya, baca penjelasan atau penugasaannya.
Lalu anda ubah nilai bilangan kompleksnya, tekan atau
Lalu anda variasikan operasinya seperti , dll.
Anda bisa unduh atau screenshoot citranya.
Pilih menu lalu untuk mematikan Jupyter Notebook.
Tugas (dengan waktu 2 pekan)
Sesuai dengan distribusi (terlampir di Eldiru), lakukan hal sebagai berikut:
Jalankan berkas Jupyter Notebook sebagaimana yang didistribusikan kepada anda.
Untuk setiap berkas Jupyter Notebook buat laporan mini dalam berkas .docx atau .odt yang terdiri dari:
Judul, disertai penjelasan (dalam terjemah bahasa Indonesia) dari berkas Jupyter Notebook. (Kode Python pada Jupyter Notebook tak perlu disertakan.)
Pembahasan. Pembahasan ringkas dari aktivitas yang anda lakukan, jika perlu lengkapi unduhan gambar (screenshot).
Simpan setiap berkas dalam nama NIM-TugasXXX.docx misalnya H1A018091-Tugas385.odt. Gabungkan ketiga berkas penugasan dalam file .zip lalu unggah ke laman Assignment di Eldiru.
Istilah Sistem Kendali
Bandwidth and 3dB. The bandwidth of a band pass filter is the frequency range that is allowed to pass through with minimal attenuation. The frequency at which the power level of the signal decreases by 3 dB from its maximum value is called the 3 dB bandwidth. A 3 dB decrease in power means the signal power becomes half of its maximum value. This occurs when the output voltage has dropped to $1/{\sqrt{2}}$ (~0.707) of the maximum output voltage and the power has dropped by half (since $P=V^2/R$. Exact: $20\log _{10}\left({\tfrac {1}{\sqrt {2}}}\right)\approx -3.0103\ \mathrm {dB}$
TKE191121 Dasar Teknik Elektro B RABU 10:20 - 12:00 GEDUNG TEKNIK E 104 - 46 mhs
TKE191121 Dasar Teknik Elektro A RABU 12:30 - 14:10 GEDUNG TEKNIK E 101 - 44 mhs
Capaian Pembelajaran Lulusan (CPL) Program Studi
Pengetahuan-PU03 : menguasai pengetahuan keteknikan dan ilmu komputasi untuk menganalisa dan merancang piranti listrik dan elektronik kompleks, perangkat lunak, dan sistem yang terdiri dari komponen perangkat keras dan perangkat lunak;
Pengetahuan-PU04 : menguasai pengetahuan inti (core knowledge) bidang teknik elektro meliputi: rangkaian elektrik, sistem dan sinyal, sistem digital, elektromagnetik, dan elektronika, beserta penerapan mereka;
Keterampilan Khusus-KK02 : mampu menerapkan pengetahuan matematika, sains dasar, dan topik keteknikan dalam bidang teknik elektro;
Capaian Pembelajaran Mata Kuliah (CPMK)
Memahami pengetahuan matematika dan sains dasar, dan topik keteknikan dalam bidang teknik elektro;
Memahami lingkup dasar-dasar keteknikan dan ilmu komputasi yang diperlukan untuk menganalisis dan merancang
piranti listrik,
piranti elektronik,
perangkat lunak, dan
sistem (perangkat lunak dan perangkat keras);
Memahami lingkup pengetahuan inti (core knowledge) bidang teknik elektro meliputi: rangkaian elektrik, sistem dan sinyal, sistem digital, elektromagnetik, dan elektronika, beserta penerapan mereka;
Bahan Kajian
Ikhtisar pengetahuan matematika dan sains dasar untuk bidang teknik elektro
Ikhtisar pengetahuan keteknikan untuk teknik elektro
Ikhtisar topik keteknikan (terkini) dalam bidang teknik elektro
Ikhtisar ilmu komputasi untuk teknik elektro
Ikhtisar metode analisis dan perancangan piranti listrik dan elektronik
Ikhtisar metode analisis dan perancangan perangkat lunak
Pengenalan rangkaian elektrik dan penerapannya di bidang teknik elektro
Pengenalan sistem dan sinyal dan penerapannya di bidang teknik elektro
Pengenalan sistem digital dan penerapannya di bidang teknik elektro
Pengenalan elektronika dan penerapannya di bidang teknik elektro
TKE191113 Matematika Teknik A KAMIS 07:00 - 09:30 GEDUNG TEKNIK C 101 - 65 mhs
TKE191113 Matematika Teknik B KAMIS 09:30 - 12:00 GEDUNG TEKNIK C 101 - 44 mhs
Capaian Pembelajaran Lulusan (CPL) Program Studi
Pengetahuan-PU01 : menguasai pengetahuan matematika lanjut meliputi kalkulus integraldiferensial, persamaan diferensial, aljabar linier, variable kompleks, probabilitas dan statistik, dan matematika diskret serta penerapan mereka di bidang teknik elektro;
Capaian Pembelajaran Mata Kuliah
Menguasai metode penyelesaian persamaan linear secara analitis dan numeris
Menguasai operasi terhadap matriks dan penerapannya
Menguasai konsep eigenvalue dan eigenvektor dan penerapannya
Menguasai konsep vektor dan ruang vektor serta penerapannya
Menguasai konsep transformasi linear dan penerapannya
Mengapa ada dekomposisi LU? Karena dekomposisi LU lebih cepat dipakai untuk menyelesaikan linear persamaan dengan beragam vektor b, dibandingkan eliminasi Gauss yang harus mengulang langkah untuk setiap vektor b (Ref-1, Ref-2).
6.23 - Control Design with Frequency Method
Control Design with Frequency Method
Perbandingan Metode Root Locus (RL) dan Respon Frekuensi (RF)
Pada desain respon transien dan stabilitas dengan pengaturan gain (gain adjustment)
RF lebih mudah, gain dapat diperoleh dari Bode Plot
Pada desain respon transien dengan kompensasi seri (cascade compensation)
RF tidak se-intuitif RL
di RL titik tertentu diketahui memiliki karakteristik respon transien tertentu
di RF :
phase margin terkait dengan persen overshoot
bandwidth terkait dengan damping ration dan settling time serta peak time
Pada desain steady-state error dengan kompensasi seri
di RF dapat dirancang kompensasi yang memperbaiki respon transien dan steady state error secara bersamaan.
di RL ada banyak solusi yang memungkinkan untuk membuat kompensator (yang setiap solusinya akan memunculkan isu steady state error).
Desain Respon Frekuensi
Sistem yang open loop-nya stabil akan stabil di closed-loop jika magnitude respon frekuensi open loop memiliki gain kurang dari 0 dB pada frekuensi yang mana fase-nya adalah 180 derajat
Persen overshoot dikurangi dengan meningkatkan phase margin
Respon dipercepat dengan meningkatkan bandwidth
Steady state error diperbaiki dengan meningkatkan magnitude respon pada frekuensi rendah
Perbaikan Respon Transien dengan Pengaturan Gain (Gain Adjustment)
Damping ratio ($\zeta$) (dan persen overshoot) dan PM (phase margin)
6.24 - Control Systems
Control Systems
Reference
Norman S. Nise, Control Systems Engineering [website]
Katsuhiko Ogata, Modern Control Engineering
Richard C. Dorf and Robert H. Bishop, Modern Control Systems [website]
Farid Golnaraghi and Benjamin C. Kuo, Automatic Control Systems [website]
Brian Douglas, The Fundamentals of Control Theory [website][ebook]
Pao C. Chau, Process Control: A First Course With MATLAB [website]
Karl J. Åström and Richard M. Murray, Feedback Systems: An Introduction for Scientists and Engineers [website]
R.V. Dukkipati, Analysis and Design of Control Systems using MATLAB
Sliding mode: https://www.youtube.com/watch?v=x9WxwM6Ebvo (Note, this is the only videos or online materials I can find in a course-manner on sliding mode, please suggest more if you find them)
<div>OK. This paper<details><summary>1</summary> Lowry, O. H., Rosebrough, et al. Biol. Chem. 193, 265–275 (1951).</details> describing an assay to determine the amount of protein in a solution.
The sun is molten gold<details><summary>2</summary> it is not, actually</details> and a star.
</div>- The moon is a silver planet<details><summary>3</summary> according to nobody</details> and a star slave.
- This is another reference<details><summary>[4]</summary> something to refer</details>, thank you.
- Don't minify this css
- Put paragraph with `<div>` tag
OK. This paper1 Lowry, O. H., Rosebrough, et al. Biol. Chem. 193, 265–275 (1951). describing an assay to determine the amount of protein in a solution.
The sun is molten gold2 it is not, actually and a star.
The moon is a silver planet3 according to nobody and a star slave.
This is another reference[4] something to refer, thank you.
<pclass="inline">(…) The lack of a clear definition
<inputid="i1"type="checkbox"><labelfor="i1">1</label><small>Bautts, T. (2005) </small> is worrying. The problem as said
<inputid="i2"type="checkbox"><labelfor="i2">2</label><small> Raymond, Eric S. (1996) The New Hacker's Dictionary</small> should be addressed.
</p><pclass="block">(…) The lack of a clear definition
<inputid="b1"type="checkbox"><labelfor="b1">1</label><small>Bautts, T. (2005) </small> is worrying. The problem as said
<inputid="b2"type="checkbox"><labelfor="b2">2</label><small> Raymond, Eric S. (1996) The New Hacker's Dictionary</small> should be addressed.
</p><pclass="hover">(…) The lack of a clear definition
<inputid="h1"type="checkbox"><labelfor="h1">1</label><small>Bautts, T. (2005) </small> is worrying. The problem as said
<inputid="h2"type="checkbox"><labelfor="h2">2</label><small> Raymond, Eric S. (1996) The New Hacker's Dictionary</small> should be addressed.
</p>
(…) The lack of a clear definition
Bautts, T. (2005) is worrying. The problem as said
Raymond, Eric S. (1996) The New Hacker's Dictionary should be addressed.
(…) The lack of a clear definition
Bautts, T. (2005) is worrying. The problem as said
Raymond, Eric S. (1996) The New Hacker's Dictionary should be addressed.
(…) The lack of a clear definition
Bautts, T. (2005) is worrying. The problem as said
Raymond, Eric S. (1996) The New Hacker's Dictionary should be addressed.
<ahref="#"class="hvr-fade">Fade</a><ahref="#"class="hvr-back-pulse">Back Pulse</a><ahref="#"class="hvr-sweep-to-right">Sweep To Right</a><ahref="#"class="hvr-sweep-to-left">Sweep To Left</a><ahref="#"class="hvr-sweep-to-bottom">Sweep To Bottom</a><ahref="#"class="hvr-sweep-to-top">Sweep To Top</a><ahref="#"class="hvr-bounce-to-right">Bounce To Right</a><ahref="#"class="hvr-bounce-to-left">Bounce To Left</a><ahref="#"class="hvr-bounce-to-bottom">Bounce To Bottom</a><ahref="#"class="hvr-bounce-to-top">Bounce To Top</a><ahref="#"class="hvr-radial-out">Radial Out</a><ahref="#"class="hvr-radial-in">Radial In</a><ahref="#"class="hvr-rectangle-in">Rectangle In</a><ahref="#"class="hvr-rectangle-out">Rectangle Out</a><ahref="#"class="hvr-shutter-in-horizontal">Shutter In Horizontal</a><ahref="#"class="hvr-shutter-out-horizontal">Shutter Out Horizontal</a><ahref="#"class="hvr-shutter-in-vertical">Shutter In Vertical</a><ahref="#"class="hvr-shutter-out-vertical">Shutter Out Vertical</a>
<ahref="#"class="hvr-underline-from-left">Underline From Left</a><ahref="#"class="hvr-underline-from-center">Underline From Center</a><ahref="#"class="hvr-underline-from-right">Underline From Right</a><ahref="#"class="hvr-reveal">Reveal</a><ahref="#"class="hvr-underline-reveal">Underline Reveal</a><ahref="#"class="hvr-overline-reveal">Overline Reveal</a><ahref="#"class="hvr-overline-from-left">Overline From Left</a><ahref="#"class="hvr-overline-from-center">Overline From Center</a><ahref="#"class="hvr-overline-from-right">Overline From Right</a>
Lorem ipsum dolor sit amet consectetur adipisicing elit. Ut eum perferendis eius. Adipisci velit et similique earum quas illo odio rerum optio, quis, expedita assumenda enim dicta aliquam porro maxime minima sed a ullam, aspernatur corporis.
7.6 - JS for the Blog
Java Script for the Blog
7.7 - Experimental Markdown
Experimental Markdown
Experimental markdown to check markdown parser compatibility between Gatsby, Jekyll, Gitbook, and Hugo.
This is the first paragraph.
This is the second paragraph
display
This is the first paragraph.
This is the second paragraph
3 Line Break
markdown
This is the first line.
And this is the second line.<br>And finally this is the last line.
display
This is the first line.
And this is the second line.
And finally this is the last line.
4. Emphasis
markdown
**This is bold text**
__This is bold text__*This is italic text*_This is italic text_This text is ___really important___
display
This is bold text This is bold text This is italic text This is italic text
This text is really important
5. Blockquotes
markdown
> This is the first line of paragraph, followed by blank line
>
> Blockquotes can also be nested...
>> ...by using additional greater-than signs right next to each other...
> > > ...or with spaces between arrows.
>
> ### with a heading
>
> - and list
> - list
> - with **bold** and *italic* text
display
This is the first line of paragraph, followed by blank line
Blockquotes can also be nested…
…by using additional greater-than signs right next to each other…
…or with spaces between arrows.
with a heading
and list
list
with bold and italic text
6. Lists
6.1. Unordered
markdown
+ To start a list, there should be an empty line above
+ Create a list by starting a line with `+`, `-`, or `*`- Changing the sign will add a linespace
+ Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
- Sub-lists are made by indenting 2 spaces:
* Item 2a
* Item 2b
* Item 3
To end a list, there should be one empty line above.
display
To start a list, there should be an empty line above
Create a list by starting a line with +, -, or *
Changing the sign will add a linespace
Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
Sub-lists are made by indenting 2 spaces:
Item 2a
Item 2b
Item 3
To end a list, there should be one empty line above.
6.2. Ordered
markdown
1. Item 1
1. Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
3. Sub-lists are made by indenting 4 spaces
1. Item 3a
2. Item 3b
8. Any number for item 4
display
Item 1
Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
Sub-lists are made by indenting 4 spaces
Item 3a
Item 3b
Any number for item 4
6.3. Offset in Oredered List
didn’t work in Gitbook
markdown
57. will started with offset 57
1. so it will be 58
2. this is 59
display
will started with offset 57
so it will be 58
this is 59
7. Elements in Lists
markdown
* To add another element in a list while preserving the continuity of the list...
* indent the element four spaces
like this
* ...or add blank lines in between
I need to add another paragraph below the second list item.
* the third list item.
> A blockquote would look great below the second list item.
* the fourth list item.
display
To add another element in a list while preserving the continuity of the list…
add blank lines in between
I need to add another paragraph below the second list item.
the third list item.
A blockquote would look great below the second list item.
the fourth list item.
markdown
1. This image is inline .
2. Linux mascot is called Tux.

3. Tux is is really cool.
4. For quote in ordered list, add five spaces.
> A blockquote would look great below the second list item.
5. But, for code blocks in the lists, add eight spaces or two tabs:
<html><head><title>Test</title></head>6. So okay for now
display
This image is inline .
Linux mascot is called Tux.
Tux is really cool.
For quote in ordered list, add five spaces.
A blockquote would look great below the second list item.
But, for code blocks in the lists, add eight spaces or two tabs:
<html>
<head>
<title>Test</title>
</head>
So okay for now
8. Code
markdown
This is inline `code`.
display
This is inline code.
markdown
// add four spaces before for code
like this
display
// add four spaces before for code
like this
markdown
<html><head><title>HTML code with four spaces</title></head>
display
<html>
<head>
<title>HTML code with four spaces</title>
</head>
9. Links
markdown
This is [link](https://example.com/)
This is [link with title](https://example.com/ "title text!")
https://example.com/
<https://www.markdownguide.org>I love supporting the **[EFF](https://eff.org)**.
This is the *[Markdown Guide](https://www.markdownguide.org)*.
See the section on [`code`](#code).
But `https://www.example.com`but be careful with [%20 link](https://www.example.com/my%20great%20page)
example [without %20](https://www.example.com/my great page)
I know [Indonesia][1]
I also know [etymology of Indonesia][2]
I knew [History of Indonesia][3]
It doesn't have [hobbit-hole][hh].
[1]: <https://en.wikipedia.org/wiki/Indonesia>
[2]: https://en.wikipedia.org/wiki/Indonesia#Etymology "Etymology of Indonesia"
[3]: https://en.wikipedia.org/wiki/Indonesia#History 'History of Indonesia'
[hh]: <https://en.wikipedia.org/wiki/Hobbit#Lifestyle> "Hobbit lifestyles"

![Wikipedia with Alt Text, reference style][id1]
[id1]: https://upload.wikimedia.org/wikipedia/commons/thumb/d/de/Wikipedia_Logo_1.0.png/240px-Wikipedia_Logo_1.0.png "Optional Text"
display
12. Escaping Characters
markdown
\* star
\\ backslash itself
\` backtick
\{ \} curly braces
\! exclamation mark
display
* star
\ backslash itself
` backtick
{ } curly braces
! exclamation mark
13. HTML Code
very restricted in Gitbook
13.1. HTML: Bold, Italic, Strikethrough
markdown
This <em>word</em> is italic.
This <strong>word</strong> is bold.
This <del>word</del> is deleted with strikethorouugh.
display
This word is italic.
This word is bold.
This word is deleted with strikethorouugh.
13.2. Others HTML Code
didn’t work in Gitbook
markdown
<fontcolor=red>red color</font><mark>highlight</mark><ins>underline</ins><small>smaller text</small>H<sub>2</sub>O
x<sup>2</sup>+y<sup>2</sup>=0
Variable of triangle area: 1/2 x <var>b</var> x <var>h</var>, where <var>b</var> is the base, and <var>h</var> is the vertical height.
display
red color
highlight
underline
smaller text
H2O
x2+y2=0
Variable of triangle area: 1/2 x b x h, where b is the base, and h is the vertical height.
14. Horizontal Rules
didn’t work in Gitbook
markdown
___
---
***
but only didn't work for Gitbook
display
15. Heading ID
didn’t work for Gatsby
markdown
### My Great Heading {#heading-ids}
Link to [Heading IDs](#heading-ids)
```
This is a fenced code block.
```
~~~
No language indicated, so no syntax highlighting.
s = "There is no highlighting for this."
~~~
```python
def function():
#indenting works just fine in the fenced code block
s = "Python syntax highlighting"
print s
```
```javascript
var s = "JavaScript syntax highlighting";
alert(s);
```
```ruby
require 'redcarpet'
markdown = Redcarpet.new("ruby syntax highlighting")
puts markdown.to_html
```
display
This is a fenced code block.
No language indicated, so no syntax highlighting.
s = "There is no highlighting for this."
deffunction():#indenting works just fine in the fenced code blocks="Python syntax highlighting"prints
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| [Example](https://www.example.com/) | **Title** | `Here's this is` |
| Paragraph | Text | And more |
Equation with one dollar sign $ works inline in VNote
Equation with two dollar signs $$ works inline in Jekyll and Gitbook, but not in VNote
markdown
Inline equation with one dollar sign: $E=mc^2$ (worked in VNote and Gatsby).
Inline equation with two dollar sign: $$E=mc^2$$ (worked in Gatsby, Jekyll and Gitbook).
display
Inline equation with one dollar sign: $E=mc^2$ (worked in VNote and Gatsby).
Inline equation with two dollar sign: $$E=mc^2$$ (worked in Gatsby, Jekyll and Gitbook).
23.2. Newline Equation
markdown
Newline equation with two dollar signs.
$$\sin(\alpha)^{\theta}=\sum_{i=0}^{n}(x^i + \cos(f))$$
<details><summary>Click this List ▶</summary><p><ul><li>irosyadi: https://irosyadi.netlify.app</li><li>irosyadi: https://irosyadi.gitbook.io</li><li>irosyadi: https://irosyadi.github.io</li></ul></p></details>
display
Click this List ▶
irosyadi:
irosyadi:
irosyadi:
24.2. Summary
markdown
<details><summary>Clik this Term ▶</summary><p>Term is explanation of something</p></details>
display
Clik this Term ▶
Term is explanation of something
24.3. Definition
markdown
<dl><dt>First Term</dt><dd>This is the definition of the first term.</dd><dt>Second Term</dt><dd>This is one definition of the second term. </dd><dd>This is another definition of the second term.</dd></dl>
display
First Term
This is the definition of the first term.
Second Term
This is one definition of the second term.
This is another definition of the second term.
24.4. Abbreviation
markdown
The <abbrtitle="Hyper Text Markup Language">HTML</abbr> specification is maintained by the <abbrtitle="World Wide Web Consortium">W3C</abbr>.
> **⚠️ WARNING!**
> > This is a warning for you...
display
⚠️ WARNING!
This is a warning for you…
26.3. Admonition with Table
worked in everywhere
*** markdown***
| **⚠️ WARNING!** |
| :--------------------------- |
| This is a warning for you... |
display
⚠️ WARNING!
This is a warning for you…
27. Footnote
didn’t work in Gitbook
markdown
Here's a simple footnote,[^1] and here's a longer one,[^bignote], and [^withcode].
[^1]: This is the first footnote, in Gitbook, there is no new line between.
[^bignote]: Here's another one.
[^withcode]: `code` or code in paragraphs
display
Here’s a simple footnote,1 and here’s a longer one,2, and 3. But there is problem with Gitbook for footnote.
This is the first footnote, in Gitbook, there some problems. ↩︎
zola (MIT) : A fast static site generator in a single binary with everything built-in.
Publii (GPL 3.0) : Publii is a desktop-based CMS for Windows, Mac and Linux that makes creating static websites fast and hassle-free, even for beginners.
Susty (GPL 2.0) : A tiny WordPress theme focused on being as sustainable as possible. Just 6 KB of data transfer.
If the content of the 3 previous steps makes sense, and the paper is relevant
Second steps: going into understanding
Read the body of the paper
Third steps: going into deeper understanding
Deeply analyze the paper
Four steps: writing
Archive it and write bibliographic record
Write your comment or review.
Three-Pass Approach
The first pass gives you a general idea about the paper.
The second pass lets you grasp the papers content, but not its details.
The third pass helps you understand the paper in depth.
First Pass (5-10 minutes)
What to do:
The first pass is a quick scan to get a bird’s-eye view of the paper. You can also decide whether you need to do any more passes.
Carefully read the title, abstract, and introduction
Read the section and sub-section headings, but ignore everything else
Read the conclusions
Glance over the references, mentally ticking off the ones you’ve already read
Goal of the pass:
At the end of the first pass, you should be able to answer the five Cs:
Category: What type of paper is this? A measurement paper? An analysis of an existing system? A description of a research prototype?
Context: Which other papers is it related to? Which theoretical bases were used to analyze the problem?
Correctness: Do the assumptions appear to be valid?
Contributions: What are the papers main contributions?
Clarity: Is the paper well written?
Next steps:
Using this information, you may choose not to read further. This could be because the paper (a) doesn’t interest you, or (b) you don’t know enough about the area to understand the paper, or (c) that the authors make invalid assumptions.
The second pass (1 hour)
What to do:
In the second pass, read the paper with greater care, but ignore details such as proofs. Write the key points, or to make comments, as you read.
Look carefully at the figures, diagrams and other illustrations in the paper. Pay special attention to graphs. Are the axes properly labeled? Are results shown with
error bars, so that conclusions are statistically significant? Common mistakes like these will separate rushed, shoddy work from the truly excellent.
Remember to mark relevant unread references for further reading (this is a good way to learn more about the background of the paper).
Goal of the pass:
After this pass, you should be able to grasp the content of the paper. You should be able to summarize the main thrust of the paper, with supporting evidence, to someone else.
Sometimes you wont understand a paper even at the end of the second pass, because (a) the subject matter is new to you, (b) or the authors may use a proof or experimental technique that you don’t understand (c) the paper may be poorly written, (c) Or it could just you’re tired.
Next steps:
You can now choose to: (a) set the paper aside, hoping you don’t need to understand the material, (b) return to the paper later, perhaps after reading background material or (c) persevere and go on to the third pass.
The third pass (1-5 hours)
What to do:
To fully understand a paper, particularly if you are reviewer. The key to the third pass is to attempt to virtually re-implement the paper: that is, making the same assumptions as the authors, re-create the work. By comparing this re-creation with the actual paper, you can easily identify not only a paper’s innovations, but
also its hidden failings and assumptions.
You should identify and challenge every assumption in every statement.
You should think about how you yourself would present a particular idea.
You should also jot down ideas for future work.
Goal of the pass:
At the end of this pass, you should (a) be able to reconstruct the entire structure of the paper from memory, as well as (b) be able to identify its strong and weak points. In particular, you should (c) be able to pinpoint implicit assumptions, missing citations to relevant work, and potential issues with experimental or analytical techniques.
Three Passes Diagram
Writing the Review
After the second pass:
Summarize the paper in one or two sentences
After the third pass:
A deeper, more extensive outline of the main points of the paper, including for example assumptions made, arguments presented, data analyzed, and conclusions drawn.
Any limitations or extensions you see for the ideas in the paper.
Your opinion of the paper; primarily, the quality of the ideas and its potential impact.
How to write the review
Low-level notes
restate unclear points in your own words
fill in missing details (assumptions, algebraic steps, proofs, pseudocode)
annotate mathematical objects with their types
come up with examples that illustrate the author’s ideas, and examples that would be problematic for the author
draw connections to other methods and problems you know about
ask questions about things that aren’t stated or that don’t make sense
challenge the paper’s claims or methods
dream up follow up work that you (or someone) should do
High-level notes
Distill the paper down: summarize the things that interested you, contrast with other papers, and record your own questions and ideas for future work.
At a minimum, you should re-explain the ideas in your own words: produce some text that is aimed at your future self. You should be able to reread this later and quickly reconstruct your understanding of the paper.
Open Settings: In your address bar, type the following and hit Enter chrome://flags/#dns-over-https or (in newest Chrome) chrome://flags/#dns-httpssvc. It takes you to Secure DNS lookups (Support for HTTPSSVC records in DNS)
Click on Secure DNS lookups (Enable) radio button to enable DoH.
Toolboxes are managed from the Add-On Manager. To open the Add-On Manager:
Open the “Add-Ons” menu in the Environment section of the MATLAB toolstrip
Click “Add-On Manager” in the Add-Ons menu
Each toolbox has an “Uninstall” button on it. Click the button to uninstall the toolbox.
Uninstall toolboxes via the uninstaller.
Open the Control Panel and open “Programs and Features.”
Locate MATLAB in the list of available programs, select it, and click uninstall.
The MATLAB uninstaller will then launch. In the uninstaller, check the boxes for products you wish to uninstall, and uncheck the boxes for products you wish to keep.
Finally, click the “Uninstall” button to uninstall the toolboxes.
Understanding PID Block on Simulink
PID Controller block has a parameter called Filter Coefficient, N. By default this parameter is set to 100. Based on your results, looks like you left this value unchanged. The transfer function of PID Controller block is:
P+I/s+D*N/(1+N/s)
N is the bandwidth of lowpass filter on the derivative. Pure derivative is not a good idea - it amplifies measurement noise, so a practical implementation should avoid pure derivatives and use a low pass filter, which is what PID Controller block does.
If you look under the mask of native PID block, that’s how it does it:
The main point is not to use the pure derivative in your simulation. If you want to approach the pure derivative as high as possible, set N high, say at 1,000 or 10,000.
The derivative term of the PID controller is never implemented as a pure derivative because that would be extremely sensitive to noise. Hence, a cutoff frequency is added.
So, the D term will act like almost a derivative up to a frequency via
Ns
s ---> --------
s + N
N being the filter coefficient. This also makes it possible to implement a D term using an integrator avoiding a noisy derivative operation.
For N=100, its frequency response is:
Ideally, N will be as low as possible. The drawback of derivative action is ideal derivative has very high gain for high frequency signals. It means the high frequency measurement noise will generate large variations of the control signal.
To prevent this situation, the value of filter coefficient ‘N’ is taken to be low (2 < N < 20)
PID in MATLAB
pid
Create PID controller in parallel form, convert to parallel-form PID controller
C = pid(Kp,Ki,Kd,Tf) creates a continuous-time PID controller with proportional, integral, and derivative gains Kp, Ki, and Kd and first-order derivative filter time constant Tf:
$$
C=K_p+ \frac{K_i}{s}+ \frac{K_ds}{T_fs+1}
$$
This representation is in parallel form. When Tf = 0, the controller has no filter on the derivative action.
pidstd
Create a PID controller in standard form, convert to standard-form PID controller
C = pidstd(Kp,Ti,Td,N) creates a continuous-time PIDF (PID with first-order derivative filter) controller object in standard form. The controller has proportional gain Kp, integral and derivative times Ti and Td, and first-order derivative filter divisor N:
When Ti = Inf, the controller has no derivative action. When Td = 0, the controller has no derivative action. When N = Inf, the controller has no filter on the derivative action. $\frac{T_d}{N}= T_f$
PID Tuner
Tune PID controllers.
Command: pidTuner Open PID Tuner for PID tuning.
The PID Tuner app automatically tunes the gains of a PID controller for a SISO plant to achieve a balance between performance and robustness.
Form — Controller form in PID Tuner: ‘Parallel’ | ‘Standard’. See pid and pidstd.
pidtune
PID tuning algorithm for linear plant model.
C=pidtune(sys,type) designs a PID controller of type type for the plant sys. If type specifies a one-degree-of-freedom (1-DOF) PID controller, then the controller is designed for the unit feedback loop as illustrated:
type:
P — Proportional only
I — Integral only
PI — Proportional and integral
PD — Proportional and derivative
PDF — Proportional and derivative with first-order filter on derivative term
PID — Proportional, integral, and derivative
PIDF — Proportional, integral, and derivative with first-order filter on derivative term
PID Controller
Continuous-time or discrete-time PID controller in Simulink.
The PID Controller block implements a PID controller (PID, PI, PD, P only, or I only).
Form — Controller structure: Parallel (default) | Ideal
Parallel. The controller output is the sum of the proportional, integral, and derivative actions, weighted independently by P, I, and D, respectively. For example, for a continuous-time parallel-form PID controller, the transfer function is:
javascript:var s;if(window.getSelection){s=window.getSelection();}else{s=document.selection.createRange().text;}var t=prompt('Please enter a description for the event',s);if(t){void(window.open(encodeURI('https://www.google.com/calendar/event?ctext='+t+'&action=TEMPLATE&pprop=HowCreated%3AQUICKADD'),'gcal'));}else{void(s);}
javascript: (function() { var i, x; for (i = 0; x = document.links[i]; ++i) x.style.color = ["blue", "red", "orange"][sim(x, location)]; function sim(a, b) { if (a.hostname != b.hostname) return 0; if (fixPath(a.pathname) != fixPath(b.pathname) || a.search != b.search) return 1; return 2; } function fixPath(p) { p = (p.charAt(0) == "/" ? "" : "/") + p; /*many browsers*/ p = p.split("?")[0]; /*opera*/ return p; } })()
Show Password
show password text in password form/field
javascript: (function() { var s, F, j, f, i; s = ""; F = document.forms; for (j = 0; j < F.length; ++j) { f = F[j]; for (i = 0; i < f.length; ++i) { if (f[i].type.toLowerCase() == "password") s += f[i].value + "\n"; } } if (s) alert("Passwords in forms on this page:\n\n" + s); else alert("There are no passwords in forms on this page."); })();
Show Source Code
show source code of a webpage
javascript: function getSelSource() { x = document.createElement("div"); x.appendChild(window.getSelection().getRangeAt(0).cloneContents()); return x.innerHTML; } function makeHR() { return nd.createElement("hr"); } function makeParagraph(text) { p = nd.createElement("p"); p.appendChild(nd.createTextNode(text)); return p; } function makePre(text) { p = nd.createElement("pre"); p.appendChild(nd.createTextNode(text)); return p; } nd = window.open().document; ndb = nd.body; if (!window.getSelection || !window.getSelection().rangeCount || window.getSelection().getRangeAt(0).collapsed) { nd.title = "Generated Source of: " + location.href; ndb.appendChild(makeParagraph("No selection, showing generated source of entire document.")); ndb.appendChild(makeHR()); ndb.appendChild(makePre("<html>\n" + document.documentElement.innerHTML + "\n</html>")); } else { nd.title = "Partial Source of: " + location.href; ndb.appendChild(makePre(getSelSource())); }; void 0
javascript: (function() { var d = document, e = d.getElementById('wappalyzer-container'); if (e !== null) { d.body.removeChild(e); } var u = 'https://www.wappalyzer.com/', t = new Date().getTime(), c = d.createElement('div'), p = d.createElement('div'), l = d.createElement('link'), s = d.createElement('script'); c.setAttribute('id', 'wappalyzer-container'); l.setAttribute('rel', 'stylesheet'); l.setAttribute('href', u + 'css/bookmarklet.css'); d.head.appendChild(l); p.setAttribute('id', 'wappalyzer-pending'); p.setAttribute('style', 'background-image: url(' + u + 'images/spinner.gif) !important'); c.appendChild(p); s.setAttribute('src', u + 'bookmarklet/wappalyzer.js'); s.onload = function() { window.wappalyzer = new Wappalyzer(); s = d.createElement('script'); s.setAttribute('src', u + 'bookmarklet/apps.js'); s.onload = function() { s = d.createElement('script'); s.setAttribute('src', u + 'bookmarklet/driver.js'); c.appendChild(s); }; c.appendChild(s); }; c.appendChild(s); d.body.appendChild(c); })();
javascript: (function() { function has(par, ctag) { for (var k = 0; k < par.childNodes.length; ++k) if (par.childNodes[k].tagName == ctag) return true; } function add(par, ctag, text) { var c = document.createElement(ctag); c.appendChild(document.createTextNode(text)); par.insertBefore(c, par.childNodes[0]); } var i, ts = document.getElementsByTagName("TABLE"); for (i = 0; i < ts.length; ++i) { var n = 0, trs = ts[i].rows, j, tr; for (j = 0; j < trs.length; ++j) { tr = trs[j]; if (has(tr, "TD")) add(tr, "TD", ++n); else if (has(tr, "TH")) add(tr, "TH", "Row"); } } })()
Table Transpose
Transpose Table
javascript: (function() { var d = document, q = "table", i, j, k, y, r, c, t; for (i = 0; t = d.getElementsByTagName(q)[i]; ++i) { var w = 0, N = t.cloneNode(0); N.width = ""; N.height = ""; N.border = 1; for (j = 0; r = t.rows[j]; ++j) for (y = k = 0; c = r.cells[k]; ++k) { var z, a = c.rowSpan, b = c.colSpan, v = c.cloneNode(1); v.rowSpan = b; v.colSpan = a; v.width = ""; v.height = ""; if (!v.bgColor) v.bgColor = r.bgColor; while (w < y + b) N.insertRow(w++).p = 0; while (N.rows[y].p > j) ++y; N.rows[y].appendChild(v); for (z = 0; z < b; ++z) N.rows[y + z].p += a; y += b; } t.parentNode.replaceChild(N, t); } })()
javascript:(function(){ var d=open().document; d.title="Selection"; if (window.getSelection) { /*Moz*/ var s = getSelection(); for(i=0; i<s.rangeCount; ++i) { var a, r = s.getRangeAt(i); if (!r.collapsed) { var x = document.createElement("div"); x.appendChild(r.cloneContents()); if (d.importNode) x = d.importNode(x, true); d.body.appendChild(x); } } } else { /*IE*/ d.body.innerHTML = document.selection.createRange().htmlText; } })();
javascript: (function() { var i, c, x, h; for (i = 0; x = document.links[i]; ++i) { h = x.href; x.title += " " + x.innerHTML; while (c = x.firstChild) x.removeChild(c); x.appendChild(document.createTextNode(h)); } })()
we can add formatting text, links, code and HTML character code, but not: heading, headings, blockquotes, lists, horizontal rules, images, HTML tags, or fenced code
Syntaxes
| Option | Description |
| ------ | ----------- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
Showcases
Option
Description
data
path to data files to supply the data that will be passed into templates.
engine
engine to be used for processing templates. Handlebars is the default.
ext
extension to be used for dest files.
Syntaxes
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| Header from | Title | Here's this is |
| Paragraph | Text | And more |
Showcases
Syntax
Description
Test Text is long
Header from
Title
Here’s this is
Paragraph
Text
And more
Syntaxes
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| [Example](https://www.example.com/) | **Title** | `Here's this is` |
| Paragraph | Text | And more |
sequenceDiagram
participant Alice
participant Bob
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
Gantt diagram
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram to mermaid
excludes weekdays 2014-01-10
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
@startuml
participant User
User -> A: DoWork
activate A
A -> B: << createRequest >>
activate B
B -> C: DoWork
activate C
C --> B: WorkDone
destroy C
B --> A: RequestCreated
deactivate B
A -> User: Done
deactivate A
@enduml
To create paragraphs, use a blank line to separate one or more lines of text.
Don’t ident paragraphs with spaces or tabs
Syntaxes
This is the first paragraph.
This is the second paragraph
Showcases
This is the first paragraph.
This is the second paragraph
3 Line Break
Notes:
To create a line break, end a line with two or more spaces, and then type return
Or use the <br> HTML tag
Syntaxes
This is the first line.
And this is the second line.
Showcases
This is the first line.
And this is the second line.
Alternative Syntaxes
First line with the HTML tag after.<br>And the next line.
Showcases
First line with the HTML tag after.
And the next line.
4. Emphasis
Syntaxes
**This is bold text**
__This is bold text__*This is italic text*_This is italic text_We have **bold***italic*
This text is ***really important***
This text is ___really important___This text is __*really important*__
This text is **_really important_**
Showcases
This is bold text This is bold text This is italic text This is italic text
We have bolditalic
This text is really important
This text is really important
This text is really important
This text is really important
5. Blockquotes
Notes:
Space is needed after the marker >;
You could just add only one > at the first line;
Blockquotes can be nested
Blockquotes can contain multiple paragraphs. Add a > between the paragraphs.
Blockquotes can contain other Markdown formatted elements. But not all elements can be used.
Syntaxes
> Blockquotes can also be nested...
>> ...by using additional greater-than signs right next to each other...
> > > ...or with spaces between arrows.
Showcases
Blockquotes can also be nested…
…by using additional greater-than signs right next to each other…
…or with spaces between arrows.
Syntaxes
> Dorothy followed her through many of the beautiful rooms in her castle.
>
> The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Showcases
Dorothy followed her through many of the beautiful rooms in her castle.
The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Syntaxes
> #### The quarterly results look great!
>
> - Revenue was off the chart.
> - Profits were higher than ever.
>
> *Everything* is going according to **plan**.
Showcases
The quarterly results look great!
Revenue was off the chart.
Profits were higher than ever.
Everything is going according to plan.
6. Lists
6.1. Unordered
Syntaxes
+ To start a list, there should be an empty line above
+ Create a list by starting a line with `+`, `-`, or `*`- Changing the sign will add a linespace
+ Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
- Sub-lists are made by indenting 2 spaces:
* Item 2a
* Item 2b
* Item 3
To end a list, there should be one empty line above.
Showcases
To start a list, there should be an empty line above
Create a list by starting a line with +, -, or *
Changing the sign will add a linespace
Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
Sub-lists are made by indenting 2 spaces:
Item 2a
Item 2b
Item 3
To end a list, there should be one empty line above.
6.2. Ordered
Syntaxes
1. Item 1
1. Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
3. Sub-lists are made by indenting 4 spaces
1. Item 3a
2. Item 3b
8. Any number for item 4
Showcases
Item 1
Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
Sub-lists are made by indenting 4 spaces
Item 3a
Item 3b
Any number for item 4
Syntaxes
57. will started with offset 57
1. so it will be 58
Showcases
will started with offset 57
so it will be 58
7. Elements in Lists
Notes:
To add another element in a list while preserving the continuity of the list, indent the element four spaces or one tab
Syntaxes
* This is the first list item.
* Here's the second list item.
I need to add another paragraph below the second list item.
* And here's the third list item.
Showcases
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
Showcases
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
Showcases
This is the first list item.
Here’s the second list item.
A blockquote would look great below the second list item.
And here’s the third list item.
Syntaxes
1. Open the file containing the Linux mascot.
2. Linux mascot called Tux.

3. Tux is cool.
Showcases
Open the file containing the Linux mascot.
Linux mascot called Tux.
Tux is cool.
But, for text element in ordered list, add five spaces
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
But, for quote in ordered list, add five spaces
This is the first list item.
Here’s the second list item.
A blockquote would look great below the second list item.
And here’s the third list item.
But, for code blocks in the lists, add eight spaces or two tabs.
Open the file.
Find the following code block on line 21:
<html>
<head>
<title>Test</title>
</head>
Update the title to match the name of your website.
8. Code
Notes:
Inline codes is written inside ` `
or idented by add four spaces or one tab before
Syntaxes
This is inline `code`.
Showcases
This is inline code.
Syntaxes
// Some comments
line 1 of code
line 2 of code
line 3 of code
Showcases
// Some comments
line 1 of code
line 2 of code
line 3 of code
It is not recommended to use image links in reference format. Some apps will not preview those images.
Specifying size of image is supported only in some extended markdown (such as markdown-it).
Syntaxes





sequenceDiagram
participant Alice
participant Bob
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
Gantt diagram
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram to mermaid
excludes weekdays 2014-01-10
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
@startuml
participant User
User -> A: DoWork
activate A
A -> B: << createRequest >>
activate B
B -> C: DoWork
activate C
C --> B: WorkDone
destroy C
B --> A: RequestCreated
deactivate B
A -> User: Done
deactivate A
@enduml
Markdown Syntax:
The "HTML" specification is maintained by the "W3C". *[HTML]: Hyper Text Markup Language *[W3C]: World Wide Web Consortium
HTML Syntax:
The <abbr title="Hyper Text Markup Language">HTML</abbr> specification is maintained by the <abbr title="World Wide Web Consortium">W3C</abbr>.
Markdown Display:
The “HTML” specification is maintained by the “W3C”.
*[HTML]: Hyper Text Markup Language
*[W3C]: World Wide Web Consortium
HTML Display:
The HTML specification is maintained by the W3C.
2.3. Tables
Support: kramdown
Notes:
we can set alignment in table with a colon (:)
we can add formatting text, links, code and HTML character code, but not: heading, headings, blockquotes, lists, horizontal rules, images, HTML tags, or fenced code
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| [Example](https://www.example.com/) | **Title** | `Here's this is` |
| Paragraph | Text | And more |
Here's a simple footnote[^1] and here's a longer one[^bignote], and [^withcode]
[^1]: This is the first footnote.
[^bignote]: Here's one with multiple paragraphs.
For example like this
[^withcode]: `code` or code in paragrahps
`code and codes`
HTML Syntax:
<p>Here’s a simple footnote<sup id="fnref:1"><a href="#fn:1" rel="footnote">1</a></sup> and here’s a longer one<sup id="fnref:2"><a href="#fn:2" rel="footnote">2</a></sup>, and <sup id="fnref:3"><a href="#fn:3" rel="footnote">3</a></sup></p>
<div class="footnotes"><hr /><ol><li id="fn:1">
<p>This is the first footnote. <a href="#fnref:1" rev="footnote">↩</a></p>
</li><li id="fn:2">
<p>Here’s one with multiple paragraphs. For example like this <a href="#fnref:2" rev="footnote">↩</a></p>
</li><li id="fn:3">
<p><code>code</code> or code in paragrahps <code>code and codes</code> <a href="#fnref:3" rev="footnote">↩</a></p>
</li></ol></div>
Markdown Display:
Here’s a simple footnote1 and here’s a longer one2, and 3
HTML Display:
Here’s a simple footnote1 and here’s a longer one2, and 3
Another example of footnote 1 link[^first] and footnote 2 link[^second].
HTML Syntax:
<p>Another example of footnote 1 link<ahref="#fn:1"id="fnref:1"title="see footnote"class="footnote"><sup>1</sup></a> and footnote 2 link<ahref="#fn:2"id="fnref:2"title="see footnote"class="footnote"><sup>2</sup></a>.</p><divclass="footnotes"><hr/><ol><liid="fn:1"><p>first <ahref="#fnref:1"title="return to body"class="reversefootnote"> ↩</a></p></li><liid="fn:2"><p>second <ahref="#fnref:2"title="return to body"class="reversefootnote"> ↩</a></p></li></ol></div>
Markdown Display:
Another example of footnote 1 link[^first] and footnote 2 link[^second].
HTML Display:
Another example of footnote 1 link1 and footnote 2 link2.
This is a duplicated footnote[^b].
This duplicated footnote reference[^b].
[^b]: Another footnote text.
HTML Syntax Kramdown Style:
<p>This is a duplicated footnote<supid="fnref:b"><ahref="#fn:b"class="footnote">1</a></sup>.
This duplicated footnote reference<supid="fnref:b:1"><ahref="#fn:b"class="footnote">1</a></sup>.</p><divclass="footnotes"><ol><liid="fn:b"><p>Another footnote text. <ahref="#fnref:b"class="reversefootnote">↩</a><ahref="#fnref:b:1"class="reversefootnote">↩<sup>2</sup></a></p></li></ol></div>
First Term
: This is the definition of the first term.
Second Term
: This is one definition of the second term.
: This is another definition of the second term.
HTML Syntax:
<dl>
<dt>First Term</dt>
<dd>This is the definition of the first term.</dd>
<dt>Second Term</dt>
<dd>This is one definition of the second term. </dd>
<dd>This is another definition of the second term.</dd>
</dl>
Markdown Display:
First Term
This is the definition of the first term.
Second Term
This is one definition of the second term.
This is another definition of the second term.
HTML Display:
First Term
This is the definition of the first term.
Second Term
This is one definition of the second term.
This is another definition of the second term.
2.7. Emojies
2.7.1 Copy Paste of Emoji
Markdown Syntax
Gone camping! ⛺ Be back soon.
That is so funny! 😂
HTML Syntax
<p>Gone camping! ⛺ Be back soon.
That is so funny! 😂</p>
Markdown Display
Gone camping! ⛺ Be back soon.
That is so funny! 😂
HTML Display
Gone camping! ⛺ Be back soon.
That is so funny! 😂
2.7.2 Markdown of Emoji
Support: markdown-it
Markdown Syntax:
Gone camping! :tent: Be back soon.
That is so funny! :joy:
> Classic markup: :wink: :crush: :cry: :tear: :laughing: :yum:
>
> Shortcuts (emoticons): :-) :-( 8-) ;)
HTML Syntax:
<p>Gone camping! ⛺️ Be back soon.
That is so funny! 😂</p>
<blockquote>
<p>Classic markup: 😉 :crush: 😢 :tear: 😆 😋</p>
<p>Shortcuts (emoticons): 😃 😦 😎 😉</p>
</blockquote>
Markdown Display
Gone camping! :tent: Be back soon.
That is so funny! :joy:
This is a paragraph
{::comment}
This is a comment which is
completely ignored.
{:/comment}
... paragraph continues here.
Extensions can also be used
inline {::nomarkdown}**see**{:/}!
<p>This is a paragraph
<!--
This is a comment which is
completely ignored.
-->… paragraph continues here.</p><p>Extensions can also be used
inline **see**!</p>
Implicit Header REferences
Support : Pandoc
So, to link to a heading
# Heading identifiers in HTML
you can simply write
[Heading identifiers in HTML]
or
[Heading identifiers in HTML][]
Line Blocks
Support: pandocs
| The limerick packs laughs anatomical
| In space that is quite economical.
| But the good ones I've seen
| So seldom are clean
| And the clean ones so seldom are comical
Kramdown
Markdown Extra
Pandoc
Definition Lists
✅
✅
✅
Table
✅
✅
Attributes
✅
✅
✅
Footnote
✅
✅
Abbreviation
✅
✅
Code Fencing
✅
✅
Task Lists
✅
Image Dimension
Mention
Strikethrough
Emoji
Image Sizing
Specifying size of image is supported only in some extended markdown (such as markdown-it).
Syntaxes





GFM enables the tagfilter extension, where the following HTML tags will be filtered when rendering HTML output: <title> <textarea> <style> <xmp> <iframe> <noembed> <noframes> <script> <plaintext>
[>MMD] is an abbreviation. So is [>(MD) Markdown].
[>MMD]: MultiMarkdown
HTML code:
Citations
Markdown syntax:
This is a statement that should be attributed to
its source[p. 23][#Doe:2006].
And following is the description of the reference to be
used in the bibliography.
[#Doe:2006]: John Doe. *Some Big Fancy Book*. Vanity Press, 2006.
HTML code:
CriticMarkup
CriticMarkup is a way for authors and editors to track changes to documents in plain text. As with Markdown, small groups of distinctive characters allow you to highlight insertions, deletions, substitutions and comments, all without the overhead of heavy, proprietary office suites. https://criticmarkup.com/
Definition List
Markdown syntax:
Apple
: Pomaceous fruit of plants of the genus Malus in
the family Rosaceae.
: An american computer company.
Orange
: The fruit of an evergreen tree of the genus Citrus.
HTML code:
Cross-References
Markdown syntax:
I added the ability to interpret [Some Text][] as a cross-link, if a header named “Some Text” exists.
HTML code:
Escaped newlines
Markdown syntax:
This is a line.\
This is a new line
HTML code:
Fenced Code Blocks
Markdown syntax:
```perl
# Demonstrate Syntax Highlighting if you link to highlight.js #
# https://softwaremaniacs.org/soft/highlight/en/
print "Hello, world!\n";
$a = 0;
while ($a <10){print"$a...\n";$a++;}
HTML code:
```html
File Transclusion
File transclusion is the ability to tell MultiMarkdown to insert the contents of another file inside the current file being processed.
Markdown syntax:
This is some text.
{{some_other_file.txt}}
Another paragraph
HTML code:
Footnotes
Markdown syntax:
Here is some text containing a footnote.[^somesamplefootnote]
[^somesamplefootnote]: Here is the text of the footnote itself.
[somelink]:https://somelink.com
HTML code:
Glossaries
Markdown syntax:
[?(glossary) The glossary collects information about important
terms used in your document] is a glossary term.
[?glossary] is also a glossary term.
[?glossary]: The glossary collects information about important
terms used in your document
HTML code:
Images Extension
MultiMarkdown also adds a few additional features. If an image is the only thing in a paragraph, it is treated as a block level element
Markdown syntax:
This image ()
is different than the following image:

HTML code:
<p>This image (<imgsrc="/path/to/img.jpg"alt="Alt text"/>)
is different than the following image:</p><figure><imgsrc="/path/to/img.jpg"alt="Alt text"/><figcaption>Alt text</figcaption></figure>
Link and Image Attributes
Markdown syntax:
This is a formatted ![image][] and a [link][] with attributes.
[image]: https://path.to/image "Image title" width=40px height=400px
[link]: https://path.to/link.html "Some Link" class=external
style="border: solid black 1px;"
Colored [link](https://example.net "Title" style="color:red")
HTML code:
Math
Subscript Superscript
Markdown syntax:
y^(a+b)^
x~y,z~
HTML code:
Metadata
It is possible to include special metadata at the top of a MultiMarkdown document, such as title, author, etc. This information can then be used to control how MultiMarkdown processes the document, or can be used in certain output formats in special ways.
Raw Source
Code spans and code blocks can be flagged as representing raw source
Markdown syntax:
foo `*bar*`{=html}
```{=latex}
*foo*
HTML code:
```html
Smart Typography
MultiMarkdown converts:
Straight quotes (" and ‘) into “curly” quotes
Backticks-style quotes (``this’’) into “curly” quotes
Dashes (– and —) into en- and em- dashes
Three dots (…) become an ellipsis
Table of Contents
Markdown syntax:
{{TOC}}
{{TOC:2-3}}
HTML code:
Tables
Markdown syntax:
| | Grouping ||
First Header | Second Header | Third Header |
------------ | :-----------: | -----------: |
Content | *Long Cell* ||
Content | **Cell** | Cell |
New section | More | Data |
And more | With an escaped '\|' ||
[Prototype table]
To create paragraphs, use a blank line to separate one or more lines of text.
Don’t ident paragraphs with spaces or tabs
A leaf block, it cannot contain other block
Markdown syntax:
This is the first paragraph.
This is the second paragraph
HTML code:
<p>This is the first paragraph.</p><p>This is the second paragraph</p>
Markdown display:
This is the first paragraph.
This is the second paragraph
HTML display:
This is the first paragraph.
This is the second paragraph
1.3 Line Break
1.3.1 Hard Line Break
Notes:
To create a line break, end a line of text with two or more spaces, and then type return
Or by ended it with \
Or by use the <br> HTML tag
Markdown syntax:
This is the first line, ended with two spaces.
And this is the second line.
This is the first line, ended with `\`.\
And this is the second line.
This is the first line, ended with `<br>`.<br>And this is the second line.
HTML code:
<p>This is the first line, ended with two spaces.<br/>And this is the second line.</p><p>This is the first line, ended with <code>\</code>.<br/>And this is the second line.</p><p>This is the first line, ended with <code><br></code>.<br>And this is the second line.</p>
Markdown display:
This is the first line, ended with two spaces.
And this is the second line.
This is the first line, ended with \.
And this is the second line.
This is the first line, ended with <br>.
And this is the second line.
HTML display:
This is the first line, ended with two spaces.
And this is the second line.
This is the first line, ended with \.
And this is the second line.
This is the first line, ended with <br>.
And this is the second line.
1.3.2 Soft Line Break
Note:
A regular line break (not in a code span or HTML tag) that is not preceded by two or more spaces or a backslash is parsed as a softbreak. (A softbreak may be rendered in HTML either as a line ending or as a space.
Markdown syntax:
This is the first line, without two spaces in the end.
And this is the second line.
HTML code:
<p>This is the first line, without two spaces in the end.
And this is the second line.</p>
Markdown display:
This is the first line, without two spaces in the end.
And this is the second line.
HTML display:
This is the first line, without two spaces in the end.
And this is the second line.
1.4. Emphasis
Between * or _ and text should be not any whitespace.
*italics* or _italics_will make italics
**bold** or __bold__will make bold
Markdown syntax:
**This is bold text**
__This is bold text__*This is italic text*_This is italic text_We have **bold***italic*
This text is ***really important***
This text is ___really important___This text is __*really important*__
This text is **_really important_**
HTML code:
<p><strong>This is bold text</strong><br/><strong>This is bold text</strong><br/><em>This is italic text</em><br/><em>This is italic text</em><br/>We have <strong>bold</strong><em>italic</em><br/>This text is <em><strong>really important</strong></em><br/>This text is <em><strong>really important</strong></em><br/>This text is <strong><em>really important</em></strong><br/>This text is <strong><em>really important</em></strong></p>
Markdown display:
This is bold text This is bold text This is italic text This is italic text
We have bolditalic
This text is really important
This text is really important
This text is really important
This text is really important
HTML display:
This is bold text This is bold text This is italic text This is italic text
We have bolditalic
This text is really important
This text is really important
This text is really important
This text is really important
1.5. Blockquotes
Notes:
A container block, it can contain other block
You could just add only one > at the first line (lazy-continuation);
Blockquotes can contain other blockquotes (nested)
Blockquotes can contain other blocks: multiple paragraphs, heading, code, etc.
Blockquotes can contain other Markdown formatted elements. But not all elements can be used.
Markdown syntax:
> Blockquotes can also be nested...
>> ...by using `>` right next to each other...
> > > ...or with spaces between arrows.
HTML code:
<blockquote><p>Blockquotes can also be nested...</p><blockquote><p>...by using <code>></code> right next to each other...</p><blockquote><p>...or with spaces between arrows.</p></blockquote></blockquote></blockquote>
Markdown display:
Blockquotes can also be nested…
…by using > right next to each other…
…or with spaces between arrows.
HTML display:
Blockquotes can also be nested...
...by using > right next to each other...
...or with spaces between arrows.
Markdown syntax:
> ### A Heading 3
>
> - List
> - of `code`.
>
>> *Everything* is going according to **plan** in [example][ex].
[ex]: https://example.com/ "an example link"
HTML code:
<blockquote><h3>A Heading 3</h3><ul><li>List</li><li>of <code>code</code>.</li></ul><blockquote><p><em>Everything</em> is going according to <strong>plan</strong> in <ahref="https://example.com/"title="an example link">example</a>.</p></blockquote></blockquote>
A sublist must be indented the same number of spaces a paragraph would need to be in order to be included in the list item.
Add some space so the next mark of the next item will be positioned under the first character of previous list item.
Markdown syntax:
- foo
- add two spaces
- add two spaces
- add two spaces
HTML code:
<ul><li>foo
<ul><li>add two spaces
<ul><li>add two spaces
<ul><li>add two spaces</li></ul></li></ul></li></ul></li></ul>
Markdown display:
foo
add two spaces
add two spaces
add two spaces
HTML display:
foo
add two spaces
add two spaces
add two spaces
1.7. Lists
Notes:
A list is a sequence of one or more list items of the same type.
The list items may be separated by any number of blank lines.
Two list items are of the same type if they begin with a list marker of the same type.
Two list markers are of the same type if (a) they are bullet list markers using the same character (-, +, or *) or (b) they are ordered list numbers with the same delimiter (either . or )).
A list is an ordered list if its constituent list items begin with ordered list markers, and a bullet list if its constituent list items begin with bullet list markers.
A list is loose if any of its constituent list items are separated by blank lines (loose list are wrapped in <p> tags), or if any of its constituent list items directly contain two block-level elements with a blank line between them. Otherwise a list is tight.
1.7.1 Paragraph and Starting New List
Notes:
No blank line is needed to separate a paragraph from a following list
Changing the bullet or ordered list delimiter starts a new list
Markdown syntax:
I have:
1. foo
10. bar
5) baz
11) buzz
+ ouch
+ what
- where
+ To start a list, there should be an empty line above
+ Create a list by starting a line with `+`, `-`, or `*`- Changing the sign will add a linespace (make new list)
+ Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
- Sub-lists are made by indenting 2 spaces (to ensure the next mark is fallen under the first character of previous list item):
* Item 2a
* Item 2b
* Item 3
To end a list, there should be one empty line above.
Markdown display:
To start a list, there should be an empty line above
Create a list by starting a line with +, -, or *
Changing the sign will add a linespace (make new list)
Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
Sub-lists are made by indenting 2 spaces (to ensure the next mark is fallen under the first character of previous list item):
Item 2a
Item 2b
Item 3
To end a list, there should be one empty line above.
1.7.4. Ordered Lists
Notes:
The start number of an ordered list is determined by the list number of its initial list item. The numbers of subsequent list items are disregarded.
Markdown syntax:
1. Notice that the sequence number is irrelevant.
1. Notice that there are two spaces at the end.
To make a new text under item.
3. Sub-lists are made by indenting 4 spaces (to ensure the next mark is fallen under the first character of previous list item)
1. Item 3a
2. Item 3b
8. Any number for item 4
Markdown display:
Notice that the sequence number is irrelevant.
Notice that there are two spaces at the end.
To make a new text under item.
Sub-lists are made by indenting 4 spaces (to ensure the next mark is fallen under the first character of previous list item)
Item 3a
Item 3b
Any number for item 4
1.7.5. Ordered List Continuation
Markdown syntax:
57. will started with offset 57
1. so it will be 58
HTML code:
<olstart="57"><li>will started with offset 57</li><li>so it will be 58</li></ol>
Markdown display:
will started with offset 57
so it will be 58
HTML display:
will started with offset 57
so it will be 58
1.7.6. Elements in Lists
Notes:
To add another element in a list while preserving the continuity of the list, indent the element four spaces or one tab
Markdown syntax:
* This is the first list item.
> A blockquote would look great below the second list item.
* Here's the second list item.
I need to add another paragraph below the second list item.
* And here's the third list item.

* and the last list item
Markdown display:
This is the first list item.
A blockquote would look great below the second list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
and the last list item
But, for text element in ordered list, add five spaces
This is the first list item.
A blockquote would look great below the second list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
and the last list item
But, for code blocks in the lists, add eight spaces or two tabs.
Open the file.
Find the following code block on line 21:
<html>
<head>
<title>Test</title>
</head>
Update the title to match the name of your website.
1.8. Code and Code Blocks
1.8.1. Inline Code (Code Spans)
Notes:
It is inline content
It is written between two backticks \'
Markdown syntax:
This is a `code`.
HTML code:
<p>This is a <code>code</code>.</p>
Markdown display:
This is a code.
HTML display:
This is a code.
1.8.2. Indented Code Blocks
Notes:
Idented by add at least four spaces or one tab before
A code fence is a sequence of at least three consecutive backtick characters (`) or tildes (~)
An info string can be provided after the opening code fence lang is optional to help to specify the language of the code.
A leaf block, it cannot contain other block
Markdown syntax:
~~~
This is a fenced code block.
~~~
```
This is also a fenced code block.
```
HTML code:
<pre><code>This is a fenced code block.
</code></pre>
<pre><code>This is also a fenced code block.
</code></pre>
Markdown display:
This is a fenced code block.
This is also a fenced code block.
HTML display:
This is a fenced code block.
This is also a fenced code block.
1.9. Links
1.9.1. Inline Links
Notes:
A link contains link text (the visible text), a link destination (the URI that is the link destination), and optionally a link title.
Markdown syntax:
This is [link](https://example.com/)
This is [*link with title and `code`*](https://example.com/ "title text!")
This is [https://example.com/]()
HTML code:
<p>This is <ahref="https://example.com/">link</a></p><p>This is <ahref="https://example.com/"title="title text!"><em>link with title and <code>code</code></em></a></p><p>This is <ahref="">https://example.com/</a></p>
A shortcut reference link consists of a link label that matches a link reference definition elsewhere in the document and is not followed by [] or a link label.
Markdown syntax:
This is a [foo]
[foo]: https://example.com/ "an example link"
HTML code:
<p>This is a <ahref="https://example.com/"title="an example link">foo</a></p>
Syntax for images is like the syntax for links, with one difference. Instead of link text, we have an image description.
The rules for this are the same as for link text, except that (a) an image description starts with ![ rather than [, and (b) an image description may contain links.
It is not recommended to use image links in reference format. Some apps will not preview those images.
This is a ![Wikipedia][ex]
[ex]: https://upload.wikimedia.org/wikipedia/commons/thumb/d/de/Wikipedia_Logo_1.0.png/240px-Wikipedia_Logo_1.0.png "Wikipedia Logo"
<p>This is a <imgsrc="https://upload.wikimedia.org/wikipedia/commons/thumb/d/de/Wikipedia_Logo_1.0.png/240px-Wikipedia_Logo_1.0.png"alt="Wikipedia"title="Wikipedia Logo"/></p>
1.10.3 Shorcut References Format
This is a ![foo]
[foo]: https://upload.wikimedia.org/wikipedia/commons/thumb/d/de/Wikipedia_Logo_1.0.png/240px-Wikipedia_Logo_1.0.png "Wikipedia Logo"
<p>This is a <imgsrc="https://upload.wikimedia.org/wikipedia/commons/thumb/d/de/Wikipedia_Logo_1.0.png/240px-Wikipedia_Logo_1.0.png"alt="foo"title="Wikipedia Logo"/></p>
1.11. Escaping Characters
Note:
add a backslash \ in front of the ASCII character.
Any ASCII punctuation character may be backslash-escaped
Markdown syntax:
\!\"\#\$\%\&\'\(\)\*\+\,
\-\.\/\:\;\<\=\>\?\@\[\\\]
\^\_\`\{\|\}\~
\*not emphasized*
\<br/> not a tag
\[not a link](/foo)
\`not code`
1\. not a list
\* not a list
\# not a heading
\[foo]: /url "not a reference"
\ö not a character entity
HTML code:
<p>!"#$%&'()*+,<br/>-./:;<=>?@[\]<br/>^_`{|}~</p><p>*not emphasized*<br/><br/> not a tag<br/>[not a link](/foo)<br/>`not code`<br/>1. not a list<br/>* not a list<br/># not a heading<br/>[foo]: /url "not a reference"<br/>&ouml; not a character entity</p>
Markdown display:
!"#$%&'()*+,
-./:;<=>?@[\]
^_`{|}~
*not emphasized*
<br/> not a tag
[not a link](/foo)
`not code`
1. not a list
* not a list
# not a heading
[foo]: /url “not a reference”
ö not a character entity
HTML display:
!"#$%&'()*+,
-./:;<=>?@[\]
^_`{|}~
*not emphasized*
<br/> not a tag
[not a link](/foo)
`not code`
1. not a list
* not a list
# not a heading
[foo]: /url "not a reference"
ö not a character entity
1.12. Raw HTML and HTML Blocks
1.12.1. Raw HTML
Notes:
Text between < and > that looks like an HTML tag is parsed as a raw HTML tag and will be rendered in HTML without escaping.
Markdown syntax:
<strongstyle="color:red;">bold red</strong><!-- This is a comment, will not shown -->
HTML code:
<p><strongstyle="color:red;">bold red</strong></p><!-- This is a comment, will not shown -->
Markdown display:
bold red
HTML display:
bold red
1.12.2. HTML Blocks
Notes:
An HTML block is a group of lines that is treated as raw HTML
With start and end conditions are:
start with <script, <pre, or <style and end with </script>, </pre>, or </style>
start with <!-- and end with -->
start with <? and end with ?>
start with <! with uppercase ASCII letter inside and end with >
start wtih <![CDATA[ and end with ]]>
start with string < or </ followed by specific strings and end with >, or the string />
This project is community driven, and tries to reach consensus.
Maintainers will only step in if the community cannot reach a decision.
Discussion will take place [on the issue tracker]({{ site.cirosantilli-github }}/issues).
There may be use cases in which either is preferred:
for source code, readability becomes more important,
as programmers are going to open the files on their editors often.
Editor features like syntax highlighting and line wrapping
can greatly reduce problems, but it is of course better if people
don’t need to change their editors at all.
for forums like Stack Overflow, people will very rarely read the source,
only the rendered output. So it might be better to optimize writing speed.
The current style is inconsistent with either of those optimizations. For now,
we propose two sets of options (profiles) which optimize either one: readability
and writability profiles.
Readability profile
wrap:space
list-marker:asterisk
code:indented
Writability profile
wrap:no
list-marker:hyphen
code:fenced
Typographic conventions
When this style guide needs to represent multiple adjacent spaces,
or spaces at the beginning or ending of code blocks, this will be mentioned
explicitly in prose, and a dot will be used to make the space visible.
carwin/markdown-styleguide.
This guide was originally forked from it. It has been extended considerably,
some decisions were modified, and no original lines remain.
Prefer to base the file name on the top-header level:
replace upper case letters with lower case
strip articles the, a, an from the start
replace punctuation and white space characters by hyphens
replace consecutive hyphens by a single hyphen
strip surrounding hyphens
Good:
file-name.md
Bad, multiple consecutive hyphens:
file--name.md
Bad, surrounding hyphens:
-file-name-.md
Rationale: why not underscore or camel case? Hyphens are the most popular URL separator today,
and markdown files are most often used in contexts where:
there are hyphen separated HTML files in the same project, possibly the same directory as the markdown files.
filenames will be used directly on URLs. E.g.: GitHub blobs.
Whitespaces
Newlines
Don’t use 2 or more consecutive empty lines, that is,
more than two consecutive newline characters,
except where they must appear literally such as in code blocks.
End files with a newline character, and don’t leave empty lines at the end of the file.
Don’t use trailing whitespace unless it has a function such as indicating a line break.
Good:
- list
- list
# Header
Good, code block:
The markup language X requires you to use triple newlines to separate paragraphs:
p1
p2
Bad:
- list
- list
# Header
Rationale: multiple empty lines occupy more vertical screen space,
and do not significantly improve readability.
Spaces after sentences
Option space-sentence:1
Use a single space after sentences.
Bad, 2 spaces:
First sentence. Second sentence.
Good:
First sentence. Second sentence.
Rationale: advantages over space-sentence:2:
easier to edit
usually not necessary if you use wrap:inner-sentence or wrap:sentence
space-sentence:2 gives a false sense of readability
as it is ignored on the HTML output
more popular
Advantages of space-sentence:2:
easier to see where sentences end
Option space-sentence:2
Bad, single space:
First sentence. Second sentence.
Good:
First sentence. Second sentence.
Line wrapping
Option wrap:inner-sentence
Try to keep lines under 80 characters by breaking large paragraphs logically at points such as:
sentences: after a period ., question ? or exclamation mark !
clauses:
after words like and, which, if ... then, commas ,
It is acceptable to have a line longer than 80 characters,
but keep in mind that long sentences are less readable
and look worse in tools such as git diff.
Set your editor to wrap lines visually for Markdown in case a large line is present.
Good:
This is a very very very very very very very very very very very very very long not wrapped sentence.
Second sentence of of the paragraph,
third sentence of a paragraph
and the fourth one.
Rationale:
Diffs look better, since a change to a clause shows up as a single diff line.
Occasional visual wrapping does not significantly reduce the readability of Markdown,
since the only language feature that can be indented to indicate hierarchy are nested lists.
At some point GitHub translated single newlines to line breaks in READMEs,
and still does so on comments.
Currently there is no major engine which does it, so it is safe to use newlines.
Some tools are not well adapted for long lines, e.g. Vim and git diff will not wrap lines by default.
This can be configured however via git config --global core.pager 'less -r' for Git and set wrap for Vim.
Downsides:
requires considerable writer effort, specially when modifying code.
Markdown does not look like the rendered output, in which there are no line breaks.
Manual line breaking can make the Markdown more readable than the rendered output,
which is bad because it gives a false sense of readability encouraging less
readable long paragraphs.
Requires users of programming text editors like Vim, which are usually configured to not wrap,
to toggle visual wrapping on. This can be automated, but
EditorConfig gave it WONTFIX
Breaks some email systems, which always break a line on a single newline, and
make your email
look
something like this.
Option wrap:no
Don’t wrap lines.
Rationale: very easy to edit. But diffs on huge lines are hard to read.
Option wrap:space
Always wrap at the end of the first word that exceeds 80 characters.
Rationale: source code becomes is very readable and text editors support it automatically.
But diffs will look bad, and changing lines will be hard.
Option wrap:sentence
Rationale: similar advantages as wrap:inner-sentence,
but easier for people to follow since the rule is simple:
break after the period. But may produce long lines with hard to read diffs.
Don’t prefix shell code with dollar signs $
unless you will be showing the command output on the same code block.
If the goal is to clarify what the language is, do it on the preceding paragraph.
Rationale: harder to copy paste, noisier to read.
Good:
echo a
echo a > file
Bad:
$ echo a
$ echo a > file
Good, shows output:
$ echo a
a
$ echo a > file
Good, language specified on preceding paragraph:
Use the following Bash code:
echo a
echo a > file
What to mark as code
Use code blocks or inline code for:
executables. E.g.:
`gcc` is the best compiler available.
Differentiate between tool and the name of related projects. E.g.: gcc vs GCC.
file paths
version numbers
capitalized explanation of abbreviations:
xinetd stands for `eXtended Internet daemon`
other terms related to computers that you don’t want to add to your dictionary
Don’t mark as code:
names of projects. E.g.: GCC
names of libraries. E.g.: libc, glibc
Spelling and grammar
Use correct spelling and grammar.
Prefer writing in English, and in particular American English.
Rationale: American English speakers have the largest GDP,
specially in the computing industry.
Use markup like URL or code on words which you do not want to add to your dictionary
so that spell checkers can ignore them automatically.
Beware of case sensitive spelling errors, in particular for project, brand names or abbreviations:
Good: URL, LinkedIn, DoS attack
Bad: url, Linkedin, dos attack
When in doubt, prefer the same abbreviation as used on Wikipedia.
Avoid informal contractions:
Good: biography, repository, directory
Bad: bio, repo, dir
Block elements
Line breaks
Avoid line breaks, as they don’t have generally accepted semantic meaning.
In the rare case you absolutely need them, end a lines with exactly two spaces.
Headers
Option header:atx
Bad:
Header 1
========
Header 2
--------
### Header 3
Good:
# Header 1
## Header 2
### Header 3
Rationale: advantages over Setex:
easier to write because in Setex you have to match
the number of characters in both lines for it to look good
works for all levels, while Setex only goes up to level 2
occupy only one screen line, while Setex occupies 2
Advantages of Setex
more visible. Not very important if you have syntax highlighting.
Include a single space between the # and the text of the header.
Bad:
#Header
#..Header
Good:
# Header
Don’t use the closing # character.
Bad:
# Header #
Good:
# Header
Rationale: easier to maintain.
Don’t add spaces before the number sign #.
Bad:
.# Header
Good:
# Header
Option header:setex
Bad:
# Header 1
## Header 2
### Header 3
Good:
Header 1
========
Header 2
--------
### Header 3
Don’t skip header levels.
Bad:
# Header 1
### Header 3
Good:
# Header 1
## Header 2
Surround headers by a single empty line except at the beginning of the file.
Avoid using two headers with the same content in the same markdown file.
Rationale: many markdown engines generate IDs for headers based on the header content.
Bad:
# Dogs
## Anatomy
# Cats
## Anatomy
Good:
# Dogs
## Anatomy of the dog
# Cats
## Anatomy of the cat
Top-level header
If you target HTML output, write your documents so that it will have one
and only one h1 element as the first thing in it that serves as the title of the document.
This is the HTML top-level header.
How this h1 is produced may vary depending on your exact technology stack:
some stacks may generate it from metadata, for example Jekyll through the front-matter.
Storing the top-level header as metadata has the advantage that it can be reused elsewhere more easily,
e.g. on a global index, but the downside of lower portability.
If your target stack does not generate the top-level header in another way,
include it in your markdown file. E.g., GitHub.
Top-level headers on index-like files such as README.md or index.md
should serve as a title for their parent directory.
Downsides of top-level headers:
take up one header level. This means that there are only 5 header levels left,
and each new header will have one extra #, which looks worse and is harder to write.
duplicate filename information, which most often can already be seen on a URL.
In most cases, the filename can be trivially converted to a top-level,
e.g.: some-filename.md to Some filename.
Advantages of top-level headers:
more readable than URL’s, especially for non-technically inclined users.
Header case
Use an upper case letter as the first letter of a header,
unless it is a word that always starts with lowercase letters, e.g. computer code.
Good:
# Header
Good, computer code that always starts with lower case:
# int main
Bad:
# header
The other letters have the same case they would have in the middle of a sentence.
Good:
# The header of the example
Bad:
# The Header of the Example
As an exception, title case
may be optionally used for the top-level header.
Use this exception sparingly, in cases where typographical perfection is important,
e.g.: README of a project.
Rationale: why not Title case for all headers?
It requires too much effort to decide if edge-case words should be upper case or not.
End of a header
Indicate the end of a header’s content that is not followed by a new header by an horizontal rule:
# Header
Content
---
Outside header.
Header length
Keep headers as short as possible.
Instead of using a huge sentence, make the header a summary to the huge sentence,
and write the huge sentence as the first paragraph beneath the header.
Rationale: if automatic IDs are generated by the implementation, it is:
easier to refer to the header later while editing
less likely that the IDs will break due to rephrasing
easier to distinguish between different IDs
Good:
# Huge header
Huge header that talks about a complex subject.
Bad:
# Huge header that talks about a complex subject
Punctuation at the end of headers
Don’t add a trailing colon : to headers.
Rationale: every header is an introduction to what is about to come next,
which is exactly the function of the colon.
Don’t add a trailing period . to headers.
Rationale: every header consists of a single short sentence,
so there is not need to add a sentence separator to it.
Good:
# How to do make omelet
Bad:
# How to do make omelet:
Bad:
# How to do make omelet.
Header synonyms
Headers serve as an index for users searching for keywords.
For this reason, you may want to give multiple keyword possibilities for a given header.
To do so, simply create a synonym header with empty content just before its main header.
E.g.:
# Purchase
# Buy
You give money and get something in return.
Every empty header with the same level as the following one is assumed to be a synonym.
This is not the case if levels are different:
# Animals
## Dog
Blockquotes
Follow the greater than marker > by one space.
Good:
> a
Bad:
>a
Bad, 2 spaces:
> a
Use a greater than sign for every line, including wrapped.
Bad:
> Long line
that was wrapped.
Good:
> Long line
> that was wrapped.
Don’t use empty lines inside a single block quote.
Good:
> a
>
> b
Bad:
> a
> b
Lists
Marker
Unordered
Option list-marker:hyphen
Use the hyphen marker.
Good:
- a
- b
Bad:
* a
* b
+ a
+ b
Rationale:
asterisk * can be confused with bold or italic markers.
plus sign + is not popular
Downsides:
* and + are more visible. * is more visible
Option list-marker:asterisk
Use *.
Option list-marker:plus
Use +.
Ordered
Prefer lists only with the marker 1. for ordered lists,
unless you intend to refer to items by their number in the same markdown file or externally.
Prefer unordered lists unless you intent to refer to items by their number.
Best, we will never refer to the items of this list by their number:
- a
- c
- b
Better, only 1.:
1. a
1. c
1. b
Worse, we will never refer to the items of this list by their number:
1. a
2. c
3. b
Acceptable, refer to them in the text:
The ouput of the `ls` command is of the form:
drwx------ 2 ciro ciro 4096 Jul 5 2013 dir0
drwx------ 4 ciro ciro 4096 Apr 27 08:00 dir1
1 2
Where:
1. permissions
2. number of files directory contains
Acceptable, meant to be referred by number from outside of the markdown file:
Terms of use.
1. I will not do anything illegal.
2. I will not do anything that can harm the website.
Rationale:
If you want to change a list item in the middle of the list,
you don’t have to modify all items that follow it.
Diffs will show only the significant line which was modified.
Content stays aligned without extra effort if the numbers reach 2 digits. E.g.: the following is not aligned:
9. a
10. b
References break when a new list item is added. To reduce this problem:
keep references close to the list so authors are less likely to forget to update them
when referring from an external document, always refer to an specific version of the markdown file
Spaces before list marker
Do not add any space before list markers, except to obey the current level of indentation.
Bad:
- a
- b
Good:
- a
- b
Good, c is just following the indentation of b:
- a
- b
- c
Bad, c modified the indentation of b:
- a
- b
- c
Rationale:
easier to type
easier to reason about levels
Spaces after list marker
Option list-space:mixed
If the content of every item of the list is fits in a single paragraph, use 1 space.
Otherwise, for every item of the list:
use 3 spaces for unordered lists.
use 2 spaces for ordered lists.
One less than for unordered because the marker is 2 chars long.
Bad, every item is one line long:
- a
- b
Good:
- a
- b
Bad, every item is one line long:
1. a
1. b
Good:
1. a
1. b
Bad: item is longer than one line:
- item that
is wrapped
- item 2
Good:
- item that
is wrapped
- item 2
Bad: item is longer than one line:
- a
par
- b
Good:
- a
par
- b
Option list-space:1
Always add one space to the list marker.
Bad, 3 spaces:
- a
b
- c
Good:
- a
b
- c
Bad, 2 spaces:
1. a
b
1. c
Good:
1. a
b
1. c
Rationale: list-space mixed vs 1
The advantages of list-space:1 are that
it removes the decision of how many spaces you should put after the list marker:
it is always one.
We could choose to always have list content indented as:
- a
- b
but that is ugly.
You never need to change the indentation of the entire list because of a new item.
This may happen in list-space:mixed if you have:
- a
- b
and will add a multi-line item:
- a
- b
- c
d
Note how a and b were changed because of c.
The disadvantages of list-space:1
creates three indentation levels for the language:
4 for indented code blocks
3 for ordered lists
2 for unordered lists
That means that you cannot easily configure your editor indent level to deal with all cases
when you want to change the indentation level of multiple list item lines.
Is not implemented consistently across editors.
In particular what should happen at:
- a
code
This (2 spaces):
<pre><code> code
Or no spaces:
<pre><code>code
Likely the original markdown said no spaces:
To put a code block within a list item, the code block
needs to be indented twice — 8 spaces or two tabs
The indentation level of what comes inside list and of further list items
must be the same as the first list item.
Bad:
- item that
is wrapped
- item 2
Good:
- item that
is wrapped
- item 2
Bad:
- item 1
Content 1
- item 2
Content 2
Good (if it matches your spaces after list marker style):
- item 1
Content 1
- item 2
Content 2
Bad:
- item 1
Content 1
- item 2
Content 2
Good (if it matches your spaces after list marker style):
- item 1
Content 1
- item 2
Content 2
Avoid starting a list item directly with indented code blocks because that is not consistently implemented.
CommonMark states that a single space is assumed in that case:
- code
a
Empty lines inside lists
If every item of a list is a single line long, don’t add empty lines between items.
Otherwise, add empty lines between every item.
Rationale: it is hard to tell where multi-line list items start and end without empty lines.
Empty lines around lists
Surround lists by one empty line.
Bad:
Before.
- item
- item
After.
Good:
Before.
- list
- list
After.
Case of first letter of list item
Each list item has the same case as it would have if it were concatenated with the sentence that comes before the list.
Good:
I want to eat:
- apples
- bananas
- grapes
because it could be replaced with:
I want to eat apples
I want to eat babanas
I want to eat grapes
Good:
To ride a bike you have to:
- get on top of the bike. This step is easy.
- put your foot on the pedal.
- push the pedal. This is the most fun part.
because it could be replaced with:
To ride a bike you have to get on top of the bike. This step is easy.
To ride a bike you have to put your foot on the pedal.
To ride a bike you have to push the pedal. This is the most fun part.
Good:
# How to ride a bike
- Get on top of the bike.
- Put your feet on the pedal.
- Make the pedal turn.
because it could be replaced with:
# How to ride a bike
Get on top of the bike.
Put your feet on the pedal.
Push the the pedal.
Punctuation at the end of list items
Punctuate at the end of list items if either it:
contains multiple sentences or paragraphs
starts with an upper case letter
Otherwise, omit the punctuation if it would be a period.
Bad, single sentences:
- apple.
- banana.
- orange.
Good:
- apple
- banana
- orange
Idem:
- go to the market
- then buy some fruit
- finally eat the fruit
Good, not terminated by period but by other punctuation.
- go to the marked
- then buy fruit?
- of course!
Bad, multiple sentences:
- go to the market
- then buy some fruit. Bad for wallet
- finally eat the fruit. Good for tummy
Good:
- go to the market
- then buy some fruit. Bad for wallet.
- finally eat the fruit. Good for tummy.
Note: nothing forbids one list item from ending in period while another in the same list does not.
Bad, multiple paragraphs:
- go to the market
- then buy some fruit
Bad for wallet
- finally eat the fruit
Good for tummy
Good:
- go to the market
- then buy some fruit.
Bad for wallet.
- finally eat the fruit.
Good for tummy.
Bad, starts with upper case:
- Go to the market
- Then buy some fruit
- Finally eat the fruit
Good:
- Go to the market.
- Then buy some fruit.
- Finally eat the fruit.
Definition lists
Avoid the definition list extension since it is not present
in many implementations nor in CommonMark.
Instead, use either:
formated lists:
format the item be defined as either of bold, link or code
separate the item from the definition with a colon and a space :.
don’t align definitions as it is harder to maintain and does not show on the HTML output
Good:
- **apple**: red fruit
- **dog**: noisy animal
Good:
- **apple**: red fruit.
Very tasty.
- **dog**: noisy animal.
Not tasty.
Good:
- [apple](https://apple.com): red fruit
- [dot](https://dog.com): red fruit
Good:
- `-f`: force
- `-r`: recursive
Bad, no colon:
- **apple** red fruit
- **dog** noisy animal
Bad, space between term and colon:
- **apple** : red fruit
- **dog** : noisy animal
Bad, definitions aligned:
- **apple**: red fruit
- **dog**: noisy animal
headers.
Good:
# Apple
Red fruit
# Dog
Noisy animal
Code blocks
Option code:fenced
Only use fenced code blocks.
Comparison to indented code blocks:
disadvantage: not part of the original markdown, thus less portable, but added to CommonMark.
advantage: many implementations, including GitHub’s, allow to specify the code language with it
Don’t indent fenced code blocks.
Always specify the language of the code is applicable.
Good:
```ruby
a = 1
```
Bad:
```
a = 1
```
Option code:indented
Only use indented code blocks.
Indent indented code blocks with 4 spaces.
Code blocks must be surrounded by one empty line.
Prefer to end the phrase before a code block with a colon :.
Good:
Use this code to blow up your PC:
sudo rm -rf /
Bad, no colon
Use this code to blow up your PC
sudo rm -rf /
Horizontal rules
Don’t use horizontal rules except to indicate the End of a header.
Rationale:
headers are better section separators since they say what a section is about.
horizontal rules don’t have a generally accepted semantic meaning.
This guide gives them one.
Use 3 hyphens without spaces:
---
Tables
Extension.
Surround tables by one empty line.
Don’t indent tables.
Surround every line of the table by pipes.
Align all border pipes vertically.
Separate header from body by hyphens except at the aligned pipes |.
Pipes | must be surrounded by a space, except for outer pipes
which only get one space internally, and pipes of the hyphen separator line.
Column width is determined by the longest cell in the column.
Good table:
Before.
| h | Long header |
|------|-------------|
| abc | def |
| abc2 | def2 |
After.
Rationale:
unaligned tables tables are easier to write, but aligned tables are more readable,
and people read code much more often than they edit it.
preceding pipes make it easier to determine where a table starts and ends.
Trailing pipes make it look better because of symmetry.
there exist tools which help keeping the table aligned.
For example, Vim has the Tabular plugin
which allows to align the entire table with :Tabular /|.
why no spaces around pipes of the hyphen separator line, i.e.: |---| instead of | - |?
No spaces looks better, works on GitHub. Downside: harder to implement automatic alignment in editors,
as it requires a special rule for the separator line.
Rationale: single quotes do not work in all major implementations, double quotes do.
Emphasis
Bold
Use double asterisk format: **bold**.
Rationale: more common and readable than the double underline __bold__ form.
Italic
Use single asterisk format: *italic*.
Rationale:
more common and readable than the underscore form
consistent with the bold format, which also uses asterisks
Uppercase for emphasis
Don’t use uppercase for emphasis: use emphasis constructs like bold or italic instead.
Rationale: CSS has text-transform:uppercase which can easily achieve the same effect consistently
across the entire website if you really want uppercase letters.
Emphasis vs headers
Don’t use emphasis elements (bold or italics) to introduce a multi line named section: use headers instead.
Rationale: that is exactly the semantic meaning of headers,
and not necessarily that of emphasis elements. As a consequence,
many implementations add useful behaviors to headers and not to emphasis elements,
such as automatic id to make it easier to refer to the header later on.
Good:
# How to make omelets
Break an egg.
...
# How to bake bread
Open the flour sack.
...
Bad:
**How to make omelets:**
Break an egg.
...
**How to bake bread:**
Open the flour sack.
...
Automatic links
Automatic links without angle brackets
Don’t use automatic links without angle brackets.
Good:
<https://a.com>
Bad:
https://a.com
Rationale: it is an extension, <> is easy to type and saner.
If you want literal links which are not autolinks, enclose them in code blocks. E.g.:
`https://not-a-link.com`
Rationale: many tools automatically interpret any word starting with https as a link.
Content of automatic links
All automatic links must start with the string https.
In particular, don’t use relative automatic links.
Use bracket links instead for that purpose.
Good:
[file.html](file.html)
Bad:
<file.html>
Good:
<https://github.com>
Bad:
<github.com>
Rationale: it is hard to differentiate automatic links from HTML tags.
What if you want a relative link to a file called script?
Email automatic links
Don’t use email autolinks <address@example.com>. Use raw HTML instead.
Rationale: the original markdown specification states it:
“performs a bit of randomized decimal and hex entity-encoding
to help obscure your address from address-harvesting spambots”.
Therefore, the output is random, ugly, and as the spec itself mentions:
but an address published in this way will probably eventually start receiving spam
9.11 - Markdown Cheatsheet
Markdown Cheatsheet
Overview
This Markdown cheat sheet provides a quick overview of all the Markdown syntax elements. It can’t cover every edge case, so if you need more information about any of these elements, refer to our reference guides for basic syntax and extended syntax.
Basic Syntax
These are the elements outlined in John Gruber’s original design document. All Markdown applications support these elements.
Markdown is a lightweight markup language that you can use to add formatting elements to plaintext text documents. Created by John Gruber in 2004, Markdown is now one of the world’s most popular markup languages.
What’s Markdown?
Using Markdown is different than using a WYSIWYG editor. In an application like Microsoft Word, you click buttons to format words and phrases, and the changes are visible immediately. Markdown isn’t like that. When you create a Markdown-formatted file, you add Markdown syntax to the text to indicate which words and phrases should look different.
For instance, to denote a heading, you add a number sign before it (e.g., # Heading One). Or to make a phrase bold, you add two asterisks before and after it (e.g., **this text is bold**). It may take a while to get used to seeing Markdown syntax in your text, especially if you’re accustomed to WYSIWYG applications. The screenshot below shows a Markdown file displayed in the Atom text editor.
You can add Markdown formatting elements to a plaintext file using a text editor application. Or you can use one of the many Markdown applications for macOS, Windows, Linux, iOS, and Android operating systems. There are also several web-based applications specifically designed for writing in Markdown.
Depending on the application you use, you may not be able to preview the formatted document in real time. But that’s okay. According to Gruber, Markdown syntax is designed to be readable and unobtrusive, so the text in Markdown files can be read even if it isn’t rendered.
The overriding design goal for Markdown’s formatting syntax is to make it as readable as possible. The idea is that a Markdown-formatted document should be publishable as-is, as plain text, without looking like it’s been marked up with tags or formatting instructions.
Why Use Markdown?
You might be wondering why people use Markdown instead of a WYSIWYG editor. Why write with Markdown when you can press buttons in an interface to format your text? As it turns out, there are a couple different reasons why people use Markdown instead of WYSIWYG editors.
Markdown is portable. Files containing Markdown-formatted text can be opened using virtually any application. If you decide you don’t like the Markdown application you’re currently using, you can import your Markdown files into another Markdown application. That’s in stark contrast to word processing applications like Microsoft Word that lock your content into a proprietary file format.
Markdown is platform independent. You can create Markdown-formatted text on any device running any operating system.
Markdown is future proof. Even if the application you’re using stops working at some point in the future, you’ll still be able to read your Markdown-formatted text using a text editing application. This is an important consideration when it comes to books, university theses, and other milestone documents that need to be preserved indefinitely.
Markdown is everywhere. Websites like Reddit and GitHub support Markdown, and lots of desktop and web-based applications support it.
Kicking the Tires
The best way to get started with Markdown is to use it. That’s easier than ever before thanks to a variety of free tools.
You don’t even need to download anything. There are several online Markdown editors that you can use to try writing in Markdown. Dillinger is one of the best online Markdown editors. Just open the site and start typing in the left pane. A preview of the rendered document appears in the right pane.
You’ll probably want to keep the Dillinger website open as you read through this guide. That way you can try the syntax as you learn about it. After you’ve become familiar with Markdown, you may want to use a Markdown application that can be installed on your desktop computer or mobile device.
How Does it Work?
Dillinger makes writing in Markdown easy because it hides the stuff happening behind the scenes, but it’s worth exploring how the process works in general.
When you write in Markdown, the text is stored in a plaintext file that has an .md or .markdown extension. But then what? How is your Markdown-formatted file converted into HTML or a print-ready document?
The short answer is that you need a Markdown application capable of processing the Markdown file. There are lots of applications available — everything from simple scripts to desktop applications that look like Microsoft Word. Despite their visual differences, all of the applications do the same thing. Like Dillinger, they all convert Markdown-formatted text to HTML so it can be displayed in web browsers.
Markdown applications use something called a Markdown processor (also commonly referred to as a “parser” or an “implementation”) to take the Markdown-formatted text and output it to HTML format. At that point, your document can be viewed in a web browser or combined with a style sheet and printed. You can see a visual representation of this process below.
Note: The Markdown application and processor are two separate components. For the sake of brevity, I've combined them into one element ("Markdown App") in the figure below.
To summarize, this is a four-part process:
Create a Markdown file using a text editor or a dedicated Markdown application. The file should have an .md or .markdown extension.
Open the Markdown file in a Markdown application.
Use the Markdown application to convert the Markdown file to an HTML document.
View the HTML file in a web browser or use the Markdown application to convert it to another file format, like PDF.
From your perspective, the process will vary somewhat depending on the application you use. For example, Dillinger essentially combines steps 1-3 into a single, seamless interface — all you have to do is type in the left pane and the rendered output magically appears in the right pane. But if you use other tools, like a text editor with a static website generator, you’ll find that the process is much more visible.
What’s Markdown Good For?
Markdown is a fast and easy way to take notes, create content for a website, and produce print-ready documents.
It doesn’t take long to learn the Markdown syntax, and once you know how to use it, you can write using Markdown just about everywhere. Most people use Markdown to create content for the web, but Markdown is good for formatting everything from email messages to grocery lists.
Here are some examples of what you can do with Markdown.
Websites
Markdown was designed for the web, so it should come as no surprise that there are plenty of applications specifically designed for creating website content.
If you’re looking for the simplest possible way to create a website with Markdown files, check out blot.im and smallvictori.es. After you sign up for one of these services, they create a Dropbox folder on your computer. Just drag and drop your Markdown files into the folder and — poof! — they’re on your website. It couldn’t be easier.
If you’re familiar with HTML, CSS, and version control, check out Jekyll, a popular static site generator that takes Markdown files and builds an HTML website. One advantage to this approach is that GitHub Pages provides free hosting for Jekyll-generated websites. If Jekyll isn’t your cup of tea, just pick one of the many other static site generators available.
Note: I used Jekyll to create the Markdown Guide. You can view the source code on GitHub.
If you’d like to use a content management system (CMS) to power your website, take a look at Ghost. It’s a free and open-source blogging platform with a nice Markdown editor. If you’re a WordPress user, you’ll be happy to know there’s Markdown support for websites hosted on WordPress.com. Self-hosted WordPress sites can use the Jetpack plugin.
Documents
Markdown doesn’t have all the bells and whistles of word processors like Microsoft Word, but it’s good enough for creating basic documents like assignments and letters. You can use a Markdown document authoring application to create and export Markdown-formatted documents to PDF or HTML file format. The PDF part is key, because once you have a PDF document, you can do anything with it — print it, email it, or upload it to a website.
Here are some Markdown document authoring applications I recommend:
Tip:iA Writer provides templates for previewing, printing, and exporting Markdown-formatted documents. For example, the "Academic – MLA Style" template indents paragraphs and adds double sentence spacing.
Notes
In nearly every way, Markdown is the ideal syntax for taking notes. Sadly, Evernote and OneNote, two of the most popular note applications, don’t currently support Markdown. The good news is that several other note applications do support Markdown:
Simplenote is a free, barebones note-taking application available for every platform.
Notable is a note-taking application that runs on a variety of platforms.
Bear is an Evernote-like application available for Mac and iOS devices. It doesn’t exclusively use Markdown by default, but you can enable Markdown compatibility mode.
Boostnote bills itself as an “open source note-taking app designed for programmers.”
If you can’t part with Evernote, check out Marxico, a subscription-based Markdown editor for Evernote, or use Markdown Here with the Evernote website.
Books
Looking to self-publish a novel? Try Leanpub, a service that takes your Markdown-formatted files and turns them into an electronic book. Leanpub outputs your book in PDF, EPUB, and MOBI file format. If you’d like to create paperback copies of your book, you can upload the PDF file to another service such as Kindle Direct Publishing. To learn more about writing and self-publishing a book using Markdown, read this blog post.
Presentations
Believe it or not, you can generate presentations from Markdown-formatted files. Creating presentations in Markdown takes a little getting used to, but once you get the hang of it, it’s a lot faster and easier than using an application like PowerPoint or Keynote. Remark (GitHub project) is a popular browser-based Markdown slideshow tool, as is Cleaver (GitHub project). If you use a Mac and would prefer to use an application, check out Deckset or Marked.
Email
If you send a lot of email and you’re tired of the formatting controls available on most email provider websites, you’ll be happy to learn there’s an easy way to write email messages using Markdown. Markdown Here is a free and open-source browser extension that converts Markdown-formatted text into HTML that’s ready to send.
Documentation
Markdown is a natural fit for technical documentation. Companies like GitHub are increasingly switching to Markdown for their documentation — check out their blog post about how they migrated their Markdown-formatted documentation to Jekyll. If you write documentation for a product or service, take a look at these handy tools:
Read the Docs can generate a documentation website from your open source Markdown files. Just connect your GitHub repository to their service and push — Read the Docs does the rest. They also have a service for commercial entities.
MkDocs is a fast and simple static site generator that’s geared towards building project documentation. Documentation source files are written in Markdown and configured with a single YAML configuration file. MkDocs has several built in themes, including a port of the Read the Docs documentation theme for use with MkDocs. One of the newest themes is MkDocs Material.
Docusaurus is a static site generator designed exclusively for creating documentation websites. It supports translations, search, and versioning.
VuePress is a static site generator powered by Vue and optimized for writing technical documentation.
Jekyll was mentioned earlier in the section on websites, but it’s also a good option for generating a documentation website from Markdown files. If you go this route, be sure to check out the Jekyll documentation theme.
Flavors of Markdown
One of the most confusing aspects of using Markdown is that practically every Markdown application implements a slightly different version of Markdown. These variants of Markdown are commonly referred to as flavors. It’s your job to master whatever flavor of Markdown your application has implemented.
To wrap your head around the concept of Markdown flavors, it might help to think of them as language dialects. People in Ciudad Juárez speak Spanish just like the people in Barcelona, but there are substantial differences between the dialects used in both cities. The same is true for people using different Markdown applications. Using Dillinger to write with Markdown is a vastly different experience than using Ulysses.
Practically speaking, this means you never know exactly what a company means when they say they support “Markdown.” Are they talking about only the basic syntax elements, or all of the basic and extended syntax elements combined, or some arbitrary combination of syntax elements? You won’t know until you read the documentation or start using the application.
If you’re just starting out, the best advice I can give you is to pick a Markdown application with good Markdown support. That’ll go a long way towards maintaining the portability of your Markdown files. You might want to store and use your Markdown files in other applications, and to do that you need to start with an application that provides good support. You can use the tool directory to find an application that fits the bill.
Additional Resources
There are lots of resources you can use to learn Markdown. Here are some other introductory resources:
Just like many other apps, Zettlr makes use of Markdown, originally invented by John Gruber. Of course, over such a long period of time, a huge amount of developments have taken place, that have created the possibilities of modern Markdown applications. In this document the following topics are covered:
Since the personal computer became widely available in the 1990s, there were two groups of formats existing side-by-side: word processor documents, such as .doc, or .odt and code documents, such as .js, .cpp or .py. Both groups of documents contain human-readable text, but there was one simple, yet huge difference: While JavaScript-files or C++-files contained plain text (i.e. only the text that you would see when you open such a file), word processor documents contained a lot more stuff. Word processor documents always hold information about the page size (e.g., A4 or letter), how different blocks should be formatted (e.g., the font of headings or how much blockquotes are indented). If you open a Word/Office-document on your PC right now, you can see what I mean: You immediately see what is a heading based on the font-size font-weight of its text.
For a long time, both these groups of documents stayed as distinct as would their users. Most office-workers only know how to use Microsoft Word or Excel, maybe also LibreOffice-implementations, while close to nobody coming from a STEM-background would voluntarily use Word or similar software. Those scientists have chosen a different path: they developed a programming language called LaTeX, which allows them to create neatly formatted PDF-files from a bunch of code—they follow the same workflow as researchers from the arts and humanities or regular administrative officers, but use different documents for that.
When Markdown was inaugurated by John Gruber in 2004, it was basically like saying: “Why not both?” Markdown combines both the clear reading experience from word processor documents with the benefits of software code documents, which is both versatile and easy to use—even for people that only know how to operate Word or Writer. One small example: While in word processors you would create a heading by typing “some text” and then selecting the Heading 1 format from some menu, in Markdown you would simply type # some text, where the hashtag-symbol tells you immediately: “This is a first level heading!”
At first, Markdown was basically a small script John Gruber wrote for himself to yield these benefits, and it contained a lot of inconsistencies and didn’t support many different elements. But over the years, progress was made. Two dates are notable:
2012: A group of developers form CommonMark to standardise Markdown into an internationally accepted norm.
Markdown Dialects
Today, several implementations of the Markdown syntax coexist. The most noteworthy are:
MultiMarkdown: Extends the initial syntax with footnotes, tables and some metadata.
Markdown Extra: Again some additions to the initial syntax.
GitHub Flavoured Markdown: This is a variety of Markdown invented by the hosting platform GitHub (which Zettlr is also hosted on!) and is today one of the most common dialects.
Pandoc Markdown: Pandoc Markdown is a superset of GitHub flavoured Markdown and adds support for even more elements.
CommonMark: Tries to implement all possible elements, while being unambiguous. Notably, CommonMark not yet includes a specification for footnotes.
9.13 - Extended Syntax of Markdown
Extended Syntax of Markdown
Overview
The basic syntax outlined in John Gruber’s original design document added many of the elements needed on a day-to-day basis, but it wasn’t enough for some people. That’s where extended syntax comes in.
Several individuals and organizations took it upon themselves to extend the basic syntax by adding additional elements like tables, code blocks, syntax highlighting, URL auto-linking, and footnotes. These elements can be enabled by using a lightweight markup language that builds upon the basic Markdown syntax, or by adding an extension to a compatible Markdown processor.
Availability
Not all Markdown applications support extended syntax elements. You’ll need to check whether or not the lightweight markup language your application is using supports the extended syntax elements you want to use. If it doesn’t, it may still be possible to enable extensions in your Markdown processor.
Lightweight Markup Languages
There are several lightweight markup languages that are supersets of Markdown. They include Gruber’s basic syntax and build upon it by adding additional elements like tables, code blocks, syntax highlighting, URL auto-linking, and footnotes. Many of the most popular Markdown applications use one of the following lightweight markup languages:
There are dozens of Markdown processors available. Many of them allow you to add extensions that enable extended syntax elements. Check your processor’s documentation for more information.
Tables
To add a table, use three or more hyphens (---) to create each column’s header, and use pipes (|) to separate each column. You can optionally add pipes on either end of the table.
| Syntax | Description |
| ----------- | ----------- |
| Header | Title |
| Paragraph | Text |
The rendered output looks like this:
Syntax
Description
Header
Title
Paragraph
Text
Cell widths can vary, as shown below. The rendered output will look the same.
| Syntax | Description |
| --- | ----------- |
| Header | Title |
| Paragraph | Text |
Tip: Creating tables with hyphens and pipes can be tedious. To speed up the process, try using the Markdown Tables Generator. Build a table using the graphical interface, and then copy the generated Markdown-formatted text into your file.
Alignment
You can align text in the columns to the left, right, or center by adding a colon (:) to the left, right, or on both side of the hyphens within the header row.
| Syntax | Description | Test Text |
| :--- | :----: | ---: |
| Header | Title | Here's this |
| Paragraph | Text | And more |
The rendered output looks like this:
Syntax
Description
Test Text
Header
Title
Here’s this
Paragraph
Text
And more
Formatting Text in Tables
You can format the text within tables. For example, you can add links, code (words or phrases in backticks (`) only, not code blocks), and emphasis.
You can’t add headings, blockquotes, lists, horizontal rules, images, or HTML tags.
Escaping Pipe Characters in Tables
You can display a pipe (|) character in a table by using its HTML character code (|).
Fenced Code Blocks
The basic Markdown syntax allows you to create code blocks by indenting lines by four spaces or one tab. If you find that inconvenient, try using fenced code blocks. Depending on your Markdown processor or editor, you’ll use three backticks (```) or three tildes (~~~) on the lines before and after the code block. The best part? You don’t have to indent any lines!
Tip: Need to display backticks inside a code block? See this section to learn how to escape them.
Syntax Highlighting
Many Markdown processors support syntax highlighting for fenced code blocks. This feature allows you to add color highlighting for whatever language your code was written in. To add syntax highlighting, specify a language next to the backticks before the fenced code block.
Footnotes allow you to add notes and references without cluttering the body of the document. When you create a footnote, a superscript number with a link appears where you added the footnote reference. Readers can click the link to jump to the content of the footnote at the bottom of the page.
To create a footnote reference, add a caret and an identifier inside brackets ([^1]). Identifiers can be numbers or words, but they can’t contain spaces or tabs. Identifiers only correlate the footnote reference with the footnote itself — in the output, footnotes are numbered sequentially.
Add the footnote using another caret and number inside brackets with a colon and text ([^1]: My footnote.). You don’t have to put footnotes at the end of the document. You can put them anywhere except inside other elements like lists, block quotes, and tables.
Here's a simple footnote,[^1] and here's a longer one.[^bignote]
[^1]: This is the first footnote.
[^bignote]: Here's one with multiple paragraphs and code.
Indent paragraphs to include them in the footnote.
`{ my code }`
Add as many paragraphs as you like.
The rendered output looks like this:
Here’s a simple footnote,1 and here’s a longer one.2
Heading ID’s
Many Markdown processors support custom IDs for headings — some Markdown processors automatically add them. Adding custom IDs allows you to link directly to headings and modify them with CSS. To add a custom heading ID, enclose the custom ID in curly braces on the same line as the heading.
### My Great Heading {#custom-id}
The HTML looks like this:
<h3id="custom-id">My Great Heading</h3>
Linking to Heading IDs
You can link to headings with custom IDs in the file by creating a standard link with a number sign (#) followed by the custom heading ID.
Other websites can link to the heading by adding the custom heading ID to the full URL of the webpage (e.g, [Heading IDs](https://www.markdownguide.org/extended-syntax#heading-ids)).
Definition Lists
Some Markdown processors allow you to create definition lists of terms and their corresponding definitions. To create a definition list, type the term on the first line. On the next line, type a colon followed by a space and the definition.
First Term
: This is the definition of the first term.
Second Term
: This is one definition of the second term.
: This is another definition of the second term.
The HTML looks like this:
<dl><dt>First Term</dt><dd>This is the definition of the first term.</dd><dt>Second Term</dt><dd>This is one definition of the second term. </dd><dd>This is another definition of the second term.</dd></dl>
The rendered output looks like this:
First Term
This is the definition of the first term.
Second Term
This is one definition of the second term.
This is another definition of the second term.
Strikethrough
You can strikethrough words by putting a horizontal line through the center of them. The result looks like this. This feature allows you to indicate that certain words are a mistake not meant for inclusion in the document. To strikethrough words, use two tilde symbols (~~) before and after the words.
~~The world is flat.~~ We now know that the world is round.
The rendered output looks like this:
The world is flat. We now know that the world is round.
Task Lists
Task lists allow you to create a list of items with checkboxes. In Markdown applications that support task lists, checkboxes will be displayed next to the content. To create a task list, add dashes (-) and brackets with a space ([ ]) in front of task list items. To select a checkbox, add an x in between the brackets ([x]).
- [x] Write the press release
- [ ] Update the website
- [ ] Contact the media
The rendered output looks like this:
Emoji
There are two ways to add emoji to Markdown files: copy and paste the emoji into your Markdown-formatted text, or type emoji shortcodes.
Copying and Pasting Emoji
In most cases, you can simply copy an emoji from a source like Emojipedia and paste it into your document. Many Markdown applications will automatically display the emoji in the Markdown-formatted text. The HTML and PDF files you export from your Markdown application should display the emoji.
Some Markdown applications allow you to insert emoji by typing emoji shortcodes. These begin and end with a colon and include the name of an emoji.
Gone camping! :tent: Be back soon.
That is so funny! :joy:
The rendered output looks like this:
Gone camping! ⛺ Be back soon.
That is so funny! 😂
Note: You can use this list of emoji shortcodes, but keep in mind that emoji shortcodes vary from application to application. Refer to your Markdown application's documentation for more information.
Automatic URL Linking
Many Markdown processors automatically turn URLs into links. That means if you type https://www.example.com, your Markdown processor will automatically turn it into a link even though you haven’t used brackets.
Nearly all Markdown applications support the basic syntax outlined in John Gruber’s original design document. There are minor variations and discrepancies between Markdown processors — those are noted inline wherever possible.
Headings
To create a heading, add number signs (#) in front of a word or phrase. The number of number signs you use should correspond to the heading level. For example, to create a heading level three (<h3>), use three number signs (e.g., ### My Header).
Markdown
HTML
Rendered Output
# Heading level 1
<h1>Heading level 1</h1>
Heading level 1
## Heading level 2
<h2>Heading level 2</h2>
Heading level 2
### Heading level 3
<h3>Heading level 3</h3>
Heading level 3
#### Heading level 4
<h4>Heading level 4</h4>
Heading level 4
##### Heading level 5
<h5>Heading level 5</h5>
Heading level 5
###### Heading level 6
<h6>Heading level 6</h6>
Heading level 6
Alternate Syntax
Alternatively, on the line below the text, add any number of == characters for heading level 1 or -- characters for heading level 2.
Markdown
HTML
Rendered Output
Heading level 1 ===============
<h1>Heading level 1</h1>
Heading level 1
Heading level 2 ---------------
<h2>Heading level 2</h2>
Heading level 2
Heading Best Practices
Markdown applications don’t agree on how to handle a missing space between the number signs (#) and the heading name. For compatibility, always put a space between the number signs and the heading name.
✅ Do this
❌ Don't do this
# Here's a Heading
#Here's a Heading
Paragraphs
To create paragraphs, use a blank line to separate one or more lines of text.
Markdown
HTML
Rendered Output
I really like using Markdown.
<p>I really like using Markdown.</p>
I really like using Markdown.
I think I'll use it to format all of my documents from now on.
<p>I think I'll use it to format all of my documents from now on.</p>
I think I’ll use it to format all of my documents from now on.
Don't put tabs or spaces in front of your paragraphs.
This can result in unexpected formatting problems.
Keep lines left-aligned like this.
Don't add tabs or spaces in front of paragraphs.
Line Breaks
To create a line break (<br>), end a line with two or more spaces, and then type return.
In Markdown:
This is the first line. And this is the second line.
In HTML:
<p>This is the first line.<br> And this is the second line.</p>
Rendered
This is the first line.
And this is the second line.
Line Break Best Practices
You can use two or more spaces (commonly referred to as “trailing whitespace”) for line breaks in nearly every Markdown application, but it’s controversial. It’s hard to see trailing whitespace in an editor, and many people accidentally or intentionally put two spaces after every sentence. For this reason, you may want to use something other than trailing whitespace for line breaks. Fortunately, there is another option supported by nearly every Markdown application: the <br> HTML tag.
For compatibility, use trailing white space or the <br> HTML tag at the end of the line.
There are two other options I don’t recommend using. CommonMark and a few other lightweight markup languages let you type a backslash (\) at the end of the line, but not all Markdown applications support this, so it isn’t a great option from a compatibility perspective. And at least a couple lightweight markup languages don’t require anything at the end of the line — just type return and they’ll create a line break.
✅ Do this
First line with two spaces after.
And the next line.
First line with the HTML tag after.<br>And the next line.
❌ Don’t do this
First line with a backslash after.\
And the next line.
First line with nothing after.
And the next line.
Emphasis
Bold and Italic
To emphasize text with bold and italics at the same time, add three asterisks or underscores before and after a word or phrase. To bold and italicize the middle of a word for emphasis, add three asterisks without spaces around the letters.
Markdown
HTML
Rendered Output
This text is ***really important***.
This text is <strong><em>really important</em></strong>.
This text is really important.
This text is ___really important___.
This text is <strong><em>really important</em></strong>.
This text is really important.
This text is __*really important*__.
This text is <strong><em>really important</em></strong>.
This text is really important.
This text is **_really important_**.
This text is <strong><em>really important</em></strong>.
This text is really important.
This is really***very***important text.
This is really<strong><em>very</em></strong>important text.
This is reallyveryimportant text.
Bold and Italic Best Practices
Markdown applications don’t agree on how to handle underscores in the middle of a word. For compatibility, use asterisks to bold and italicize the middle of a word for emphasis.
✅ Do this
❌ Don't do this
This is really***very***important text.
This is really___very___important text.
Blockquotes
To create a blockquote, add a > in front of a paragraph.
> Dorothy followed her through many of the beautiful rooms in her castle.
The rendered output looks like this:
Dorothy followed her through many of the beautiful rooms in her castle.
Blockquotes with Multiple Paragraphs
Blockquotes can contain multiple paragraphs. Add a > on the blank lines between the paragraphs.
> Dorothy followed her through many of the beautiful rooms in her castle.
>
> The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
The rendered output looks like this:
Dorothy followed her through many of the beautiful rooms in her castle.
The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Nested Blockquotes
Blockquotes can be nested. Add a >> in front of the paragraph you want to nest.
> Dorothy followed her through many of the beautiful rooms in her castle.
>
>> The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
The rendered output looks like this:
Dorothy followed her through many of the beautiful rooms in her castle.
The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Blockquotes with Other Elements
Blockquotes can contain other Markdown formatted elements. Not all elements can be used — you’ll need to experiment to see which ones work.
> #### The quarterly results look great!
>
> - Revenue was off the chart.
> - Profits were higher than ever.
>
> *Everything* is going according to **plan**.
The rendered output looks like this:
The quarterly results look great!
Revenue was off the chart.
Profits were higher than ever.
Everything is going according to plan.
Lists
You can organize items into ordered and unordered lists.
Ordered Lists
To create an ordered list, add line items with numbers followed by periods. The numbers don’t have to be in numerical order, but the list should start with the number one.
Markdown
HTML
Rendered Output
1. First item
2. Second item
3. Third item
4. Fourth item
To create an unordered list, add dashes (-), asterisks (*), or plus signs (+) in front of line items. Indent one or more items to create a nested list.
Markdown
HTML
Rendered Output
- First item
- Second item
- Third item
- Fourth item
To add another element in a list while preserving the continuity of the list, indent the element four spaces or one tab, as shown in the following examples.
Paragraphs
* This is the first list item.
* Here's the second list item.
I need to add another paragraph below the second list item.
* And here's the third list item.
The rendered output looks like this:
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
Blockquotes
* This is the first list item.
* Here's the second list item.
> A blockquote would look great below the second list item.
* And here's the third list item.
The rendered output looks like this:
This is the first list item.
Here’s the second list item.
A blockquote would look great below the second list item.
And here’s the third list item.
Code Blocks
Code blocks are normally indented four spaces or one tab. When they’re in a list, indent them eight spaces or two tabs.
1. Open the file.
2. Find the following code block on line 21:
<html>
<head>
<title>Test</title>
</head>
3. Update the title to match the name of your website.
The rendered output looks like this:
Open the file.
Find the following code block on line 21:
<html>
<head>
<title>Test</title>
</head>
Update the title to match the name of your website.
Images
1. Open the file containing the Linux mascot.
2. Marvel at its beauty.

3. Close the file.
The rendered output looks like this:
Open the file containing the Linux mascot.
Marvel at its beauty.
Close the file.
Code
To denote a word or phrase as code, enclose it in backticks (`).
Markdown
HTML
Rendered Output
At the command prompt, type `nano`.
At the command prompt, type <code>nano</code>.
At the command prompt, type nano.
Escaping Backticks
If the word or phrase you want to denote as code includes one or more backticks, you can escape it by enclosing the word or phrase in double backticks (``).
Markdown
HTML
Rendered Output
``Use `code` in your Markdown file.``
<code>Use `code` in your Markdown file.</code>
Use `code` in your Markdown file.
Code Blocks
To create code blocks, indent every line of the block by at least four spaces or one tab.
<html>
<head>
</head>
</html>
The rendered output looks like this:
<html>
<head>
</head>
</html>
Note: To create code blocks without indenting lines, use fenced code blocks.
To create a horizontal rule, use three or more asterisks (***), dashes (---), or underscores (___) on a line by themselves.
***
---
_________________
The rendered output of all three looks identical:
Horizontal Rule Best Practices
For compatibility, put blank lines before and after horizontal rules.
✅ Do this
Try to put a blank line before...
---
...and after a horizontal rule.
❌ Don’t do this
Without blank lines, this would be a heading.
---
Don't do this!
Links
To create a link, enclose the link text in brackets (e.g., [Duck Duck Go]) and then follow it immediately with the URL in parentheses (e.g., (https://duckduckgo.com)).
My favorite search engine is [Duck Duck Go](https://duckduckgo.com).
You can optionally add a title for a link. This will appear as a tooltip when the user hovers over the link. To add a title, enclose it in parentheses after the URL.
My favorite search engine is [Duck Duck Go](https://duckduckgo.com "The best search engine for privacy").
Reference-style links are a special kind of link that make URLs easier to display and read in Markdown. Reference-style links are constructed in two parts: the part you keep inline with your text and the part you store somewhere else in the file to keep the text easy to read.
Formatting the First Part of the Link
The first part of a reference-style link is formatted with two sets of brackets. The first set of brackets surrounds the text that should appear linked. The second set of brackets displays a label used to point to the link you’re storing elsewhere in your document.
Although not required, you can include a space between the first and second set of brackets. The label in the second set of brackets is not case sensitive and can include letters, numbers, spaces, or punctuation.
This means the following example formats are roughly equivalent for the first part of the link:
[hobbit-hole][1]
[hobbit-hole] [1]
Formatting the Second Part of the Link
The second part of a reference-style link is formatted with the following attributes:
The label, in brackets, followed immediately by a colon and at least one space (e.g., [label]: ).
The URL for the link, which you can optionally enclose in angle brackets.
The optional title for the link, which you can enclose in double quotes, single quotes, or parentheses.
This means the following example formats are all roughly equivalent for the second part of the link:
You can place this second part of the link anywhere in your Markdown document. Some people place them immediately after the paragraph in which they appear while other people place them at the end of the document (like endnotes or footnotes).
An Example Putting the Parts Together
Say you add a URL as a standard URL link to a paragraph and it looks like this in Markdown:
In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends
of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to
eat: it was a [hobbit-hole](https://en.wikipedia.org/wiki/Hobbit#Lifestyle "Hobbit lifestyles"), and that means comfort.
Though it may point to interesting additional information, the URL as displayed really doesn’t add much to the existing raw text other than making it harder to read. To fix that, you could format the URL like this instead:
In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends
of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to
eat: it was a [hobbit-hole][1], and that means comfort.
[1]: <https://en.wikipedia.org/wiki/Hobbit#Lifestyle> "Hobbit lifestyles"
In both instances above, the rendered output would be identical:
In a hole in the ground there lived a hobbit. Not a nasty, dirty, wet hole, filled with the ends of worms and an oozy smell, nor yet a dry, bare, sandy hole with nothing in it to sit down on or to eat: it was a hobbit-hole, and that means comfort.
Markdown applications don’t agree on how to handle spaces in the middle of a URL. For compatibility, try to URL encode any spaces with %20.
✅ Do this
❌ Don't do this
[link](https://www.example.com/my%20great%20page)
[link](https://www.example.com/my great page)
Images
To add an image, add an exclamation mark (!), followed by alt text in brackets, and the path or URL to the image asset in parentheses. You can optionally add a title after the URL in the parentheses.

The rendered output looks like this:
Linking Images
To add a link to an image, enclose the Markdown for the image in brackets, and then add the link in parentheses.
[](https://www.flickr.com/photos/beaurogers/31833779864/in/photolist-Qv3rFw-34mt9F-a9Cmfy-5Ha3Zi-9msKdv-o3hgjr-hWpUte-4WMsJ1-KUQ8N-deshUb-vssBD-6CQci6-8AFCiD-zsJWT-nNfsgB-dPDwZJ-bn9JGn-5HtSXY-6CUhAL-a4UTXB-ugPum-KUPSo-fBLNm-6CUmpy-4WMsc9-8a7D3T-83KJev-6CQ2bK-nNusHJ-a78rQH-nw3NvT-7aq2qf-8wwBso-3nNceh-ugSKP-4mh4kh-bbeeqH-a7biME-q3PtTf-brFpgb-cg38zw-bXMZc-nJPELD-f58Lmo-bXMYG-bz8AAi-bxNtNT-bXMYi-bXMY6-bXMYv)
The rendered output looks like this:
Escaping Characters
To display a literal character that would otherwise be used to format text in a Markdown document, add a backslash (\) in front of the character.
\* Without the backslash, this would be a bullet in an unordered list.
The rendered output looks like this:
* Without the backslash, this would be a bullet in an unordered list.
Characters You Can Escape
You can use a backslash to escape the following characters.
Many Markdown applications allow you to use HTML tags in Markdown-formatted text. This is helpful if you prefer certain HTML tags to Markdown syntax. For example, some people find it easier to use HTML tags for images. Using HTML is also helpful when you need to change the attributes of an element, like specifying the color of text or changing the width of an image.
To use HTML, place the tags in the text of your Markdown-formatted file.
This **word** is bold. This <em>word</em> is italic.
The rendered output looks like this:
This word is bold. This word is italic.
HTML Best Practices
For security reasons, not all Markdown applications support HTML in Markdown documents. When in doubt, check your Markdown application’s documentation. Some applications support only a subset of HTML tags.
Use blank lines to separate block-level HTML elements like <div>, <table>, <pre>, and <p> from the surrounding content. Try not to indent the tags with tabs or spaces — that can interfere with the formatting.
You can’t use Markdown syntax inside block-level HTML tags. For example, <p>italic and **bold**</p> won’t work.
To create paragraphs, use a blank line to separate one or more lines of text.
Don’t ident paragraphs with spaces or tabs
Syntaxes
This is the first paragraph.
This is the second paragraph
Showcases
This is the first paragraph.
This is the second paragraph
1.3 Line Break
Notes:
To create a line break, end a line with two or more spaces, and then type return
Or use the <br> HTML tag
Syntaxes
This is the first line.
And this is the second line.
Showcases
This is the first line.
And this is the second line.
Alternative Syntaxes
First line with the HTML tag after.<br>And the next line.
Showcases
First line with the HTML tag after.
And the next line.
1.4. Emphasis
Syntaxes
**This is bold text**
__This is bold text__*This is italic text*_This is italic text_We have **bold***italic*
This text is ***really important***
This text is ___really important___This text is __*really important*__
This text is **_really important_**
Showcases
This is bold textThis is bold textThis is italic textThis is italic text
We have bolditalic
This text is really important
This text is really important
This text is really important
This text is really important
1.5. Blockquotes
Notes:
Space is needed after the marker >;
You could just add only one > at the first line;
Blockquotes can be nested
Blockquotes can contain multiple paragraphs. Add a > between the paragraphs.
Blockquotes can contain other Markdown formatted elements. But not all elements can be used.
Syntaxes
> Blockquotes can also be nested...
>> ...by using additional greater-than signs right next to each other...
> > > ...or with spaces between arrows.
Showcases
Blockquotes can also be nested…
…by using additional greater-than signs right next to each other…
…or with spaces between arrows.
Syntaxes
> Dorothy followed her through many of the beautiful rooms in her castle.
>
> The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Showcases
Dorothy followed her through many of the beautiful rooms in her castle.
The Witch bade her clean the pots and kettles and sweep the floor and keep the fire fed with wood.
Syntaxes
> #### The quarterly results look great!
>
> - Revenue was off the chart.
> - Profits were higher than ever.
>
> *Everything* is going according to **plan**.
Showcases
The quarterly results look great!
Revenue was off the chart.
Profits were higher than ever.
Everything is going according to plan.
1.6. Lists
1.6.1. Unordered
Syntaxes
+ To start a list, there should be an empty line above
+ Create a list by starting a line with `+`, `-`, or `*`- Changing the sign will add a linespace
+ Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
- Sub-lists are made by indenting 2 spaces:
* Item 2a
* Item 2b
* Item 3
To end a list, there should be one empty line above.
Showcases
To start a list, there should be an empty line above
Create a list by starting a line with +, -, or *
Changing the sign will add a linespace
Add text under an item
This is a text under an item. Notice that there are two spaces at the end above.
Sub-lists are made by indenting 2 spaces:
Item 2a
Item 2b
Item 3
To end a list, there should be one empty line above.
1.6.2. Ordered
Syntaxes
1. Item 1
1. Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
3. Sub-lists are made by indenting 4 spaces
1. Item 3a
2. Item 3b
8. Any number for item 4
Showcases
Item 1
Item 2
Notice that the sequence number is irrelevant.
Markdown will change the sequence automatically when renderring.
Notice that there are two spaces at the end above to make a new text under item.
Sub-lists are made by indenting 4 spaces
Item 3a
Item 3b
Any number for item 4
Syntaxes
57. will started with offset 57
1. so it will be 58
Showcases
will started with offset 57
so it will be 58
1.7. Elements in Lists
Notes:
To add another element in a list while preserving the continuity of the list, indent the element four spaces or one tab
Syntaxes
* This is the first list item.
* Here's the second list item.
I need to add another paragraph below the second list item.
* And here's the third list item.
Showcases
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
Showcases
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
Showcases
This is the first list item.
Here’s the second list item.
A blockquote would look great below the second list item.
And here’s the third list item.
Syntaxes
1. Open the file containing the Linux mascot.
2. Linux mascot called Tux.

3. Tux is cool.
Showcases
Open the file containing the Linux mascot.
Linux mascot called Tux.
Tux is cool.
But, for text element in ordered list, add five spaces
This is the first list item.
Here’s the second list item.
I need to add another paragraph below the second list item.
And here’s the third list item.
But, for quote in ordered list, add five spaces
This is the first list item.
Here’s the second list item.
A blockquote would look great below the second list item.
And here’s the third list item.
But, for code blocks in the lists, add eight spaces or two tabs.
Open the file.
Find the following code block on line 21:
<html>
<head>
<title>Test</title>
</head>
Update the title to match the name of your website.
1.8. Code
Notes:
Inline codes is written inside ` `
or idented by add four spaces or one tab before
Syntaxes
This is inline `code`.
Showcases
This is inline code.
Syntaxes
// Some comments
line 1 of code
line 2 of code
line 3 of code
Showcases
// Some comments
line 1 of code
line 2 of code
line 3 of code
It is not recommended to use image links in reference format. Some apps will not preview those images.
Specifying size of image is supported only in some extended markdown (such as markdown-it).
Syntaxes





we can add formatting text, links, code and HTML character code, but not: heading, headings, blockquotes, lists, horizontal rules, images, HTML tags, or fenced code
Syntaxes
| Option | Description |
| ------ | ----------- |
| data | path to data files to supply the data that will be passed into templates. |
| engine | engine to be used for processing templates. Handlebars is the default. |
| ext | extension to be used for dest files. |
Showcases
Option
Description
data
path to data files to supply the data that will be passed into templates.
engine
engine to be used for processing templates. Handlebars is the default.
ext
extension to be used for dest files.
Syntaxes
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| Header from | Title | Here's this is |
| Paragraph | Text | And more |
Showcases
Syntax
Description
Test Text is long
Header from
Title
Here’s this is
Paragraph
Text
And more
Syntaxes
| Syntax | Description | Test Text is long |
| :--- | :----: | ---: |
| [Example](https://www.example.com/) | **Title** | `Here's this is` |
| Paragraph | Text | And more |
sequenceDiagram
participant Alice
participant Bob
Alice->>John: Hello John, how are you?
loop Healthcheck
John->>John: Fight against hypochondria
end
Note right of John: Rational thoughts <br/>prevail!
John-->>Alice: Great!
John->>Bob: How about you?
Bob-->>John: Jolly good!
Gantt diagram
gantt
dateFormat YYYY-MM-DD
title Adding GANTT diagram to mermaid
excludes weekdays 2014-01-10
section A section
Completed task :done, des1, 2014-01-06,2014-01-08
Active task :active, des2, 2014-01-09, 3d
Future task : des3, after des2, 5d
Future task2 : des4, after des3, 5d
@startuml
participant User
User -> A: DoWork
activate A
A -> B: << createRequest >>
activate B
B -> C: DoWork
activate C
C --> B: WorkDone
destroy C
B --> A: RequestCreated
deactivate B
A -> User: Done
deactivate A
@enduml
Remove all notifications from non-message & calendar apps. Disable all notifications except for the calendar and clock. Disable notifications.
Move all non-essential apps off of the front page (perhaps even off of a “page” entirely).
Condition everyone around you that you might not reply messages in time
Get another device without ANY distraction what so ever. Having a dedicated device for our priority and minimizing adding more stuff to it.
Delete every recreational app on your phone. Also delete anything that gamifies passive consumption.
Do not open your web browser unless you have a specific search query in mind.
Treat your phone as if it had no online connectivity. When you open the phone, use it to organize your notes and structure your thinking. Begin thinking of it as an extension of your brain instead of a bottomless anti-boredom device. As a thought experiment, imagine you had a smart phone without internet access
Put some ebooks on your phone and read those. Stop mentally associating the phone with the infinite novelty generated by algorithmic social feeds.
Get rid of all the apps where you consume content, except for maybe an eBook reading app. Fill your devices only with apps that allow you to create content. Don’t even worry about sharing the content. Just get apps that let you create. Photography, video, code, drawing, writing, music, whatever.
Finding alternatives to screens is probably a good start. You don’t need to toss your phone, just put it farther away from you. Have books/magazines/newspapers with easy access as an alternative. Legos/brain teasers/puzzles/rubix cubes, etc are also great.
Get rid of the social media apps. You don’t need them. You’re lying to yourself if you think that you do. Nobody is going to miss your Instagram or Facebook posts. TikTok is a stupid waste of time.
Instead, fill your home screen with apps with positive goals.
The answer is simple: Stop using smartphone except for explicit reasons. If I want to dick around with tech - I’ll use my desktop/laptop.
Level 1 (0h - 2h): Blood Sugar Rises. You’ll feel pretty normal during the first fast hours of fasting because your body is going through the regular process of breaking down glycogen. Your bloood sugar rises. Your pancreas releases insulin to break down glucose for energy and stores the extra glucose for later.
Level 2 (2h - 5h): Blood Sugar Falls. As a result of the effects of insulin, your blood sugar decreases to near normal after spiking. And it typically doesn’t continue climbing because insulin is immediately delivered into your circulatory system after eating.
Level 3 (5h - 8h): Blood Sugar Returns to Normal. At this stage, your blood sugar level returns to normal. Feeling hungry? Your stomach is reminding you that it’s been a while since your last meal; however, you’re not actually that hungry. Starve to death? Shrivel up and lose your muscle mass? None of this is going to happen. Actually, your glycogen reserves will begin to fall, and you might even lose a little body fat. Your body will continue to digest your last food intake. It starts to use stored glucose for energy, and continues to function as if you’ll eat again soon.
Level 4 (8h - 10h): Switch into Fasting Mode. 8 hours after your last meal, your liver will use up the last of its glucose reserves. Now your body goes into a state called gluconeogenesis, which indicates that your body has switched into the fasting mode. Studies show that gluconeogenesis, a metabolic pathway, results in the generation of glucose from body fat instead of carbohydrates. It increases your calorie burning.
Level 5 (10h - 12h): Little Glycogen Left. Your glycogen reserves are running out! As a result, you may become irritable or hangry. Just relax, it’s a sign that your body is burning fat! With little glycogen left, fat cells (adipocyte) will release fat into your bloodstream. They also go straight into your liver and are converted into energy for your body. Actually, you are cheating your body into burning fat in order to survive.
Level 6 (12h - 18h): You’re in the Ketosis State!. Now it’s the turn of fat to fuel your body. You’re in the metabolic state called ketosis. The glycogen is almost used up and your liver converts fat into ketone bodies - an alternative energy source for your body. Fat reserves are readily released and consumed. For this reason, ketosis is sometimes referred to as the body’s fat-burning" mode. Ketosis produces fewer inflammatory by-products, so it provides health benefits to your heart, metabolism and brain.
Level 7 (18h - 24h): Fat Burning Mode Starts!. The longer you fast, the deeper into ketosis you’ll go. By 18 hours, your body has switched into fat-burning mode. Research shows that after fasting for 12 to 24 hours, the energy supply from fat will increase by 60%, and it has a significant increase after 18 hours. Now (1) The level of ketone bodies rises, and (2) ketones act as signaling molecules to tell your body how to better regulate its metabolism in a stressful environment, and (3) your body’s anti-inflammatory and rejuvenation processes are ready to work.
Level 8 (24h - 48h): Autophagy Starts!. At this point, your body triggers autophagy (literally means “self-devouring”). Cells start to clean up their house. They remove unnecessary or dysfunctional components. It’s a good thing because it allows the orderly degradation and recycling of cellular components. During autophagy, cells break down viruses, bacteria and damaged components. In this process, you get the energy to make new cell parts. It’s significant for cell’s health, renewal, and survival. The main benefit of autophagy is best known as the body turning the clock back and creating younger cells.
Level 9 (48h - 56h): Growth Hormone Goes Up. Your growth hormone level is much higher than the level at which it was before fasting. This benefits from the ketone bodies production and hunger hormone secretion during fasting. Growth hormone helps increase your lean muscle mass and improve your cardiovascular health.
Level 10 (56h - 72h): Sensitive to Insulin. Your insulin is at its lowest level since fasting. It makes you more insulin sensitive, which is an especially good thing if you have a high risk of developing diabetes. Lowering your insulin levels has a range of health benefits both short term and long term, such as activating autophagy and reducing inflammation.
Level 11 (72h): Immune Cells Regenerate. “Survival of the fittest.” Your body turns down cellular survival pathways and recycles immune cells that are damaged when fighting viruses, bacteria, and germs. In order to fill “the vacancy of the guardians”, your body regenerates new immune cells at a rapid pace. It starts the immune system regeneration and shifts cells to a state of self-renewal. Your immune system becomes stronger and stronger.
10.3 - Daily Wisdom
Daily Wisdom
In Nature there are neither rewards nor punishments, there are consequences. – R.G. Ingersoll
Have constant reminders/cues (what’s important, dreams/expectations)
Use motivators (music, dreams/aspirations, good and bad)
Use structure/schedule
Maintain the same routine, regardless of schedule. Adjust only what is necessary.
Prioritize (short-term as well as long-term)
Maintain focus/single-tasking
Remove/prevent distractions
Track tasks done/accomplishments
Work vs ‘doing stuff’
Look ahead, look back
Tackle difficult tasks/situations
Appropriate assertiveness
Time-limit side treks (eating, news, exploration, entertainment, breaks)
Don’t worry about things, do things
Budget marketing (time, money)
Budget professional development (time, money)
Reduce discomfort through familiarity/repetition/exposure
Set goals to ‘good enough’/iterative development
Review lessons learned periodically to solidify/refresh them
Take small steps
Don’t get emotionally overloaded
Prioritize tasks that are sliding
Don’t pick apart a good idea, pursue it
Treat failures as false starts & learning experiences (training exercises)
Music on 5 minutes before up/downtime (music as motivator)
Use caffeine to maintain alertness and focus. If it’s too late in the day for caffeine, GO TO BED.
Just START WORKING
Maintain an appropriate sense of urgency (but avoid panic and burnout)
Take regular stretch breaks (1 minute per 15)
End work based on bedtime, not time of day
Use zazen (shikantaza) to overcome ‘scattered thoughts’ (too many thoughts or anxious thoughts)
Don’t focus on how little time you have, but on what you can get done in the time you have.
If you don’t want to do something, DO it and get it out of the way.
Start with the MOST IMPORTANT TASK of the day. Everything else can wait.
Risk and uncertainty are normal parts of life. Manage them effectively.
A life is built one thought, one choice, one action at a time.
Start the day with an unpleasant task, to get it out of the way (’eat the frog’).
#1 underlying principle: Be proactive (and thereby stay in control).
My primary motivator is: Responsibility (reactive)
Be yourself. Do your thing.
Program a ‘computer-free day’ per week.
Use habits to: Reduce processing overhead, Simplify things, Reduce chances for getting off-track, Reduce ability of subconscious to derail
Don’t allow a slipped schedule to be an excuse for avoiding things.
When projects are slipping, focus exclusively on blockers. Everything else can wait.
‘Do very few things, but be awesome at them.’
‘Do less shallow work — focus on the deep stuff.’
Create your own stability.
You can be successful without being happy (i.e., you don’t need to be happy in order to be successful; you can still be successful even if you aren’t able to be happy).
Focus on what you are responsible for.
To avoid binging something, limit yourself to one unit per day; if appropriate, follow it with something (anything) else
For video entertainment, set a goal of ‘saving’ before the end/climacs (preemptive pause); don’t get hooked to continue to the next unit (level, show, etc.)
You don’t need to feel good all the time (i.e., even if you don’t feel good, keep moving forward).
When you feel overwhelmed, pick ONE THING to focus on, ignore everything else; then when that’s done, pick ONE THING….
Don’t ‘chain’ tasks if it causes the whole chain to be put off; do what you can NOW and worry about the rest later
If you can’t do everything that needs to be done, do SOMETHING (could be a small piece of ’everything’, or just one more-manageable task)
I don’t need to feel good to do daily things.
You can’t make up for lost time; make the best of what you have (left).
Work is life (life requires work).
Don’t focus on what’s wrong, but on what can be done to make things better.
3..2..1 (countdown, then just do it)
Eat the frog!
10.4 - Habit
Habit
Mindfulness Habit
Physical Wellness
Avoid Alcohol
Avoid Caffeine
Avoid Sugar
Dim the Lights
Eat Healthier Foods
Floss
Get Enough Sunlight
Go for a Run
Go for a Walk (20 mins)
Go to bed on time, enough sleep (7-9 hours)
Maintain Better Posture
Practice Deep Breathing
Stay Hydrated
Stretch it Out
Wake up Earlier
Social Wellness
Step outside your comfort zone, get more experiences
Advisor should express his expectations for student finishing and tailoring those expectations to student career goals clear up front
Each time, make evaluation of those expectations
Create a expectation document, for example, it will contain target like:
1 journal paper as the first author, so that they learn how that process (often is a review or perspective paper on their field, which goes in their dissertation)
2 first author papers in top-tier machine learning venues (goes in dissertation)
1 first author paper in a top-tier or second tier venue (goes in dissertation)
1 collaborative paper with another PhD student (have to learn how to collaborate)
At the beginning of the day, create one goal that I have to accomplish that day. The goal needs to be specific enough that I can definitively say when its done, and it needs to be completely realistic for me to finish it that day, so that I can say “Yes, I can definitely do this. No excuses”. It also needs to be significant enough that at the end of the week, even if I only did those goals, I would still feel like Im making some consistent progress. Typically the goals I choose are things that might take one to two hours of focused effort.
Only do one thing at a time, and log what I’m doing as I go. Before I start a task, I write down what Im about to do. When I finish the task, I check it off and write the next bullet point. If something comes up while executing the task, like realizing I have a question I need to ask someone, instead of asking them right away, I will write down a “TODO” in-line in my log and box it to come back to later. So if the task is “Check email”, I write down “Check email”, open my email, read it and execute only small tangential tasks (so, e.g., I dont see an email about a code review and then get distracted and go do the code review), and when Im done, I quit my email and check off my task. I do the same for Slack, which means I dont leave it open in the background. If I take a break, I write “Break” and check it off when I’m done and come back to my desk. I write my big goal at the top of the page and when I finish it, I box it and check it off for some extra satisfaction. At the end of the day I write DONE and box it, to get some closure. Note: I find if I write down 5 tasks and cross them off one by one, I will gravitate to the short easy ones first for instant gratification.
Leave my phone in the other room while I’m working. It seems that I really do have to be physically separated from it by a significant distance to keep from being distracted by it.
10.9 - Digital Literacy
Digital Literacy
Digital literacy is
skill to live, learn, and work where communication and acces to information is through digital technologies (internet platforms, social media, mobile devices)
ability to find, evaluate, and clearly communicate information through typing and other media on various digital platforms
the ability to use information and communication technologies to find, evaluate, create, and communicate information, requiring both cognitive and technical skills
Level:
Accesss
Use:
Techincal fluency
Understand
Recognize impact
Recognize potential
Create
Skill:
Critical Thinking
Communication and Collaboration Skills
Clearly express ideas
ask relevant questions
maintain respect
Practical Technical Skills
how to access
how to manage
how to create information
Social and Cultural Skills
Competency
Critical thinking
Online safety
Digital culture (social cultural understanding skill)
Collaboration
Creativity
Finding Information
Effective Communication and Netiquette
Functional skill
Key points
Digital media are networked.
Digital media are persistent, searchable and shareable.
Digital media have unknown and unexpected audiences.
Digital media experiences are real, but don’t always feel real.
How we respond and behave when using digital media is influenced by the architecture of the platforms, which reflects the biases and assumptions of their creators.
Digital Literacy Skills
Ethics and Empathy (ethical decisions : cyberbullying, sharing other people’s content).
Privacy and Security (online privacy, reputation and, how to share, understanding data collection, malware and phising, digital footprint awareness).
Community Engagement (citizen rights, positive influence, active, engaged citizens.
Digital Health (managing screen time, balancing online and offline lives, managing online identity; dealing with digital media; understanding unhealthy online relationships.
Consumer Awareness (digital world is commercialized online environments: recognizing and interpreting advertising, branding and consumerism; reading and understanding the implications of website Terms of Service and privacy policies; and being savvy consumers online).
Finding and Verifying (skills to effectively search the Internet, and then evaluate and authenticate the sources and information they find)
Making and Remixing (making and remixing skills to create digital content, understanding legal and ethical considerations, and to use digital platforms to collaborate with others.
Goal of Digital Literacy
Critical/creative thinking
Constructive social action
ICT Innovation (in ICT or with ICT)
Access:
Distribution, Infrastructure, Tools
Use:
Navigation skills
Accessing skills
Tools related skills
Understand
Right and Responsibility
Scial awareness and identity
Judgement
Safety and security
Decision making
Create
Problem solving
Synthesizing
Culturel empowerment
Critical Thinking
Basic of Critical Thinking:
Analyse and evaluate information and arguments
See patterns and connections,
Identify and build meaningful information
Strategy of Critical Thinking:
Who (siapa yang menulis, untuk siapa, siapa yang diuntungkan, siapa yang dipengaruhi, siapa sumbernya, siapa yang mensponsori?)
What (apa yang tidak disampaikan kepada kita, apa pendapat yang berbeda, apa yang lebih penting dari yang disampaikan, apa kekuatan dan kelemahannya, apa lagi detil yang harus kita ketahui)
Where (dari mana informasi ini datang, di mana itu terjadi, di mana bukti pendukungnya)
When (kapan terjadi, kapan dibuat, kapan diperbarui informasinya, kapan kejadian yang sama terjadi di masa lalu)
Why (mengapa ini dibuat, mengapa memilih pandangan semacam itu, mengapa ini penting dan relevan)
How (bagaimana aku bisa tahu ini benar, bagaimana meyakinkan, bagaimana ini akan bermanfaat)
Online Safety
Problem: cyber bullying, sexting, age-appropriate content, photo sharing and permission, Online extortion, Online exploitation, Plagiarism and copyright, Virus protection
Quick guide for online safety
know risks
keep your personal information safe
Be kind online
don’t download unknown thing
Digital culture
Problems: transhumanism, AI, cyber ethics, security, privacy, hacking, social engineering, modern psychology
Digital Collaboration
including: digital team, digital discovery, digital content creation, digital communication, digital presentation
Finding Information
think before begin
where are you searching?
dig deep of the search results
check the website/link
take closer look (credibility)
look beyond the headline
camera can lie, keyboard can lie
virality is not accuracy
check other sources, compare
check the fact
check your bias
is it a joke?
ask the experts
Communication Skills
Online shairng tips
share only what you fell comfortable with
avoid sharing your location/identity
be mindful of other people’s feelings
pay attention to your privacy settings
don’t share every photo/video
Netiquette
behaviour : respect people, avouid cyberbullies
language: think before click, every character matters
10 Langkah Aksi Literasi Digital
[1] Jaga Privasi Digital
[2] Amankan Data Digital
[3] Waspadai Bahaya Digital
[4] Kritis terhadap Informasi
[5] Verifikasi setiap Informasi
[6] Komunikasi Digital dengan Etis
[7] Empati terhadap Warga Digital
[8] Kolaborasi Positif secara Digital
[9] Tepat dalam Mencari Informasi Digital
[10] Buat Kreasi Inovasi Digital
Proyek: Pelatihan Kecakapan Literasi Digital
Apa itu Literasi Digital?
Literasi Digital adalah
kemampuan dalam belajar, bekerja, dan hidup dengan menggunakan teknologi digital (internet, media sosial, perangkat mobile) sebagai sarana komunikasi dan akses informasi.
kemampuan menemukan, menilai, dan menyampaikan informasi dengan menggunakan perangkat digital
pengetahuan dan kemampuan teknis untuk menggunakan teknologi komunikasi dan informasi untuk mencari, menilai, membuat, dan menyampaikan informasi
Apa tujuan dari Literasi Digital
Masyarakat dapat meningkatkan kemampuan berpikir kreatif dan kritis dengan/dalam menggunakan teknologi informasi dan komunikasi
Masyarakat dapat mengembangkan inovasi dan meningkatkan kesejahteraan dengan menggunakan teknologi informasi dan komunikasi
Masyarakat dapat mengubah keadaan sosial dengan teknologi informasi dan komunikasi
Apa saja ukuran Literasi Digital suatu masyarakat?
Budaya Digital (digital culture)
Etika Digital (digital ethics)
Kecakapan Digital (digital skill)
Keamanan Digital (digital safety)
Bagaimana cara meningkatkan kecakapan Literasi Digital masyarakat?
Pelatihan kecakapan literasi digital
Sosialisasi kesadaran dan kecakapan literasi digital
Apa saja topik pelatihan dan sosialisasi Literasi Digital masyarakat?
Etika dan empati secara digital (termasuk anti cyberbullying, etika sharing).
Privasi dan keamanan digital (privasi online, keamanan data dan akses, malware dan phising, kesadaran jejak digital).
Hak dan kewajiban warga digital.
Kesehtan digital (pengaturan screen time, keseimbangan kehidupan online dan offline, mengatur identitas online, menjaga relasi online).
Copyright protection is available for various types of original creative works, including: Literary works (both fiction and non-fiction), Sound recordings, Musical works (including the musical score and lyrics), Dramatic works (such as plays, including music), Motion pictures (including those shown at movie theaters, on television (regardless of whether broadcast over-the-air, by cable, or by satellite), or over the internet), Visual artworks (such as paintings, drawings, and sculptures)
A “derivative work” is a work based upon one or more preexisting works, such as a translation, musical arrangement, dramatization, fictionalization, motion picture version, sound recording, art reproduction, abridgment, condensation, or any other form in which a work may be recast, transformed, or adapted. A work consisting of editorial revisions, annotations, elaborations, or other modifications which, as a whole, represent an original work of authorship, is a “derivative work.”
There must be major or substantial new material for a work to be considered copyrightable as a derivative work. The new material must be sufficiently original and creative to be copyrightable by itself.
Common examples of derivative works are: A new, updated or revised, edition of a book, A translation of a book into another language, A sequel to a novel or motion picture, A novel adapted to a screenplay, stage production, or motion picture, A new musical arrangement of a composition.
There are two ways that derivative rights are protected under copyright law.
First, the derivative work has protection under the copyright of the original work. Copyright protection for the owner of the original copyright extends to derivative works. This means that the copyright owner of the original work also owns the rights to derivative works. Therefore, the owner of the copyright to the original work may bring a copyright infringement lawsuit against someone who creates a derivative work without permission.
Second, the derivative work itself has copyright protection. The creator of the derivative work owns the copyright to the derivative work. This can either be the creator of the original work, or someone else who has obtained a derivative work license from the holder of the original copyright. The copyright of a derivative work is separate from the copyright to the original work. Therefore, if the copyright holder gives someone a license to create a derivative work, the holder retains the copyright to the original work. In other words, only the derivative rights are being licensed.
Derivative work as a “work based or derived from one or more already existing works.”
To be copyrightable, a derivative work must incorporate some or all of a preexisting work and add new original copyrightable authorship to that work.
The term “derivative work” refers to the entire new creative work as a whole, not merely the new elements.
The copyright ownership in the derivative work is independent of any copyright protection in the preexisting material.
The copyright in the preexisting materials remains with their owner.
The owner in the preexisting work must authorize the creation of a derivative work in order for it to be separately owned by another. If not authorized, the preparation of a derivative work constitutes copyright infringement of the preexisting work and is not copyrightable.
Once the copyright owner authorizes the preparation of a derivative work, the grant to utilize the preexisting work in the derivative work created is perpetual and cannot be terminated by the owner of the preexisting work. The derivative-work owner holds all copyright rights in the new work created, including the right to license and transfer the derivative work to a third party. The derivative-work owner does not own the copyright in the preexisting material employed in the work but holds the exclusive ownership in the new derivative work. The derivative-work owner therefore can license or transfer the copyrights in the derivative work without permission from the owner of the preexisting materials.
Am I required to claim a copyright on my modifications to a GPL-covered program? You are not required to claim a copyright on your changes. In most countries, however, that happens automatically by default, so you need to place your changes explicitly in the public domain if you do not want them to be copyrighted. Whether you claim a copyright on your changes or not, either way you must release the modified version, as a whole, under the GPL
What does the GPL say about translating some code to a different programming language? Under copyright law, translation of a work is considered a kind of modification. Therefore, what the GPL says about modified versions applies also to translated versions. The translation is covered by the copyright on the original program. If the original program carries a free license, that license gives permission to translate it. How you can use and license the translated program is determined by that license. If the original program is licensed under certain versions of the GNU GPL, the translated program must be covered by the same versions of the GNU GPL.
How do I get a copyright on my program in order to release it under the GPL? Under the Berne Convention, everything written is automatically copyrighted from whenever it is put in fixed form. So you don’t have to do anything to “get” the copyright on what you write—as long as nobody else can claim to own your work. However, registering the copyright in the US is a very good idea. It will give you more clout in dealing with an infringer in the US.
The Berne Convention Implementation Act of 1988: The Berne Convention formally mandated several aspects of modern copyright law; it introduced the concept that a copyright exists from the moment that a work is “fixed”, rather than requiring registration. It also enforces a requirement that countries recognize copyrights held by the citizens of all other signatory countries.
Derivative of Derivative Works
Person A is original creator of Work0 and have licensed his work under CC-BY 4.0. Person B created a derivative work (Work1) of Person A and he attributed A in a proper way. Then Person C created a derivative work (Work2) of B, does he still need to give attribution for A?
If a license requires attribution of the original authors/copyright holders when you create a derived work, then that means you need to give attribution to all copyright holders. If Person A creates Work0, which is then adapted to Work1 by Person B, then the copyright of Work1 is shared between Jane and Alice. This means that, if the work is under a CC-BY license and Person C uses Work1 to create a derived work Work2, then Bob needs to attribute both Person A and Person B.
Copyright 2017 [Derivative Creator]
Copyright 2016 [Original Creator]
Licensed under the Apache License, Version 2.0 (the “License”); you may not use this file except in compliance with the License.
You may obtain a copy of the License at http://www.apache.org/licenses/LICENSE-2.0
This file has been modified by [Derivative Creator] to add support for foo and get faster baz processing.
This work, “[Derivative Work]”, is a derivative of “[Original Work]” by [Original Creator], used under CC BY. “[Your Work]” is licensed under CC BY by [Derivative Creator].
Copyright (c) 2016 [Original Creator]
Modifications Copyright (c) 2017 [Derivative Creator]
2017-10-01: Update the interactive streamline nosql to supply strategic users
This program is free software: you can redistribute it and/or modify it under the terms of the GNU General Public License as published by the Free Software Foundation, either version 3 of the License, or (at your option) any later version.
This program is distributed in the hope that it will be useful, but WITHOUT ANY WARRANTY; without even the implied warranty of MERCHANTABILITY or FITNESS FOR A PARTICULAR PURPOSE. See the GNU General Public License for more details.
You should have received a copy of the GNU General Public License along with this program. If not, see http://www.gnu.org/licenses/.
Copyright (c) 2019 [Derivative Creator], based on [Original Work], (c) 2014-2018 [Original Creator-1], (c) 2003-2018 [Original Creator-1]
Materials on this page were adapted from:
The Creative Commons Wiki licensed under CC BY 4.0.
How to attribute Creative Commons licensed Materials by National Copyright Unit, Copyright Advisory Groups (Schools and TAFEs) licensed under CC BY 4.0.
“Open Attribution Builder” by Open Washington, SBCTC licensed under CC BY 4.0
the fair use of a copyrighted work, including such use by reproduction in copies or phonorecords or by any other means specified by that section, for purposes such as criticism, comment, news reporting, teaching (including multiple copies for classroom use), scholarship, or research, is not an infringement of copyright
a fair use is any copying of copyrighted material done for a limited and “transformative” purpose, such as to comment upon, criticize, or parody a copyrighted work.
Such uses can be done without permission from the copyright owner.
Fair use is a defense against a claim of copyright infringement.
Main categories:
Commentary and Criticism : criticism, comment, news reporting, teaching, scholarship, or research
Parody
Four factors:
The Transformative Factor: The Purpose and Character of Your Use
Whether the material has been used to help create something new or merely copied verbatim into another work.
So check: [1] Has the material you have taken from the original work been transformed by adding new expression or meaning? [2] Was value added to the original by creating new information, new aesthetics, new insights, and understandings?
Example of transformative uses: parody, scholarship, research, or education
The Nature of the Copyrighted Work
Dissemination of facts or information benefits the public. Fair use copy from factual works (biographies, facts) is better than you do from fictional (plays or novels).
Fair use copy the material from a published work is better than from an unpublished work
The Amount and Substantiality of the Portion Taken
The less you take, the more likely that your copying will be excused as a fair use, but you are more likely to run into problems if you take the most memorable aspect of a work
The Effect of the Use Upon the Potential Market
Is whether your use deprives the copyright owner of income or undermines a new or potential market for the copyrighted work.
Common mistakes:
Acknowledgment of the source material (such as citing the photographer) may be a consideration in a fair use determination, but it will not protect against a claim of infringement. So check four factors above.
Disclaimers such as “No Copyright Intended” or fair use claims, don’t mean that the work qualifies as a fair use. If the fair use factors weigh against you, the disclaimer wont make any difference. So check four factors above.
To limit damages:
Stating something to the effect of: “No copyright is claimed in [content copied] and to the extent that material may appear to be infringed, I assert that such alleged infringement is permissible under fair use principles in U.S. copyright laws. If you believe material has been used in an unauthorized manner, please contact the poster.”
Stating disclaimers. “This book is not associated with or endorsed by the xxx Company.”
10.13 - Slide and Presentation Tips
Slide and Presentation Tips
Slide Tips
Slides that are text only distract the audience. They read the text.
Slides that are non-self-explanatory images, require the audience to listen to the speaker. Try it. Put two circles on the screen and see what people do. They look at you for explanation.
Images and photos: To help the audience remember a person, place or thing you mention, you might use images or photos. People will understand that the images represent what you’re saying, so there is no need to verbally describe the images onscreen.
Graphs and infographics. Keep graphs visually clear, even if the content is complex. Each graph should make only one point.
No slide should support more than one point.
What should the slides look like?
Use as little text as possible – if your audience is reading, they are not listening.
Avoid using bullet points. Consider putting different points on different slides.
But, slides with images and no text are a nightmare for non visual person.
So good slides are: important graphs with little text
Do not start a talk with a joke. Audience are not ready yet.
Promise - Tell them what they gonna learn at the end of your talk.
Samples
Cycle – make your idea repeated many times in order to be completely clear for everyone.
Make a “Fence” around your idea so that it can be distinguished from someone elses idea.
Verbal punctuation – sum up information within your talk some times to make listeners get back on.
Ask a question - intriguing one
Place and Time
Best time for having a lecture is 11 am (not too early and not after lunch)
The place should be well lit.
The place should be seen and checked before the lecture.
The place should not be full less than a half, it must be chosen according to the amount of listeners.
Board and Props
Board – it’s got graphics, speed, target. Watch your hands! Don’t hold them behind your back, it’s better to keep them straight and use for pointing at the board.
Props – use them in order to make your ideas visual. Visual perception is the most effective way to interact with listeners.
Projections
Don’t put too many words on a slide. Slides should just reflect what you’re saying, not the other way around. Pictures attracts attention and people start to wait for your explanation – use that tip.
Make slide as easy as you can – no title, no distracting pictures, frames, points and so on.
Do not use laser pointer – due to that you lose eye contact with the audience. Instead you can make the arrows just upon a slide.
Case: Informing (e.g. teaching)
Promise: a promise what we’will go through
Inspiration: they were inspired when someone exhibited passion about what they were doing
How to Think: Education is continuity of storytelling. So, provide audience with the stories they need to know, the questions they need to ask about those stories, mechanisms for analyzing those stories, ways of putting stories together, ways of evaluating how reliable a story is.
the most usual reason for people failing an oral exam is failure to situate and a failure to practice. By situate, it’s important to talk about our research in context (problem, solution, impact).
Job talk
Show to your listeners that your stuff is cool and interesting and you’re not a rookie
You have to be able to: (1) show your vision of that problem, (2) show that you’ve done particular things (by steps), (3) conclude
Vision of a problem that somebody cares about and something new in your approach.
How do you express the notion that you’ve done something? By listing the steps that need to be taken in order to achieve the solution to that problem.
And then you conclude by you conclude by enumerating your contributions.
All of that should be done real quick in no more than 5 min.
Getting Famous: about how you’re going to be recognized for what you do. Your ideas are
like your children, so what you want to do is to be sure that you have techniques, mechanisms, thoughts about how to present ideas that you have so that they’re recognized for the value that is in them.
If you want to your ideas be remembered you’ve got to have “5 S”:
Symbols associate with your ideas (visual perception is the best way to attract attention)
Slogan (describing your idea)
Surprise (common fallacy that is no longer true, for instance, just after you’ve told about it)
Salient Idea (an idea which not necessarily important but the one that sticks out)
Story (how you did it, how it works…)
How to Stop Pursuading Presentations
Don’t put the end with:
put collaborators at the end (do that at the beginning).
‘conclusions’ (it will better ended with ‘contributions’).
‘Thank you (for listening)’ (except, after applause).
Put the end with:
contribution
jokes, since people then will leave the event feeling fun and thus keep a good memory of your talk.
a salute to people (how much you valued the time being here, the people over here…, “I’d like to get back, it was fun!"). With this you won’t have to worry about how to end!
Instead of thinking: “What slides should I use”, try asking, “What story do I tell?”
Know your audience and prepare a story that will appeal to it
A presentation can be just like a good movie
If the story is really good, dialogue is unnecessary
Continuity is one of the main elements of a good movie and a good presentation
If something has no reason for being, get rid of it!
Activate the imagination of your audience
Confronted problems, explored the possible consequences of the problem, and created heroic solutions in the form of products
Give your audience a bit of fun
Understanding comes before engaging
A presentation is less about how good you are and more about how your advantages can help your audiences
A presentation needs action, contrasts, ups and downs and characters that are vivid
Choose a few awesome moments that will remain forever with your audience
Create state-of-the-art slide
Invest most of your time planning the message you want to convey
Think of the way you can convey content with the slides before thinking of what the visual will be
Only use on the slides text that will help guide your speech
Visuals exist to support the presenter’s speech
If the visuals are too informal, unprofessional, or imprecise, the audience will draw similar conclusions about you
The more dialogue and lettering that’s needed, the less efficient the visuals are.
Each movie scene should contain only indispensable elements. That same is true for presentation slides.
The more flexible you are when transforming the script into visuals, the better the result is going to be
It’s crucial to develop a first slide that will generate interest and excitement in everything you’re about to say
Use the potential of typography well. Play with words.
PowerPoint presentation slides are only a supporting device for the speaking portion
A presentation is a team effort between you and your slide deck.
Presenter think their work is done right about the time the PowerPoint work is finished (WRONG)
Become a better presenter
Anybody can learn to be a great presenter. You must believe that.
Take the time to master your fears.
Know your story flawlessly
Study the presentation flow and its sequencing
Practice, practice, practice, practice
Rehearse until the delivery is natural
Always keep your goal in mind, so you never lose focus.
Speak from the heart
Be spontaneous!
Speak concisely, clearly and simply
Tone of voice has an important impact, so use it as your tool in your favor
Improvise as needed, have a few backup stories
Convey enthusiasm with your voice
Make visual contact with your audience
Improve your performance level
Plan in advance, determine your objective, decide which format will work, and use only that format
Prioritizing is one of the main challenges in creating a great presentation
A presenter can engage any audience using PowerPoint in the right way
Great ideas aren’t necessarily expensive
The impact of presentation is increased meaningfully by connecting the slides either through story or through the visuals.
Stand-alone slides are a great way to make a presentation boring
The differences between face-to-face and the stand-alone presentation are important enough to kill your chances of success if you use mixed media
If you feel that your audience is sleepy or disinterested change your own inner disposition
Leave details to be discussed in a different meeting or in a document
A tiny misunderstanding can become a huge mess
Never interrupt a question from the audience it may seem arrogant on your part
The components of great presentations are universals, they go beyond slides and can be found in many other forms of art.
10.14 - Interesting Laws
Interesting Laws
Job Laws
“When a measure becomes a target, it ceases to be a good measure.”
Goodhart’s Law
“The amount of energy needed to refute bullshit is an order of magnitude larger than to produce it.”
Brandolini’s law
“In any dispute the intensity of feeling is inversely proportional to the value of the issues at stake. That is why academic politics are so bitter.”
Sayre’s Law
10.15 - Interesting Quotes
Interesting Quotes
Job Quotes
“As long as we work hard, our boss will soon be able to live the life he wants!”
Fun Quotes
The England Footbal team visited an orphanage in Russia. “It’s heartbreaking to see their little faces wth no hope”, said Vladimir, aged 6.
Academia Quote
“Academic politics are so vicious precisely because the stakes are so small.”
Sayre’s Law
“In any dispute the intensity of feeling is inversely proportional to the value of the issues at stake.”
Product Quote
I want people who use my product to be happy with it.
If they are not, I dont want them bad mouth me.
When someone is unhappy, that an excellent opportunity for me to learn, so I want to incentivize my customer to engage with me in a productive and not antagonistic way.
Fools ignore complexity. Pragmatists suffer it. Some can avoid it. Geniuses remove it.
Alan Perlis
Meaning of Life
“If our life is the only thing we get to experience, then it’s the only thing that matters. If the universe has no principles, then the only principles relevant are the ones we decide on. If the universe has no purpose, then we get to dictate what its purpose is”
Kurzgesagt
Not Stupid
If it is stupid but it works, it isn’t stupid
― Mercedes Lackey
Simple
“You live simple, you train hard, and live an honest life. Then you are free.”
― Eliud Kipchoge
Writing
“Writing is Nature’s way of showing you how sloppy your thinking is”
Bob Mugele
It is difficult to know what you should know when you have a lot to learn and are in an intelligence-signaling environment. A side effect of having written detailed technical notes is that I calibrate my confidence on a topic. If I now understand something, I am sure of it and can explain myself clearly. If I don’t understand something, I have a sense of why it is difficult to understand or what prerequisite knowledge I am missing.
The biggest benefit from education isn’t facts, its the research and critical thinking skills you develop.
The primary thing you should be deriving from your university education is how to conduct effective critical analyses.
You’re learning how to learn. While also getting some useful field-specific information out of it.
Structure and standards. Finding the right information, in the right order isn’t easy for everyone.
Education isn’t really about acquiring information; its about learning methods to engage with materials and information to draw conclusions and then express further possibilities in written and spoken form.
Metric
Any observed statistical regularity will tend to collapse once pressure is placed upon it for control purposes.
Goodhart’s law
When a measure becomes a target, it ceases to be a good measure.
Goodhart’s law by Marilyn Strathern
Brandolini’s Law (the Bullshit Asymmetry Principle):
The amount of energy needed to refute bullshit is an order of magnitude bigger than to produce it.
Shirky Principle:
“Institutions will try to preserve the problem to which they are the solution,”
Putt’s Law: “Technology is dominated by two types of people: those who understand what they do not manage and those who manage what they do not understand.”
Putt’s Corollary: “Every technical hierarchy, in time, develops a competence inversion.” –> technically competent people remain directly in charge of the actual technology while those without technical competence move into management.
Dilbert principle: “leadership is nature’s way of removing morons from the productive flow” –> that companies tend to systematically promote their least competent employees to management, to limit the amount of damage they are capable of doing.
Parkinson’s law is the adage that “work expands so as to fill the time available for its completion”. –> growth of the bureaucracy
The demand upon a resource tends to expand to match the supply of the resource (If the price is zero).The reverse is not true.
Data expands to fill the space available for storage.
If you can keep your head when all about you
Are losing theirs and blaming it on you;
If you can trust yourself when all men doubt you,
But make allowance for their doubting too;
If you can wait and not be tired by waiting,
Or, being lied about, don’t deal in lies,
Or, being hated, don’t give way to hating,
And yet don’t look too good, nor talk too wise;
If you can dream—and not make dreams your master;
If you can think—and not make thoughts your aim;
If you can meet with triumph and disaster
And treat those two impostors just the same;
If you can bear to hear the truth you’ve spoken
Twisted by knaves to make a trap for fools,
Or watch the things you gave your life to broken,
And stoop and build ’em up with wornout tools;
If you can make one heap of all your winnings
And risk it on one turn of pitch-and-toss,
And lose, and start again at your beginnings
And never breathe a word about your loss;
If you can force your heart and nerve and sinew
To serve your turn long after they are gone,
And so hold on when there is nothing in you
Except the Will which says to them: “Hold on”;
If you can talk with crowds and keep your virtue,
Or walk with kings—nor lose the common touch;
If neither foes nor loving friends can hurt you;
If all men count with you, but none too much;
If you can fill the unforgiving minute
With sixty seconds’ worth of distance run—
Yours is the Earth and everything that’s in it,
And—which is more—you’ll be a Man, my son!
Will Rogers Phenomenon
The Will Rogers phenomenon is obtained when moving an element from one set to another set raises the average values of both sets:
When the Okies left Oklahoma and moved to California, they raised the average intelligence level in both states.
The effect will occur when both of these conditions are met:
The element being moved is below average for its current set. Removing it will raise the average of the remaining elements.
The element being moved is above the current average of the set it is entering. Adding it to the new set will raise its average.
Judgement
My willingness to judge something should be proportional to how much I know about it.
Assessment : the wide variety of methods or tools that educators use to evaluate, measure, and document the academic readiness, learning
progress, skill acquisition, or educational needs of students.
Step 1: Clearly define and identify the learning outcomes.
Step 2: Select appropriate assessment measures and assess the learning outcomes.
Step 3: Analyze the results of the outcomes assessed.
Step 4: Adjust or improve programs following the results of the learning outcomes assessed.
3 types of assessment
Assessment of Learning (Summative Assessment) : A type of summative assessment that aims to reflect students knowledge of a given area through a grade.
Assessment for Learning (Formative Assessment) : A type of formative assessment that aims to provide teachers with the necessary data to adjust the learning process while it is happening.
Assessment as Learning
Assessment Techniques
Assessed Workshop
Podcast
Case Study
Collaborative Wiki/Blog
Essay
Fieldwork
Portfolio (Group/Personal)
Presentation (Group/Personal)
In-class test
Laboratory Practical Assessment
Research Project
Laboratory Notebook
Laboratory Report
Literature Review
Open-Book Exam
Oral Examination
Peer Assessment
Poster
Poster Presentation
Project Proposal
Research Proposal
Self Assessment
Site Investiagtion
Fieldwork
Standar Nasional Pendidikan
Proses Pembelajaran -> Metode Pembelajaran -> Bentuk Pembelajaran
Metode Pembelajaran:
diskusi kelompok
simulasi
studi kasus
pembelajaran kolaboratif
pembelajaran kooperatif
pembelajaran berbasis proyek
pembelajaran berbasis masalah
metode pembelajaran lain
Bentuk pembelajaran: wadah atas satu atau gabungan dari beberapa metode pembelajaran.
Bentuk pembelajaran dapat dilakukan di dalam Program Studi dan di luar Program Studi.
penelitian, perancangan, atau pengembangan; (ket: wajib untuk D-4, S-1, S-2, S-3, profesi, spesialis)
pelatihan militer;
pertukaran pelajar;
magang;
wirausaha
bentuk lain pengabdian kepada masyarakat. (ket: wajib untuk D-4, S-1, profesi, spesialis)
Penilaian: penilaian proses dan hasil belajar
Teknik Penilaian
observasi,
partisipasi,
unjuk kerja,
tes tertulis,
tes lisan,
angket.
Instrumen Penilaian
penilaian proses dalam bentuk rubrik dan/atau
penilaian hasil dalam bentuk portofolio atau karya desain.
Struktur
Bentuk pembelajaran memuat metode pembelajaran.
Proses dan hasil pembelajaran berdasarkan metode pembelajaran dievaluasi dengan penilaian.
Penilaian terdiri dari (di antaranya) teknik penilaian dan instrumen penilaian.
Suatu metode pembelajaran prosesnya bisa dinilai dengan berbagai teknik penilaian dengan instrumen penilaian dalam bentuk rubrik.
Suatu metode pembelajaran hasilnya bisa dinilai dengan berbagai teknik penilaian dengan instrumen penilaian dalam portofolio atau karya desain.
Ranah Penilaian:
Sikap / Afektif
Pengetahuan / Kognitif
Keterampilan / Psikomotorik
Penilaian :
Penilaian atas pembelajaran (assessment of learning)
Summative assessment : mengukur capaian belajar untuk membandingkannya terhadap acuan/standar
Penilaian untuk pembelajaran (assessment for learning)
Diagnostic assessment : mengetahui kondisi belajar siswa untuk meningkatkan kualitas pembelajaran
Penilaian sebagai pembelajaran (assessment as learning)
Formative assessment : mengukur capaian belajar untuk meningkatkan kualitas pembelajaran
HOTS (higher order thinking skills):
Kemampuan berpikir kritis, logis, reflektif, metakognitif, kreatif
Ranah HOTS:
analisis
evaluasi
kreasi
Aspek Kompetensi
Teknik atau Metode
Instrumen (Proses dan Hasil)
Sikap
Observasi
Rubrik Observasi
Partisipasi
Rubrik Partisipasi
Penilaian Diri
Rubrik Penilaian Diri
Penilaian Sejawat
Rubrik Penilaian Sejawat
Jurnal
Rubrik Penilaian Jurnal
Log Book
Rubrik Penilaian Log Book
Pengetahuan
Tes Tulis
Soal Tes Isian
Tes Tulis
Soal Tes Pilihan
Tes Lisan
Soal Tes Lisan
Tes Lisan
Rubrik Presentasi Lisan
Tugas
Lembar Penugasan
Tugas
Rubrik Penilaian Tugas
Observasi
Rubrik Observasi
Keterampilan
Tes Praktik
Rubrik Penilaian Praktik
Proyek
Rubrik Penilaian Proyek
Portofolio
Rubrik Penilaian Portofolio
Observasi
Rubrik Observasi
Unjuk Kerja
Rubrik Unjuk Kerja
Produk
Lembar Penugasan
Tulisan
Lembar Penugasan
Rubrik
Rubrik merupakan panduan penilaian yang menggambarkan kriteria yang diinginkan dalam menilai atau memberi tingkatan dari hasil kinerja belajar mahasiswa.
Rubrik terdiri dari dimensi yang dinilai dan kriteria kemampuan hasil belajar mahasiswa ataupun indikator capaian belajar mahasiswa.
Rubrik holistik adalah pedoman untuk menilai
berdasarkan kesan keseluruhan atau kombinasi semua kriteria. (Tidak ada rincian aspek/dimensi, tapi ada deskripsi secara kesan keseluruhan)
Rubrik deskriptif memiliki tingkatan kriteria penilaian yang dideskripsikan dan diberikan skala penilaian atau skor penilaian. (Ada rincian aspek/dimensi, ada bantuan deskripsi dalam kriteria penilaian)
Rubrik skala persepsi memiliki tingkatan kriteria penilian yang tidak dideskripsikan namun tetap diberikan skala penilaian atau skor penilaian. (Ada rincian aspek/dimensi, tapi tidak deskripsi dalam kriteria penilaian)
Portofolio
Penilaian portofolio merupakan penilaian
berkelanjutan yang didasarkan pada kumpulan
informasi yang menunjukkan perkembangan capaian belajar mahasiswa dalam satu periode tertentu.
Portofolio perkembangan. Beberapa portofolio, dinilai berdasarkan kemajuan pencapaian. Contoh: draft, laporan sementara, laporan akhir
Portofolio pamer/showcase. Beberapa portofolio, dinilai berdasarkan satu portofolio terbaik.
Portofolio komprehensif. Beberapa portofolio, dinilai secara kumulatif.
Op Amp is a Voltage Gain Device. Op amps have high input impedance and low output impedance because of the concept of a voltage divider, which is how voltage is divided in a circuit depending on the amount of impedance present in given parts of a circuit. Op amps are voltage gain devices. They amplify a voltage fed into the op amp and give out the same signal as output with a much larger gain. In order for an op amp to receive the voltage signal as its input, the voltage signal must be dropped across the op amp.
For the same reason of a voltage divider, an op amp needs a low output impedance. Once the voltage is dropped across the op amp and it does its task of amplifying the signal, the signal should get dropped across the device that the op amp should feed.
To Prevent Loading. Another reason op amps need high input impedance is because the loading effect. If op amps had very low input impedance, it would draw significant amounts of current into it. Thus, it would be a large load on the circuit. The fact that an op amp has a high input impedance ensures that it consumes very little current from the circuit and doesn’t cause a loading issue in the circuit in which it demands and sucks up large amounts of current of the circuit.
Active learning is “a method of learning in which students are actively or experientially involved in the learning process and where there are different levels of active learning, depending on student involvement.”
Students participate [in active learning] when they are doing something besides passively listening.
Students must do more than just listen in order to learn. They must read, write, discuss, and be engaged in solving problems. This process relates to the three learning domains referred to as knowledge, skills and attitudes (KSA).
Examples of “active learning” activities
class discussion
think-pair-share (small group discussion - class share)
learning cell : alternate asking and answering questions on commonly read materials
short written exercise
collaborative learning group
student debate
small group discussion
Just-in-time teaching (pre-class questions)
class game
Learning by teaching
Inquiry-based learning
a form of active learning that starts by posing questions, problems or scenarios
Inquiry-based learning is often assisted by a facilitator rather than a lecturer. Inquirers will identify and research issues and questions to develop knowledge or solutions.
Inquiry learning involves developing questions, making observations, doing research to find out what information is already recorded, developing methods for experiments, developing instruments for data collection, collecting, analyzing, and interpreting data, outlining possible explanations and creating predictions for future study.
Teacher is facilitator in IBL environment
Place needs of students and their ideas at the center
Don’t wait for the perfect question, pose multiple open-ended questions.
Work towards common goal of understanding
Remain faithful to the students’ line of inquiry
Teach directly on a need-to-know basis
Encourage students to demonstrate learning using a range of media
Generic Levels
Level 1: Confirmation Inquiry. The teacher has taught a particular science theme or topic. The teacher then develops questions and a procedure that guides students through an activity where the results are already known. This method is great to reinforce concepts taught and to introduce students into learning to follow procedures, collect and record data correctly and to confirm and deepen understandings.
Level 2: Structured Inquiry. The teacher provides the initial question and an outline of the procedure. Students are to formulate explanations of their findings through evaluating and analyzing the data that they collect.
Level 3: Guided Inquiry. The teacher provides only the research question for the students. The students are responsible for designing and following their own procedures to test that question and then communicate their results and findings.
Level 4: Open/True Inquiry. Students formulate their own research question(s), design and follow through with a developed procedure, and communicate their findings and results. This type of inquiry is often seen in science fair contexts where students drive their own investigative questions. »> This is Problem Based Learning
Levels in Science Education
Students are provided with questions, methods and materials and are challenged to discover relationships between variables
Students are provided with a question, however, the method for research is up to the students to develop
Phenomena are proposed but students must develop their own questions and method for research to discover relationships among variables
Important Aspects
Students should be able to recognize that science is more than memorizing and knowing facts.
Students should have the opportunity to develop new knowledge that builds on their prior knowledge and scientific ideas.
Students will develop new knowledge by restructuring their previous understandings of scientific concepts and adding new information learned.
Learning is influenced by students’ social environment whereby they have an opportunity to learn from each other.
Students will take control of their learning.
The extent to which students are able to learn with deep understanding will influence how transferable their new knowledge is to real life contexts.
Example of Formats
Field-work
Case studies
Investigations
Individual and group projects
Research projects
Problem-based learning (PBL)
Problem-based learning (PBL) is a student-centered pedagogy in which students learn about a subject through the experience of solving an open-ended problem found in trigger material.
The PBL process does not focus on problem solving with a defined solution, but it allows for the development of other desirable skills and attributes. This includes knowledge acquisition, enhanced group collaboration and communication.
The PBL tutorial process involves working in small groups of learners. Each student takes on a role within the group that may be formal or informal and the role often alternates.
It is focused on the student’s reflection and reasoning to construct their own learning.
The Maastricht seven-jump process involves clarifying terms, defining problem(s), brainstorming, structuring and hypothesis, learning objectives, independent study and synthesis.
Principles
Learner-driven self-identified goals and outcomes
Students do independent, self-directed study before returning to larger group
Learning is done in small groups of 8–10 people, with a tutor to facilitate discussion
Trigger materials such as paper-based clinical scenarios, lab data, photographs, articles or videos or patients (real or simulated) can be used
The Maastricht 7-jump process helps to guide the PBL tutorial process
Based on principles of adult learning theory
All members of the group have a role to play
Allows for knowledge acquisition through combined work and intellect
Enhances teamwork and communication, problem-solving and encourages independent responsibility for shared learning - all essential skills for future practice
Anyone can do it as long it is right depending on the given causes and scenario
Computer-supported PBL
Computer-supported PBL can be an electronic version (ePBL) of the traditional face-to-face paper-based PBL or an online group activity with participants located distant apart.
ePBL provides the opportunity to embed audios and videos, related to the skills (e.g. clinical findings) within the case scenarios improving learning environment and thus enhance students’ engagement in the learning process.
The most successful feature of the LMS in terms of user rate was the discussion boards where asynchronous communications took place.
Tools
Collaborative tools: The first, and possibly most crucial phase in PBL, is to identify the problem. Before learners can begin to solve a problem, all members must understand and agree on the details of the problem. This consensus forms through collaboration and discussion. Example: Discussion Board, Moodle, Discord
Research tools. Once the problem has been identified, learners move into the second step of PBL: the information gathering phase. In this phase, learners research the problem by gathering background information and researching potential solutions. This information is shared with the learning team and used to generate potential solutions, each with supporting evidence. Example: Google, Wikipedia.
Presentation tools. The third most important phase of PBL is resolving the problem, the critical task is presenting and defending your solution to the given problem. Students need to be able to state the problem clearly, describe the process of problem-solving considering different options to overcome difficulties, support the solution using relevant information and data analysis. Being able to communicate and present the solution clearly is the key to the success of this phase as it directly affects the learning outcomes. Example: Google Presentation, Youtube
Learning
Case-based Learning
With case-based teaching, students develop skills in analytical thinking and reflective judgment by reading and discussing complex, real-life scenarios.
Case studies are stories that are used as a teaching tool to show the application of a theory or concept to real situations. Dependent on the goal they are meant to fulfill, cases can be fact-driven and deductive where there is a correct answer, or they can be context driven where multiple solutions are possible.
Case-based learning (CBL) is an established approach used across disciplines where students apply their knowledge to real-world scenarios, promoting higher levels of cognition. In CBL classrooms, students typically work in groups on case studies, stories involving one or more characters and/or scenarios. The cases present a disciplinary problem or problems for which students devise solutions under the guidance of the instructor.
PBL consists of carefully designed problems that challenge students to use problem solving techniques, self-directed learning strategies, team participation skills, and disciplinary knowledge.
CBL vs PBL
PBL involves open rather than guided inquiry, is less structured, and the instructor plays a more passive role. In PBL multiple solutions to the problem may exit, but the problem is often initially not well-defined. PBL also has a stronger emphasis on developing self-directed learning.
Mirrorless : Sony Alpha A5000/A6000, Canon EOS M10, Fujifilm X-A10, Panasonic Lumix DMC-GX85, Olympus E-PL7, Nikon 1 J5, Xiaomi Yi M1, Samsung NX1000, Canon PowerShot G7 X Mark II, Canon EOS M3.
Separate writing from editing. Just keep writing, ignore the typos, self-censorship or formatting and keep moving.
Separate writing from editing. In writing, try writing one sentence per line.
Vary the length of the sentences. Don’t just write words. Write music.
Limit each paragraph to a single message. A single sentence can be a paragraph.
Keep sentences short, simply constructed and direct.
This sentence has five words. Here are five more words. Five-word sentences are fine. But several together become monotonous. Listen to what is happening. The writing is getting boring. The sound of it drones. It’s like a stuck record. The ear demands some variety.
Now listen. I vary the sentence length, and I create music. Music. The writing sings. It has a pleasant rhythm, a lilt, a harmony. I use short sentences. And I use sentences of medium length. And sometimes, when I am certain the reader is rested, I will engage him with a sentence of considerable length, a sentence that burns with energy and builds with all the impetus of a crescendo, the roll of the drums, the crash of the cymbals–sounds that say listen to this, it is important.
So I write with a combination of short, medium, and long sentences. Create a sound that pleases the reader’s ear. Don’t just write words. Write music.
(Gary Provost)
The following are more of McCarthy’s words of wisdom, as told by Savage and Yeh.
Use minimalism to achieve clarity. Remove extra words or commas whenever you can.
Decide on your paper’s theme and two or three points you want every reader to remember. The words, sentences, paragraphs and sections are the needlework that holds it together. If something isn’t needed to help the reader to understand the main theme, omit it.
Limit each paragraph to a single message. A single sentence can be a paragraph. Each paragraph should explore that message by first asking a question and then progressing to an idea, and sometimes to an answer. It’s also perfectly fine to raise questions in a paragraph and leave them unanswered.
Keep sentences short, simply constructed and direct. Concise, clear sentences work well for scientific explanations. Minimize clauses, compound sentences and transition words — such as ‘however’ or ‘thus’ — so that the reader can focus on the main message.
Don’t slow the reader down. Avoid footnotes because they break the flow of thoughts and send your eyes darting back and forth while your hands are turning pages or clicking on links.
Try to avoid jargon, buzzwords or overly technical language. And don’t use the same word repeatedly — it’s boring.
Don’t over-elaborate. Only use an adjective if it’s relevant. Your paper is not a dialogue with the readers’ potential questions, so don’t go overboard anticipating them. Don’t say the same thing in three different ways in any single section. Don’t say both ’elucidate’ and ’elaborate’. Just choose one, or you risk that your readers will give up.
And don’t worry too much about readers who want to find a way to argue about every tangential point and list all possible qualifications for every statement. Just enjoy writing.
With regard to grammar, spoken language and common sense are generally better guides for a first draft than rule books. It’s more important to be understood than it is to form a grammatically perfect sentence.
Commas denote a pause in speaking. The phrase ‘In contrast’ at the start of a sentence needs a comma to emphasize that the sentence is distinguished from the previous one, not to distinguish the first two words of the sentence from the rest of the sentence. Speak the sentence aloud to find pauses.
Dashes should emphasize the clauses you consider most important — without using bold or italics — and not only for defining terms. (Parentheses can present clauses more quietly and gently than commas.)
Don’t lean on semicolons as a crutch to join loosely linked ideas. This only encourages bad writing. You can occasionally use contractions such as isn’t, don’t, it’s and shouldn’t. Don’t be overly formal. And don’t use exclamation marks to call attention to the significance of a point. You could say ‘surprisingly’ or ‘intriguingly’ instead, but don’t overdo it. Use these words only once or twice per paper.
Inject questions and less-formal language to break up tone and maintain a friendly feeling. Colloquial expressions can be good for this, but they shouldn’t be too narrowly tied to a region. Similarly, use a personal tone because it can help to engage a reader. Impersonal, passive text doesn’t fool anyone into thinking you’re being objective: “Earth is the centre of this Solar System” isn’t any more objective or factual than “We are at the centre of our Solar System.”
Choose concrete language and examples. If you must talk about arbitrary colours of an abstract sphere, it’s more gripping to speak of this sphere as a red balloon or a blue billiard ball.
Avoid placing equations in the middle of sentences. Mathematics is not the same as English, and we shouldn’t pretend it is. To separate equations from text, you can use line breaks, white space, supplementary sections, intuitive notation and clear explanations of how to translate from assumptions to equations and back to results.
When you think you’re done, read your work aloud to yourself or a friend. Find a good editor you can trust and who will spend real time and thought on your work. Try to make life as easy as possible for your editing friends. Number pages and double space.
After all this, send your work to the journal editors. Try not to think about the paper until the reviewers and editors come back with their own perspectives. When this happens, it’s often useful to heed Rudyard Kipling’s advice: “Trust yourself when all men doubt you, but make allowance for their doubting too.” Change text where useful, and where not, politely explain why you’re keeping your original formulation.
And don’t rant to editors about the Oxford comma, the correct usage of ‘significantly’ or the choice of ‘that’ versus ‘which’. Journals set their own rules for style and sections. You won’t get exceptions.
Finally, try to write the best version of your paper: the one that you like. You can’t please an anonymous reader, but you should be able to please yourself. Your paper — you hope — is for posterity. Remember how you first read the papers that inspired you while you enjoy the process of writing your own.
10.26 - Open Directory Search
Open Directory Search
Open Directories are unprotected directories of pics, videos, music, software and otherwise interesting files.
There are other software programs that provide wget with a GUI like Gwget and WinWGet though I’ve never used them and hence can’t comment on their reliability.
youtube-dl (Python) downloads videos from various sites. Just like wget you can find GUI frontend for this.
RipMe (Java) is an album ripper for various websites.
HTTrack Website Copier (Windows/Linux/OSX/Android) can mirror entire websites.
Other download helpers you should try :
Rclone (Win/Linux/OSX) Command line tool. Rclone has some great commands that can list files, print remote directory size or even mount it as mountpoint. Here is a list of all commands. I recommend you to go through their entire website.
You can also use httpdirfs, which is made by a redditor who posted it here to mount the remote directory as mountpoint. It even appears to be somewhat faster than “rclone mount”.
Zettelkasten-like approaches are useful when you’re trying to synthesize knowledge into a framework/perspective, sometimes as a way to find and contextualize new ideas. If one doesn’t care about that, and ones notes already have a well-defined taxonomy/structure then the linking feature of Zettelkasten is not particularly useful.
What works very well is to use Zettelkasten as the next step after taking notes from reading book, blog posts, and articles to collect your personal insights. Probably also from movies, podcasts, whatever.
I believe Zettelkasten will help me with writing for my own blog and when I’m collecting information for personal projects. In both cases, I have lots of ideas which are not fully formed yet to be published or implemented. With a job and a family there is little time to pursue it, so I have to work in little steps. Externalizing this ideas is essential and a very-hyperlinked style like Zettelkasten seems to fit well.
For learning little facts about programming languages, spaced repetition is probably more suitable.
Going down a wikipedia-style rabbit hole of my own notes is cool, like I’m exploring my own brain. Sometimes I completely forget how something works, and when I look up the note I took I just have to read a few of my own words to immediately remember it all.
I will say though that progress actually feels pretty slow compared to my usual strategy of just reading through books and articles once or twice, and then web searching whenever I forget something.
As far as I can tell, both in studies and in personal experience, the fiddly details of your note-taking schemes don’t matter. The only thing that matters is attempting to integrate the information into a cohesive whole, which takes intentional thought.
With linear notes, there’s a failure mode where links that should be made aren’t; you can even walk around believing outright contradictions without noticing. But with a web, there’s an equally bad failure mode where your knowledge gets diffuse and unstructured (instead of “X causes Y if Z”, you get “X, Y, and Z are related. But… was Z the thing that caused X? Wait, but then what was Y for?”).
Both of these reflect a failure to aggregate and chunk the information into hard tools, but no productivity system can magically fix that; it always takes time.
This looks interesting, but one potential problem with this method is that you start treating the number of notes or the size of the graph as a success metric. The author even notes how it is ‘pleasing’ to see their note graph grow in size. This could be a perverse incentive.
I think your proposed system captures the important part of the knowledge intake, ie two levels of abstraction (writing a source note, and then connecting the new knowledge from source note to (or just dumping it in) some existing node.)
But one other idea from Christian and Sascha is to avoid folder structures, and allow the organization to develop over time. On a work topic, notes from a few guidances and presentations, plus my experiences, cluster to create a note which transcends a categorical boundary I would have erected with a folder structure.
So, the suggested alt strategy is dump everything into one folder and create clusters using other structures, as they reveal themselves to be useful.
Creating a hierarchy of notes using folders can be counterproductive. It will be easy to classify the majority of notes, but some of them will match multiple categories, or even none of them. Unfortunately, those notes are usually the most interesting. Case in point: I have some notes regarding good technical writing, and some notes concerning good Git usage. If I had a hierarchy, the first notes would go under “writing”, and the second ones would go under “development”. But where would I have filed the notes regarding Git commit messages? I feel like they belong on both categories. Choosing just one of them means ignoring the other. That’s why, if you still want to classify some of your tags, I strongly advise to use a tagging system, and to avoid creating note hierarchies.
It can be way more simple: I use one folder for my notes, and another one for my “sources” (linear notes on articles, books, talks, etc). Files have unique filenames (guaranteed because a timestamp is added to the name when they are created).
In the book “How to take smart notes” by Sönke Ahrens, there’s a lot of thought given on the real value of tags. I’d say the problem you describe happens because you are trying to create a taxonomy using tags. Classifying the notes using tags can feel rewarding in the short term, but it’s not useful in the context of a linked notes system.
When creating tasks, the main question that is answered is “in which contexts would I like this note to show up?”. The answer to this question is completely subjective. If, for instance, you were doing research for game level design, it makes sense for the systems architecture notes to be tagged with “game engine”, “achievements”, “quick save”, or anything else that you will want to look up later on. The Napoleonic architecture notes could be tagged as “level design”, “gameplay cues”, or “side quests”.
As you can see, these tags would be different for every person, and that’s kind of the point. Two people can read the same content, and take the same note from it, but the intended purpose could still be completely different, and that would show up in the tags.
I don’t think one should suggest Zettelkasten to anyone who is looking for a simple to-do list or note taking implementation. Regular notes are perfectly fine if one wants to take regular notes.
Luhman’s zettels weren’t random thoughts or casual ideas that popped into his head during a stroll with the dog., but rather full, jargon-laden sentences that were close to publication-ready in quality, sometimes highly abstract in nature. He would take a couple dozen related zettels, arrange them on a table in sequence, rearrange them and eventually have a rough outline for an article or the chapter of a book.
Here’s a random zettel from Luhmann’s archive, translated by deepl.com. This is 1 out of 90,000 total:
1.6c1 “About an activity, at one time, central and centralization.” – In some ways comparable to the view of Mary Parker Follett, Dynamic Administration, p. 183ff., e.g. p. 195: “Unity is always a process, not a product.” – But she confuses unity and unifying, and says below quite correctly (p. 195): “Business unifying must be understood as a process, not as a product.” – Except, of course, that the word unity does not mean process, this dynamic view is that the process can be described as valuable and characterizes the organizational view, from the finished fake unit to the unification unit process.
The only note taking approach that’s ever worked for me:
Read/listen/absorb
Write down ideas it creates while you’re absorbing
Wait
Create
Your mind (or at least mine) finds connections you aren’t even aware of and when the time comes, when the right prompt sparks, there it is. The knowledge is ready to be used.
Zettelkasten is exactly what you wrote here, with one addition. It not only offloads querying for detail (i.e. search) to the machine, it also offloads some connection-making. Search and lookup is internet-as-extended-memory, links and backlinks are internet-as-serendipitous-thought.
The part about “just write it down” is the most important. Connecting information as you go can add value to the knowledge base, but writing down everything that’s important is the first step and the tool you use should support that. I think the book keeping part is more of a personal thing and some people feel that they need to do it and others do not. I for myself “separate” notes into problem domains (when I think about them I have a broader topic in mind) and connect all the notes that belong to the same topic when I see fit. That greatly reduces the book keeping part and I can add connections as I go.
I would say if your workflow is not research-centric where you only implement software, these kinds of methods are not necessary. Only simple note-taking would suffice to ease your brain.
On the contrary, if you are reading papers and doing research, taking notes in a meaningful way is more helpful than you would realize. The human brain tends to skip information while reading and you only realize you didn’t actually understand that part when you try to write it yourself. The note-taking part doesn’t actually take that much brain resources. I am not a native English speaker but I am taking my notes in English. While taking my notes I don’t care about grammar or anything, I just read and write what I understood. When I finish the paper and I am comfortable with the topic, I return to my notes, fix grammars and, link them with my other notes. For example, sometimes I come up with a research idea, I make a note about it. In the future, while reading a paper, I realize some of the techniques that are described in the paper might be beneficial to that idea so I link them together.
In conclusion, it really depends on your area of work whether to take regular notes or Zettelkasten notes. Forcing your workflow to these methods might hurt your productivity but if you are a researcher I can say, it will be beneficial.
Normal notes are fighting complexity by creating smaller and smaller categories of notes
Example: splitting “engineering notes” to “software notes” and “technical writing notes”, and then “software notes” to “java notes” and “design notes”. And this way the notes get deeper and deeper in your notebook and you stop interacting with them. This described well my personal experience. Zettelkasten fights this complexity by much more up-front work when adding and linking note, instead of a tree structure, you have a network.
Most of the time, it’s more be beneficial to file notes according to the situation in which they’ll be useful rather than where they came from: If you’re going to have a tree structure, the original sources should be out at the leaves as external references rather than the root. This manifests in many forms from lots of different people giving advice:
In Getting Things Done, Allen spends a lot of time on the importance of organizing your todo lists by where you’ll be able to do the actions.
Luhmann used his original Zettelkasten to store passages that he could pull to make drafts of papers, and cross-referenced them to other passages that could be included together.
In How to Write a Thesis, Eco recommends writing a preliminary outline of your thesis and then tagging notes with the section number they’re relevant to.
In his MasterClass series, Chris Hadfield emphasizes the benefit of collecting summary notes organized by the interface you’ll see when actually performing an activity.
It depends on the goal. Your goal is to learn things, apparently. Memorize what you wrote on the notes. Zettelkasten’s isn’t. Its goal is to produce great books and papers.
As far as I can tell, the crosslinking required by the Zettelkasten approach provides two main benefits:
It forces some retrieval practice of the notes you’ve taken before, which reinforces all the ideas involved.
Most of the benefit comes from the act of writing, but there’s an inevitable sense of futility that comes about if those writings are inevitably lost to time. By giving each note an ongoing purpose (to be linked to), the Zettelkasten system dodges this particular trigger to stop writing notes.
Zettelkasten has its benefits: If you want to be able to casually browse through your notes, looking for ideas to spark your imagination, Zettelkasten will most likely have superior results since the ideas are already summarized right there for you. Zettelkasten makes it easy to compose essays and put together speeches, but that’s because you’ve already done the hard work of writing down your thoughts ahead of time.
It’s requirement to link all notes ahead of time is a HUGE barrier to entry, so Zettlekasten may be best suited to people with a strong research oriented disposition who’re already used to similar practices.
Why not jut search?
I think this trend of better knowledge tools is missing two very important pieces of human nature
If we have time to enter something into a knowledge base of any kind - then we have time to just jot it on a piece of paper.
If we dont have time (or think it is important at that moment) then what solves the problem for us is not a knowledge base, but search.
There are problems with search: you have to know to search for something, and you have to know how to search for it. In some cases this is an issue, in some it isn’t. I have had many times over the years where I reviewed my notes and reminded myself of things I had completely forgotten. Search is useless in that case. But in any event, there’s no conflict between a knowledge base and search. They are different things and you can search a knowledge base.
[Zettl practice] I can stream thoughts into a lightweight inbox without having to do the organizing upfront. I then have derived categories from the main stream of thoughts. If the thought is a task, I further process these into categories. I have recurring tasks and events that I handle on a “Time” page that is effectively a calendar, and I have one-off tasks that go into a Kanban style backlog. What I really got from Zettlekasten is that trying to establish your system upfront is a mistake. Things inevitably leak through your categories and then you lose faith in your system. By just having a running stream of thoughts and then relating them after the fact and deriving categories afterward, you get the benefits of organization without a lot of its failure modes.
Your template misses backlinks. Zk notes have five elements:
Backlinks (in the form of [[backlink]] in most zk software tools such as zettlr/obsidian/thearchive etc;)
Source or reference (checked)
Content (I suppose it is your # Notes)
Also all zettels are atomic, so you will deilberately limit yourself to one topic idea, ideally with a question or something (I suppose that is why you have # Title).
Here’s my rather brief summary of the process:
You create fleeting notes to capture ideas as they happen. They should be short lived notes that don’t become the main store of your knowledge.
You create literature notes as your read material. These should include your own thoughts on highlighted passages, not just quotes and highlights on their own.
You organise your fleeting notes as permanent notes into your ‘Slip Box’ (taken from the original use index cards). Each note should contain a single idea and should be understandable when reading in isolation.
You want to avoid burying knowledge in large notes as it makes it hard to glance at and link to other notes in a concise way.
Notes are linked to other notes which support your ideas. This also help the discovery of new ideas.
You use your slip box to help you do your thinking. You want to ask it questions, find the related notes that support/oppose the arguments and find gaps or newly related information.
You can create index notes that help you find your way around.
Part of the process is to help your understanding by writing. With a well maintained slip box, you’ll never be starting from a blank sheet. You decide what insight/question/knowledge you want to explore, and pull together the notes that give you the body of research to get you started. You shouldn’t need to start a new blog post by researching, that happens prior by taking smart notes as you naturally read what you’re interested in.
With P.A.R.A. you organize all your notes by purpose, not by category. Let’s say you’re trying to build an app. You’ll have a folder called ‘app’ for all notes about it. Now if you study databases in order to build it, you’ll file any notes you take inside the ‘app’ folder, not in a separate ‘databases’ folder.
Instead of forcing myself to be disciplined about organizing my notes, P.A.R.A. + Progressive Summarization takes advantage of the times when I’m already excited to work on them. Each time I touch the notes, I have to take a small amount of effort which is proportionate to my level of interest in the task. We’ve replaced forced discipline with leveraged excitement.
P.A.R.A. is great for those who don’t have the time (or willpower) to force themselves to write down notes they may never use. Instead it’s Just-in-Time philosophy saves many hours and lets you be more productive. Tiago has designed P.A.R.A. to work with most productivity apps, but the process is optimized for his app of choice: Evernote.
All in all, I’m finding P.A.R.A. pretty useful so far. It has yet to pass the ultimate test of any knowledge management system: Will I still be using it three months from now? (ask me after July). I’m already noticing productivity boosts by using the PARA method to store notes for all my projects, so prospects are looking good
Unique IDs - facilitates linking - can use beyond your note-taking system if you use it on other files and documents and use a file explorer
Linking - link relevant ideas and information
Atomicity - reuse future-proof notes/ideas in different contexts
Progressive summarization - pare down your notes while keeping the original source - ideas: you could pick out key terms, write a summary at the top, make a TOC of the things you want to navigate to easily
IMF - a way to organize notes without necessarily tying them to a certain category. I think of it as creating different ‘views’ of your notes.
10.29 - About Compiler Interpreter
About Compiler and Interpreter
An interpreter for language X is a program (or a machine, or just some kind of mechanism in general) that executes any program p written in language X such that it performs the effects and evaluates the results as prescribed by the specification of X. CPUs are usually interpreters for their respective instructions sets, although modern high-performance workstation CPUs are actually more complex than that; they may actually have an underlying proprietary private instruction set and either translate (compile) or interpret the externally visible public instruction set.
A compiler from X to Y is a program (or a machine, or just some kind of mechanism in general) that translates any program p from some language X into a semantically equivalent program p′ in some language Y in such a way that the semantics of the program are preserved, i.e. that interpreting p′ with an interpreter for Y will yield the same results and have the same effects as interpreting p with an interpreter for X. (Note that X and Y may be the same language.)
The terms Ahead-of-Time (AOT) and Just-in-Time (JIT) refer to when compilation takes place: the “time” referred to in those terms is “runtime”, i.e. a JIT compiler compiles the program as it is running, an AOT compiler compiles the program before it is running. Note that this requires that a JIT compiler from language X to language Y must somehow work together with an interpreter for language Y, otherwise there wouldn’t be any way to run the program. (So, for example, a JIT compiler which compiles JavaScript to x86 machine code doesn’t make sense without an x86 CPU; it compiles the program while it is running, but without the x86 CPU the program wouldn’t be running.)
Note that this distinction doesn’t make sense for interpreters: an interpreter runs the program. The idea of an AOT interpreter that runs a program before it runs or a JIT interpreter that runs a program while it is running is nonsensical.
So, we have:
AOT compiler: compiles before running
JIT compiler: compiles while running
interpreter: runs
JIT Compilers
Within the family of JIT compilers, there are still many differences as to when exactly they compile, how often, and at what granularity.
The JIT compiler in Microsoft’s CLR for example only compiles code once (when it is loaded) and compiles a whole assembly at a time. Other compilers may gather information while the program is running and recompile code several times as new information becomes available that allows them to better optimize it. Some JIT compilers are even capable of de-optimizing code. Now, you might ask yourself why one would ever want to do that? De-optimizing allows you to perform very aggressive optimizations that might actually be unsafe: if it turns out you were too aggressive you can just back out again, whereas, with a JIT compiler that cannot de-optimize, you couldn’t have run the aggressive optimizations in the first place.
JIT compilers may either compile some static unit of code in one go (one module, one class, one function, one method, …; these are typically called method-at-a-time JIT, for example) or they may trace the dynamic execution of code to find dynamic traces (typically loops) that they will then compile (these are called tracing JITs).
Combining Interpreters and Compilers
Interpreters and compilers may be combined into a single language execution engine. There are two typical scenarios where this is done.
Combining an AOT compiler from X to Y with an interpreter for Y. Here, typically X is some higher-level language optimized for readability by humans, whereas Y is a compact language (often some kind of bytecode) optimized for interpretability by machines. For example, the CPython Python execution engine has an AOT compiler that compiles Python sourcecode to CPython bytecode and an interpreter that interprets CPython bytecode. Likewise, the YARV Ruby execution engine has an AOT compiler that compiles Ruby sourcecode to YARV bytecode and an interpreter that interprets YARV bytecode. Why would you want to do that? Ruby and Python are both very high-level and somewhat complex languages, so we first compile them into a language that is easier to parse and easier to interpret, and then interpret that language.
The other way to combine an interpreter and a compiler is a mixed-mode execution engine. Here, we “mix” two “modes” of implementing the same language together, i.e. an interpreter for X and a JIT compiler from X to Y. (So, the difference here is that in the above case, we had multiple “stages” with the compiler compiling the program and then feeding the result into the interpreter, here we have the two working side-by-side on the same language.) Code that has been compiled by a compiler tends to run faster than code that is executed by an interpreter, but actually compiling the code first takes time (and particularly, if you want to heavily optimize the code to run really fast, it takes a lot of time). So, to bridge this time when the JIT compiler is busy compiling the code, the interpreter can already start running the code, and once the JIT is finished compiling, we can switch execution over to the compiled code. This means that we get both the best possible performance of the compiled code, but we don’t have to wait for the compilation to finish, and our application starts running straight away (although not as fast as could be).
This is actually just the simplest possible application of a mixed-mode execution engine. More interesting possibilities are, for example, to not start compiling right away, but let the interpreter run for a bit, and collect statistics, profiling information, type information, information about the likelihood of which specific conditional branches are taken, which methods are called most often etc. and then feed this dynamic information to the compiler so that it can generate more optimized code. This is also a way to implement the de-optimization I talked about above: if it turns out that you were too aggressive in optimizing, you can throw away (a part of) the code and revert to interpreting. The HotSpot JVM does this, for example. It contains both an interpreter for JVM bytecode as well as a compiler for JVM bytecode. (In fact, it actually contains two compilers!)
It is also possible and in fact common to combine those two approaches: two phases with the first being an AOT compiler that compiles X to Y and the second phase being a mixed-mode engine that both interprets Y and compiles Y to Z. The Rubinius Ruby execution engine works this way, for example: it has an AOT compiler that compiles Ruby sourcecode to Rubinius bytecode and a mixed-mode engine that first interprets Rubinius bytecode and once it has gathered some information compiles the most often called methods into native machine code.
Note that the role that the interpreter plays in the case of a mixed-mode execution engine, namely providing fast startup, and also potentially collecting information and providing fallback capability may alternatively also be played by a second JIT compiler. This is how V8 works, for example. V8 never interprets, it always compiles. The first compiler is a very fast, very slim compiler that starts up very quick. The code it produces isn’t very fast, though. This compiler also injects profiling code into the code it generates. The other compiler is slower and uses more memory, but produces much faster code, and it can use the profiling information collected by running the code compiled by the first compiler.
This folder contains my random notes for everything I found and thought. They will be messed notes since my approach is just write. So they are just like semi-zettelkasten or even just bookmark handlers. Sometimes I will write in English, in the other times it will in Indonesian.
The notes in the blog work as a starting point to more deep and through notes in another folder. The workflow will be looked like this:
Write everything captured to monthly blog file or to specific related file, if it is available.
Category some interesting things into a respective topic.
Note that these suggestions are off the top of my head and surely biased by my own needs.
bash shell basics
Navigating the shell.
Using one of the common editors, such as vim, emacs, or nano. My personal favorite is vim, but that’s probably because I’ve been using it (or its predecessor, vi) longer than most redditors have been alive.
Listing (ls) and deleting (rm) files.
Changing file permissions (chmod).
Using the find command.
Using basic Linux tools in pipelines, such as tr, wc, basename, dirname, etc.
Using awk/gawk. This tool is so incredibly powerful. I use it almost daily.
Using apt. Note that apt-get is the older package manager, and although it’s largely compatible with apt, there are some differences.
Programming
Learn the basics of bash shell programming, including conditional statements, looping structures, variables, etc.
Definitely learn python, with a focus on python3.
php: see Web Dev below.
Learning C and/or C++ are desirable too, but you don’t need this skill immediately. However, knowing these languages will give you better knowledge for compiling packages and eventually writing your own.
Web servers
You won’t go wrong with apache2, but these days, I’m using nginx more often.
Open-source data multitool | VisiData VisiData is an interactive multitool for tabular data. It combines the clarity of a spreadsheet, the efficiency of the terminal, and the power of Python, into a lightweight utility which can handle millions of rows with ease.
One of the measures that prevent counterfeitting of banknotes.
The currency-detection algorithms implemented by software packages (such as Adobe Photoshop and in Printer/Copier) are sophisticated and multi-level. Obfuscation of the Eurion, distortion, or even removal in some cases, still allows the package to detect that the image is that of currency. This implies other detection techniques are also employed
Uber set the fare which meant that they dictated how much drivers could earn
Uber set the contract terms and drivers had no say in them '
Request for rides is constrained by Uber who can penalise drivers if they reject too many rides
Uber monitors a driver’s service through the star rating and has the capacity to terminate the relationship if after repeated warnings this does not improve
The main difference I see is the imbalance of power. A self-employed can decide who to work with and negotiate almost everything with them. He have my business, the company have theirs, and they discuss to try to reach agreements or not. Uber drivers are not in this position. Uber can dictate everything they want, drivers can only decide to stay or leave.
The issue here is that Uber pretends the driver is contracted by the passenger. In which case the driver should be free to negotiate with the passenger. That Uber exercises control of the relationship is what is indicating that Uber is an employer here. Uber pretends you’re working for the customer, not them. That is a key element in their attempt to pretend they’re not an employer.
Uber acts as an intermediary party between the contractor and the client (the passenger), so you should compare it to platforms for contract work, such as Upwork, or fiverr, or something like that. The point of Uber is that they’re only an intermediate party that puts clients and drivers together. Drivers are not providing a service to Uber. They don’t control your rates, they don’t stop you from getting jobs if you reject a lot, they don’t set any quality minimums for your job, and they don’t remove you if someone doesn’t give you five stars. In other words, you’re not working for these platforms, it’s just a marketplace. With Uber, drivers are working for Uber, not for the passengers. However, Uber is pretending to be a marketplace, and it isn’t. This sentence just proves that.
Ensembling is the use of several independently trained models to form an overall prediction. The basic idea of ensembling is that individual models have weaknesses in different areas, which are compensated by the combination with predictions of other independently trained models. Possible ensembling strategies are e.g. majority voting, the use of a weighted average based on classifier confidences, or simply using the arithmetic mean of several predictions of different models and model architectures
Deskreen Deskreen is a free desktop app that makes any device with a web browser a second screen over WiFi. Deskreen can be used for mirror entire display to any device that has a web browser.
Model-Based Machine Learning – Chapters of this book become available as they are being written. It introduces machine learning via case studies instead of just focusing on the algorithms.
Foundations of Data Science – This is a much more academic-focused book which could be used at the undergraduate or graduate level. It covers many of the topics one would expect: machine learning, streaming, clustering and more.
Hal Daumé III, Assistant Professor of Computer Science at the University of Maryland, has placed the contents of his book online. The book is titled A Course in Machine Learning.
FoldnFly: A database of paper airplanes with easy to follow folding instructions, video tutorials and printable folding plans. Find the best paper airplanes that fly the furthest and stay aloft the longest.
Sharp AI DeepCamera: SharpAI is an open-source stack for machine learning engineering with private deployment and AutoML for edge computing. DeepCamera is an application of SharpAI designed for connecting computer vision models to the surveillance camera.
https://www.appgyver.com/ - The world’s first professional no-code platform, enabling you to build apps for all form factors, including mobile, desktop, browser, TV and others.
Ngrok is an alternative to port forwarding, expose your local to public
Canary Tokens
Suppose you have a situation like this. You want to be warned if someone access your file, your folder, your email, your image, etc.
So you put a token, transparent in your file/folder/email/image, which will warn you if someone open it. That is how Canary Tokens work
reinforcement learning algorithms This repository contains most of pytorch implementation based classic deep reinforcement learning algorithms, including - DQN, DDQN, Dueling Network, DDPG, SAC, A2C, PPO, TRPO.
The dataset was web-scraped for an original 20k samples, then a custom MRCNN model was trained for image segmentation and cropping before being fed into the 128 DCGAN, trained on local hardware, 1660
Hyperchroma A music player that creates real-time music videos (hyperchroma.app)
Colorization
Pix2pix vs CycleGAN
Cycle-GAN can work in an ‘unpaired’ manner and various architectural differences. Unpaired image translation is much harder, as you demand the model to learn objects of different shapes, size, angle, texture, location in different scenes and settings on top of the actual task (coloring in this case). Requires more data and you don’t have fine control on the learning. Formulating the coloring problem as a paired task makes more sense as you simply decrease the complexity of the problem without increasing data collection/annotation work.
The whole point about using CycleGAN is that it can learn in unpaired situations. And it works well in the context of style transfer tasks where the changes are really bold and less nuanced. But, in the context of image colorization, the changes are really subtle and also there are way more options to choose colors than changing a horse to zebra. The other thing is that learning to change a colored image to black and white is much easier for the model than learning to colorize it which can lead to a bad learning procedure.
The most prominent differences is that CycleGAN helps when you have unpaired images and you want to go from one class to the other (Horse to Zebra for example) but in the Pix2Pix paper, the images that you get after the inference, are the input images but with some new features (black&white to colorized or day time to night time of a scene). In pix2pix, a conditional GAN (one generator and one discriminator) is used with some supervision from L1 loss. In CycleGAN, you need two generators and two discriminators to do the task: one pair for going from class A to B and one pair for going from class B to A. Also you need Cycle Consistency Loss to make sure that the models learn to undo the changes they make.
Inciteful : Inciteful builds a network of academic papers based on a topic of your choice and then analyzes the network to help you find the most relevant literature.
Machine Learning: The High Interest Credit Card of Technical Debt – Google Research
So little of success in ML comes from the sexy algorithms and so much just comes from ensuring a bunch of boring details get properly saved in the right place.
After months learning about machine learning for time series forecasting, several chapters in a book on deep learning techniques for time series analysis and forecasting, the author kindly pointed out that there are no papers published up to that point that prove deep learning (neural networks) can perform better than classical statistics.
Career lesson: Ask a lot of questions early in a project’s life. If you’re working on something that uses machine learning, ask what system it’s replacing, and make sure that someone (or you) runs it manually before spending the time to automate.
Turning TPU into GPU (mean: it compiles Pytorch to work on a TPU). PyTorchXLA converts the TPUv3-8 hardware into a GPU so you can use it with PyTorch as a normal GPU. TPUv3-8 which is part of free access from Google Colab can give a computation power that is equivalent to 8 V100 Tesla GPU and possibly 6 3090RTX GPU. info is here. TPUs are ~5x as expensive as GPUs ($1.46/hr for a Nvidia Tesla P100 GPU vs $8.00/hr for a Google TPU v3 vs $4.50/hr for the TPUv2 with “on-demand” access on GCP).
We recommend CPUs for their versatility and for their large memory capacity. GPUs are a great alternative to CPUs when you want to speed up a variety of data science workflows, and TPUs are best when you specifically want to train a machine learning model as fast as you possibly can. In Google Colab, CPU types vary according to variability (Intel Xeon, Intel Skylake, Intel Broadwell, or Intel Haswell CPUs). GPUs were NVIDIA P100 with Intel Xeon 2GHz (2 core) CPU and 13GB RAM. TPUs were TPUv3 (8 core) with Intel Xeon 2GHz (4 core) CPU and 16GB RAM).
Free TPU
TensorFlow Research Cloud - Free TPU : Accelerate your cutting-edge machine learning research with free Cloud TPUs.
EleutherAI EleutherAI is a grassroots AI research group aimed at democratizing and open sourcing AI research.
The Pile : The Pile is a 825 GiB diverse, open source language modelling data set that consists of 22 smaller, high-quality datasets combined together.
pyaf/load_forecasting: Load forcasting on Delhi area electric power load using ARIMA, RNN, LSTM and GRU models Dataset: Electricity, Model: Feed forward Neural Network FFNN, Simple Moving Average SMA, Weighted Moving Average WMA,
Simple Exponential Smoothing SES, Holts Winters HW, Autoregressive Integrated Moving Average ARIMA, Recurrent Neural Networks RNN, Long Short Term Memory cells LSTM, Gated Recurrent Unit cells GRU, Type: Univariate
top open source deep learning for time series forecasting frameworks.
Gluon This framework by Amazon remains one of the top DL based time series forecasting frameworks on GitHub. However, there are some down sides including lock-in to MXNet (a rather obscure architecture). The repository also doesn’t seem to be quick at adding new research.
Flow Forecast This is an upcoming PyTorch based deep learning for time series forecasting framework. The repository features a lot of recent models out of research conferences along with an easy to use deployment API. The repository is one of the few repos to have new models, coverage tests, and interpretability metrics.
sktime dl This is another time series forecasting repository. Unfortunately it looks like particularly recent activity has diminished on it.
PyTorch-TS Another framework, written in PyTorch, this repository focuses more on probabilistic models. The repository isn’t that active (last commit was in November).
Soft-sensors: predictive models for sensor characteristic are called soft sensors
Soft-sensors: software+sensor
Soft-sensor Categories
model-driven
First Principle Models (FPM)
extended Kalman Filter
data-driven
Principle Component Analysis + regression model, Partial Least Squares
Artificial Neural Networks
Neuro-Fuzzy Systems
Support Vector Machines
Soft-sensor Application
on-line prediction
prediction of process variables which can be determined either at low sampling rates
prediction of process variables which can be determined through off-line analysis only
(statistical or soft computing supervised learning approaches)
process monitoring
detection of the state of the process, usually by human
observation and interpretation of the process state (based on univariate statistics) and experience of the operator
process fault detection
detection of the state of the process
FPM
First Principle Models describe the physical and chemical background of the process.
These models are developed primarily for the planning and design of the processing plants, and therefore usually focus on the description of the ideal steady-states of the processes
based on established laws of physics
does not make assumptions such as empirical model and fitting parameters
using experimental data
Data-driven
data-driven models are based on the data measured within the processing plants, and thus describe the real process conditions, they are, compared to the model-driven Soft Sensors, more reality related and describe the true conditions of the process in a better way. Nevertheless
The most commonly applied multivariate analysis tools are principal component analysis (PCA) for fault detection and projection of latent structures (PLS) for the prediction of key quality parameters at end of batch.
First-principle models may be the answer, using experimental data instead of statistical methods to estimate model parameters. They are not as quick and easy to build, but they have many advantages. In terms of simulation, first-principle models provide extrapolation in addition to the interpolation provided by data-driven models. But they also can be used for monitoring, control and optimization.
igel A machine learning tool that allows you to train/fit, test and use models without writing code
sktime A unified toolbox for machine learning with time series
FiftyOne is an open source machine learning tool created by Voxel51 that helps you get closer to your data and ML models. With FiftyOne, you can rapidly experiment with your datasets, enabling you to search, sort, filter, visualize, analyze, and improve your datasets without excess wrangling or writing custom scripts.
Self-Attention (https://arxiv.org/abs/1805.08318). Generator is pre trained UNET with spectral normalization and self-attention. Something that I got from Jason Antic’s DeOldify(https://github.com/jantic/DeOldify), this made a huge difference, all of a sudden I started getting proper details around the facial features.
Progressive Resizing (https://arxiv.org/abs/1710.10196),(https://arxiv.org/pdf/1707.02921.pdf,(https://arxiv.org/pdf/1707.02921.pdf)). Progressive resizing takes this idea of gradually increasing the image size. In this project, the image size was gradually increased and learning rates were adjusted. Thanks to fast.ai for introducing me to Progressive resizing, this helps the model to generalize better as it sees many more different images.
cvdata (MIT) : Tools for creating and manipulating computer vision datasets: resize images, rename files, annotation format conversion, image format conversion, Split dataset into training, validation, and test subsets and much more.
ML-based Image Processor
Hotpot AI ; Design Assistant, starting from image processing, device mockups, to social media posts
Climate indices (BSD-3-Clause) : Python implementations of various climate index algorithms which provide a geographical and temporal picture of the severity of precipitation and temperature anomalies useful for climate monitoring and research.
MIT Climate CoLab : A collaborative online community centered around a series of annual contests that seek out promising ideas for fighting climate change.
Climate Action Challenge : global design competition calling on the creative community to submit bold, innovative solutions to combat the impacts of climate change.
Improving Weather Prediction with CNN: J. A. Weyn, D. R. Durran, and R. Caruana, “Improving data-driven global weather prediction using deep convolutional neural networks on a cubed sphere,”Journal of Advances in Modeling Earth Systems, vol. 12, no. 9, Sep. 2020,ISSN: 1942-2466.doi:10.1029/2020ms002109.[Online]. Available:http://dx.doi.org/10.1029/2020MS002109. Code: https://github.com/jweyn/DLWP-CS
Loss (not in %) can be seen as a distance between the true values of the problem and the values predicted by the model. Greater the loss is, more huge is the errors you made on the data.
Loss is often used in the training process to find the “best” parameter values for your model (e.g. weights in neural network). It is what you try to optimize in the training by updating weights.
Accuracy (in %) can be seen as the number of error you made on the data.
Accuracy is more from an applied perspective. Once you find the optimized parameters above, you use this metrics to evaluate how accurate your model’s prediction is compared to the true data.
That means :
a low accuracy and huge loss means you made huge errors on a lot of data
a low accuracy but low loss means you made little errors on a lot of data
a great accuracy with low loss means you made low errors on a few data (best case)
Prediction
Condition Positive (P) : the number of real positive cases in the data
Condition Negative (N) : the number of real negative cases in the data
True Positive or Hit
True Negative or Correct Rejection
False Positive or False Alarm or Type I error
False Negative or Miss or Type II error
Accuracy
Accuracy (ACC) = (Σ True positive + Σ True negative)/Σ Total population
Accuracy = (TP + TN)/(TP + TN + FP + FN)
Accuracy is sensitive to class imbalance
Precision or Positive Predictive Value (PPV)
Precision measures how accurate is the predictions.
Precision is the percentage of the predictions are correct.
Precision measures the “false positive rate” or the ratio of true object detections to the total number of objects that the classifier predicted.
Precision: how many selected items are relevant.
Precision, a.k.a. positive predicted value, is given as the ratio of true positive (TP) and the total number of predicted positives.
Recall or Sensitivity or True Positive Rate or Probablity of Detection
Recall measures how good the algorithm find all the positives.
Recall measures the “false negative rate” or the ratio of true object detections to the total number of objects in the data set.
Recall: how many relevant items are selected.
Recall : the ratio of TP and total of ground truth positives.
Recall = Σ True positive/Σ Condition positive
F1 Score
Harmonic mean of Precision and Recall
Because it is difficult to compare two models with low precision and high recall or vice versa.
So to make them comparable, F-Score is used.
F1 score = 2 · (Precision · Recall)/(Precision + Recall)
Matthews Correlation Coefficient (MCC) or Phi Coefficient
MCC is used in machine learning as a measure of the quality of binary (two-class) classifications
MCC takes into account all four values in the confusion matrix, and a high value (close to 1) means that both classes are predicted well, even if one class is disproportionately under- (or over-) represented.
Intersection over Union (IoU)
IoU is used for detection algorithm
The IoU is given by the ratio of the area of intersection and area of union of the predicted bounding box and ground truth bounding box.
an IoU of 0 means that there is no overlap between the boxes
an IoU of 1 means that the union of the boxes is the same as their overlap indicating that they are completely overlapping
The IoU would be used to determine if a predicted bounding box (BB) is TP, FP or FN. The TN is not evaluated as each image is assumed to have an object in it.
Traditionally, we define a prediction to be a TP if the IoU is > 0.5, then:
True Positive (if IoU > 0.5)
False Positive (if IoU < 0.5 or Duplicated Bounding Box)
False Negative, when our object detection model missed the target (if there is no detection at all or when the predicted BB has an IoU > 0.5 but has the wrong classification)
mean Average Precision (mAP) score is calculated by taking the mean AP over all classes and/or over all IoU thresholds. Mean average precision (mAP) is used to determine the accuracy of a set of object detections from a model when compared to ground-truth object annotations of a dataset.
Note:
Accuracy is closeness of the measurements to a specific value
More commonly, it is a description of systematic errors, a measure of statistical bias; low accuracy causes a difference between a result and a “true” value. ISO calls this trueness.
the accuracy of a measurement system is the degree of closeness of measurements of a quantity to that quantity’s true value
bias is the amount of inaccuracy
Precision is the closeness of the measurements to each other
Precision is a description of random errors, a measure of statistical variability.
The precision of a measurement system, related to reproducibility and repeatability, is the degree to which repeated measurements under unchanged conditions show the same results.
variability is the amount of imprecision
Accuracy has two definitions:
More commonly, it is a description of systematic errors, a measure of statistical bias; low accuracy causes a difference between a result and a “true” value. ISO calls this trueness.
Alternatively, ISO defines accuracy as describing a combination of both types of observational error above (random and systematic), so high accuracy requires both high precision and high trueness.
LatexDraw : LaTeXDraw is a graphical drawing editor for LaTeX. LaTeXDraw can be used to 1) generate PSTricks code; 2) directly create PDF or PS pictures.
openalpr/openalpr: OpenALPR is an open-source Automatic License Plate Recognition library written in C++ with bindings in C#, Java, Node.js, Go, and Python. The library analyzes images and video streams to identify license plates.
xuexingyu24/License_Plate_Detection_Pytorch: This is a two-stage lightweight and robust license plate recognition in MTCNN and LPRNet using Pytorch. MTCNN is a very well-known real-time detection model primarily designed for human face recognition. It is modified for license plate detection. LPRNet, another real-time end-to-end DNN, is utilized for subsequent recognition.
Facial-Emotion-Detection This work showcases two independent methods for recognizing emotions from faces. The first method using representational autoencoder units, a fairly original idea, to classify an image among one of the seven different emotions. The second method uses a 8-layer convolutional neural network which has an original and unique design, and was developed from scratch.
juan-csv/Face_info: face recognition, and facial attributes detection (age, gender, emotion and race)
weblineindia/AIML-Human-Attributes-Detection-with-Facial-Feature-Extraction This is a Human Attributes Detection program with facial features extraction. It detects facial coordinates using FaceNet model and uses MXNet facial attribute extraction model for extracting 40 types of facial attributes. This solution also detects Emotion, Age and Gender along with facial attributes.
m-elkhou/Facial_Expression_Detection : Automatic Micro-Expression Recognition (AMER) This project was about providing an Android application that can help people take charge of their own emotional health by capturing their micro expressions such as happiness, sadness, anger, disgust, surprise, fear, and neutral. Paper
serengil/deepface : A Lightweight Deep Face Recognition and Facial Attribute Analysis (Age, Gender, Emotion and Race) Framework for Python
for Expressions reader, by Abhilash26 aka Dinodroid: detects 5 high level expressions (happiness, fear, anger, surprise, sadness) from the morph coefficients given by this lib, and display them as smileys. You can try it here: emotion-reader.glitch.me or browse the source code
rohanrao619/Social_Distancing_with_AI : Yolov3 for object detection, Dual Shot Face Detector (DSFD) (better than Haar Cascade) for face detection, ResNet50 for face classification
Face Mask with Face Presentation Attack Detection (in this case: mask with part of face), with lighting and distance effect analysis on detection, working on handheld devices, video based
upgrade rohanrao619/Social_Distancing_with_AI : Yolov3 for object detection, Dual Shot Face Detector (DSFD) (better than Haar Cascade) for face detection, ResNet50 for face classification
upgrade datarootsio/face-mask-detection : RetinaFace (RetinaNetMobileNetV1) for face detection, MobileNetV1 for face classification
Imaging and clinical features of patients with 2019 novel coronavirus SARS-CoV-2, Xi Xu et al.
Chest CT findings in patients with coronavirus disease 2019 (COVID-19): a comprehensive review, Jinkui Li et al.
CT in coronavirus disease 2019 (COVID-19): a systematic review of chest CT findings in 4410 adult patients,
Vineeta Ojha et al.
iCTCF: an integrative resource of chest computed tomography images and clinical features of patients with COVID-19 pneumonia, Wanshan Ning et al. Project Site, Europe PMC Open AccessResearch Square
Computed Tomography (CT) Imaging Features of Patients with COVID-19: Systematic Review and Meta-Analysis, Ephrem Awulachew et al. NCBI Open Access
Open resource of clinical data from patients with pneumonia for the prediction of COVID-19 outcomes via deep learning, Wanshan Ning et al., Nature Open Access
Fast automated detection of COVID-19 from medical images using convolutional neural networks, Shuang Liang et al. Research Square
A Fully Automated Deep Learning-based Network For Detecting COVID-19 from a New And Large Lung CT Scan Dataset, Mohammad Rahimzadeh et al. MedrxivDatasetCode
Mediapipe Iris megabyte model to predict 2D eye, eyebrow and iris geometry from monocular video captured by a front-facing camera on a smartphone in real time.
There are a few different algorithms for object detection and they can be split into two groups:
Algorithms based on classification – they work in two stages. In the first step, we’re selecting from the image interesting regions. Then we’re classifying those regions using convolutional neural networks. This solution could be very slow because we have to run prediction for every selected region. Most known example of this type of algorithms is the Region-based convolutional neural network (RCNN) and their cousins Fast-RCNN and Faster-RCNN.
Algorithms based on regression – instead of selecting interesting parts of an image, we’re predicting classes and bounding boxes for the whole image in one run of the algorithm. Most known example of this type of algorithms is YOLO (You only look once) commonly used for real-time object detection.
for Expressions reader, by Abhilash26 aka Dinodroid: detects 5 high level expressions (happiness, fear, anger, surprise, sadness) from the morph coefficients given by this lib, and display them as smileys. You can try it here: emotion-reader.glitch.me or browse the source code
Drake : Drake aims to simulate even very complex dynamics of robots (e.g. including friction, contact, aerodynamics, …), but always with an emphasis on exposing the structure in the governing equations (sparsity, analytical gradients, polynomial structure, uncertainty quantification, …) and making this information available for advanced planning, control, and analysis algorithms. Drake provides an interface to Python to enable rapid-prototyping of new algorithms, and also aims to provide solid open-source implementations for many state-of-the-art algorithms.
Program (latest official release, test builds and archive of previous versions): http://sasgis.org/download/ Attention! Servers with maps can be updated after the release, so the maps are strongly recommended to update anyway!
unpack the program somewhere, for example, c: \ SASPlanet, but not in c: \ Program Files and not in c: \ Program Files (x86)
unpack the maps into the Maps directory (since they are newer than in the archive with the program). You should get SASPlanet \ Maps \ sas.maps \ and SASPlanet \ Maps \ plus.maps \.
Important contribution instructions: If you add new content, please ensure that for any notebook you link to, the link is to the rendered version using nbviewer, rather than the raw file. Simply paste the notebook URL in the nbviewer box and copy the resulting URL of the rendered version. This will make it much easier for visitors to be able to immediately access the new content.
Note that Matt Davis has conveniently written a set of bookmarklets and extensions to make it a one-click affair to load a Notebook URL into your browser of choice, directly opening into nbviewer.
The code of the IPython mini-book by C. Rossant, introducing IPython, NumPy, SciPy, Pandas and matplotlib for interactive computing and data visualization.
Automata and Computability using Jupyter, an entire course, based on forthcoming book published by Taylor and Francis; book title: “Automata and Computability: Programmer’s Perspective”, by Ganesh Gopalakrishnan, Professor, School of Computing, University of Utah, Salt Lake City. [in English, has Youtube videos]
Numeric Computing is Fun A series of notebooks created to help educate aspiring computer programmers and data scientists of all ages with no previous programming experience.
Exploratory Computing with Python, a set of 15 Notebooks that cover exploratory computing, data analysis, and visualization. No prior programming knowledge required. Each Notebook includes a number of exercises (with answers) that should take less than 4 hours to complete. Developed by Mark Bakker for undergraduate engineering students at the Delft University of Technology.
Code Katas in Python, a collection of algorithmic and data structure exercises covering search and sorting algorithms, stacks, queues, linked lists, graphs, backtracking and greedy problems.
Doing Bayesian Data Analysis: Python/PyMC3 code for a selection of models and figures from the book ‘Doing Bayesian Data Analysis: A Tutorial with R, JAGS, and Stan’, Second Edition, by John Kruschke (2015).
Machine Learning with the Shogun Toolbox. This is a complete service that includes a ready-to-run IPython instance with a collection of notebooks illustrating the use of the Shogun Toolbox. Just log in and start running the examples.
Data Science Notebooks, a frequently updated collection of notebooks on statistical inference, data analysis, visualization and machine learning, by Donne Martin.
the-elements-of-statistical-learning, a collection of notebooks implementing the algorithms, reproducing the graphics found in the book “The Elements of Statistical Learning” by Trevor Hastie, Robert Tibshirani and Jerome Friedman and summary of the textbook.
Interactive Machine Learning Experiments - collection of notebooks that use convolutional neural networks (CNNs), recurrent neural networks (RNNs) and multilayer perceptrons (MLPs) to solve basic machine learning tasks like objects detection and classification, sequence-to-sequence predictions etc.
Astrophysical simulations and analysis with yt: a collection of example notebooks on using various codes that yt interfaces with: Enzo, Gadget, RAMSES, PKDGrav and Gasoline. Note: the yt site currently throws an SSL warning, they seem to have an outdated or self-signed certificate.
Practical Numerical Methods with Python, a collection of learning modules (each consisting of several IPython Notebooks) for a course in numerical differential equations taught at George Washington University by Lorena Barba. Also offered as a “massive, open online course” (MOOC) on the GW SEAS Open edX platform.
Get Data Off the Ground with Python by Lorena Barba: Learn to interact with Python and handle data with Python; assumes no coding experience and creates a foundation in programming applied to technical contexts. With an accompanying online course.
The notebooks from the Book Bioinformatics with Python Cookbook, covering several fields like Next-Generation Sequencing, Population Genetics, Phylogenetics, Genomics, Proteomics and Geo-referenced information.
Learning Population Genetics in an RNA world is an interactive notebook that explains basic population genetics tools and techniques by building an in silico evolutionary model of RNA molecules.
seismo-live is a collection of live Jupyter notebooks for seismology. It includes a fairly large number of notebooks on how to solve the acoustic and elastic wave equation with various different numerical methods. Additionally it contains notebooks with an extensive introduction to data handling and signal processing in seismology, and notebooks tackling ambient seismic noise, rotational and glacial seismology, and more.
Geo-Python is an introduction to programming in Python for Bachelors and Masters students in geo-fields (geology, geophysics, geography) taught by members of the Department of Geosciences and Geography at University of Helsinki, Finland. Course lessons and exercises are based on Jupyter notebooks and open for use by any interested person.
Introduction to Chemical Engineering Analysis by Jeff Kantor. A collection of IPython notebooks illustrating topics in introductory chemical engineering analysis, including stoichiometry, generation-consumption analysis, mass and energy balances.
Comparing different approaches to evolutionary simulations. Also available here to better visualization. The notebook was converted to a HTML presentation using an old nbconvert with the first developing implementation of reveal converter. By Yoav Ram.
CodeCombat gridmancer solver by Arn-O. This notebook explains how to improve a recursive tree search with an heuristic function and to find the minimum solution to the gridmancer.
Cue Combination with Neural Populations by Will Adler. Intuition and simulation for the theory (Ma et al., 2006) that through probabilistic population codes, neurons can perform optimal cue combination with simple linear operations. Demonstrates that variance in cortical activity, rather than impairing sensory systems, is an adaptive mechanism to encode uncertainty in sensory measurements.
Python for Vision Research. A three-day crash course for vision researchers in programming with Python, building experiments with PsychoPy and psychopy_ext, learning the fMRI multi-voxel pattern analysis with PyMVPA, and understading image processing in Python.
Comparing different approaches to evolutionary simulations. Also available here to better visualization. The notebook was converted to a HTML presentation using an old nbconvert with the first developing implementation of reveal converter. By Yoav Ram.
fecon235 for Financial Economics series of notebooks which examines time-series data for economics and finance. Easy API to freely access data from the Federal Reserve, SEC, CFTC, stock and futures exchanges. Thus research from older notebooks can be replicated, and updated using the most current data. For example, this notebook forecasts likely Fed policy for setting the Fed Funds rate, but market sentiment across major asset classes is observable from the CFTC Commitment of Traders Report. Major economics indicators are renormalized: for example, various measures of inflation, optionally with the forward-looking break-even rates derived from U.S. Treasury bonds. Other notebooks examine international markets: especially, gold and foreign exchange.
bqplot is a d3-based interactive visualization library built entirely on top of that ipywidgets infrastructure. Checkout the pythonic recreation of Hans Rosling’s Wealth of Nations.
Linear algebra with Cython. A tutorial that styles the notebook differently to show that you can produce high-quality typography online with the Notebook. By Carl Vogel.
The Matrix Exponential, an introduction to the matrix exponential, its applications, and a list of available software in Python and MATLAB. By Sam Relton.
Introduction to Mathematics with Python, a collection of notebooks aimed at Mathematicians with no/little Python knowledge. Notebooks can be selected to serve as resources for a workshop. By Vince Knight.
These are notebooks that use [one of the IPython kernels for other languages](IPython kernels for other languages):
Julia
The IPython protocols to communicate between kernels and clients are language agnostic, and other programming language communities have started to build support for this protocol in their language. The Julia team has created IJulia, and these are some Julia notebooks:
This section contains academic papers that have been published in the peer-reviewed literature or pre-print sites such as the ArXiv that include one or more notebooks that enable (even if only partially) readers to reproduce the results of the publication. If you include a publication here, please link to the journal article as well as providing the nbviewer notebook link (and any other relevant resources associated with the paper).
The Paper of the Future by Alyssa Goodman et al. (Authorea Preprint, 2017). This article explains and shows with demonstrations how scholarly “papers” can morph into long-lasting rich records of scientific discourse, enriched with deep data and code linkages, interactive figures, audio, video, and commenting. It includes an interactive d3.js visualization and has an astronomical data figure with an IPYthon Notebook “behind” it.
pyKNEEr: An image analysis workflow for open and reproducible research on femoral knee cartilage, a preprint by S. Bonaretti et al. Jupyter notebooks are used as a graphical user interface for medical image processing and analysis. The paper is interactive, with links to data, software, and documentation throughout the text. Every figure caption contains links to fully reproduce graphs.
Conway’s Game of Life. Interesting use of convolution operation to calculate the next state of game board, instead of obvious find neighbors and filter the board for next state.
pynguins. Using jupyter notebook, python, and numpy to solve Board Game “Penguins on Ice”.
“People plots”, stick figures generated with matplotlib.
Reveal converter mini-tutorial, also available in blog post form. Do you want to make static html/css slideshow straight from the IPython notebook? OK, now you can do it with the reveal converter (nbconvert). Demo by Damián Avila.
Of course the first thing you might try is searching for videos about IPython (1900 or so by last count on Youtube) but there are demonstrations of other applications using the power of IPython but are not mentioned is the descriptions. Below are a few such:
Video on how to learn Python featuring IPython as the platform of choice for learning!






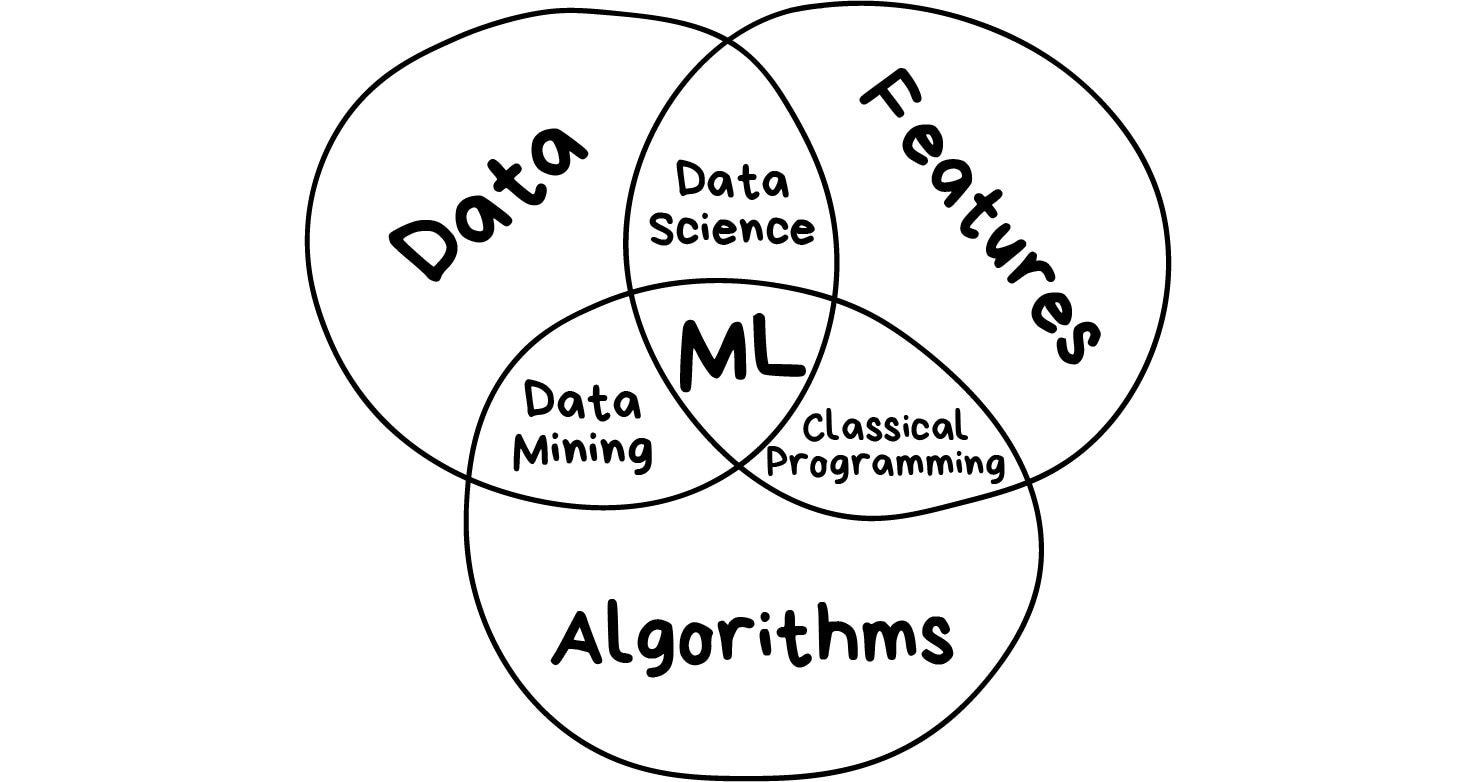
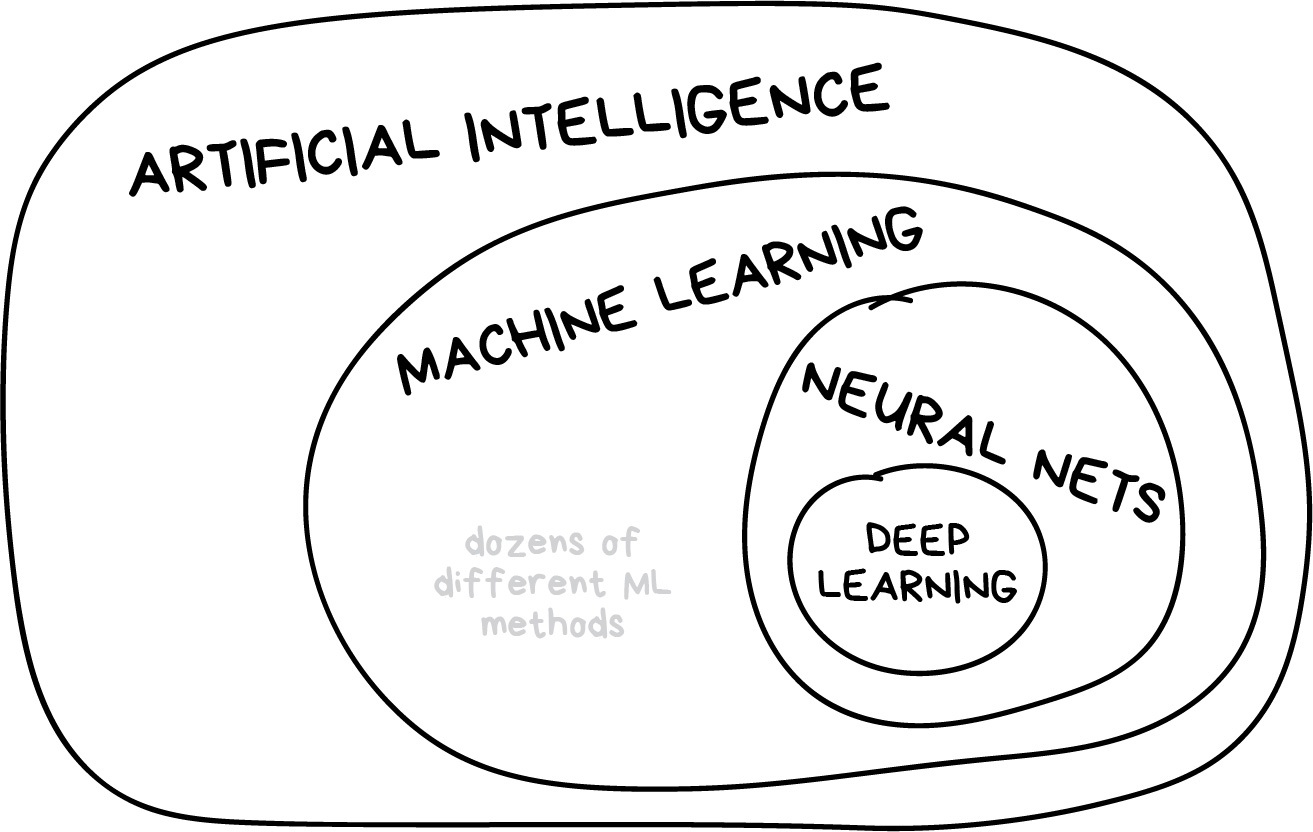
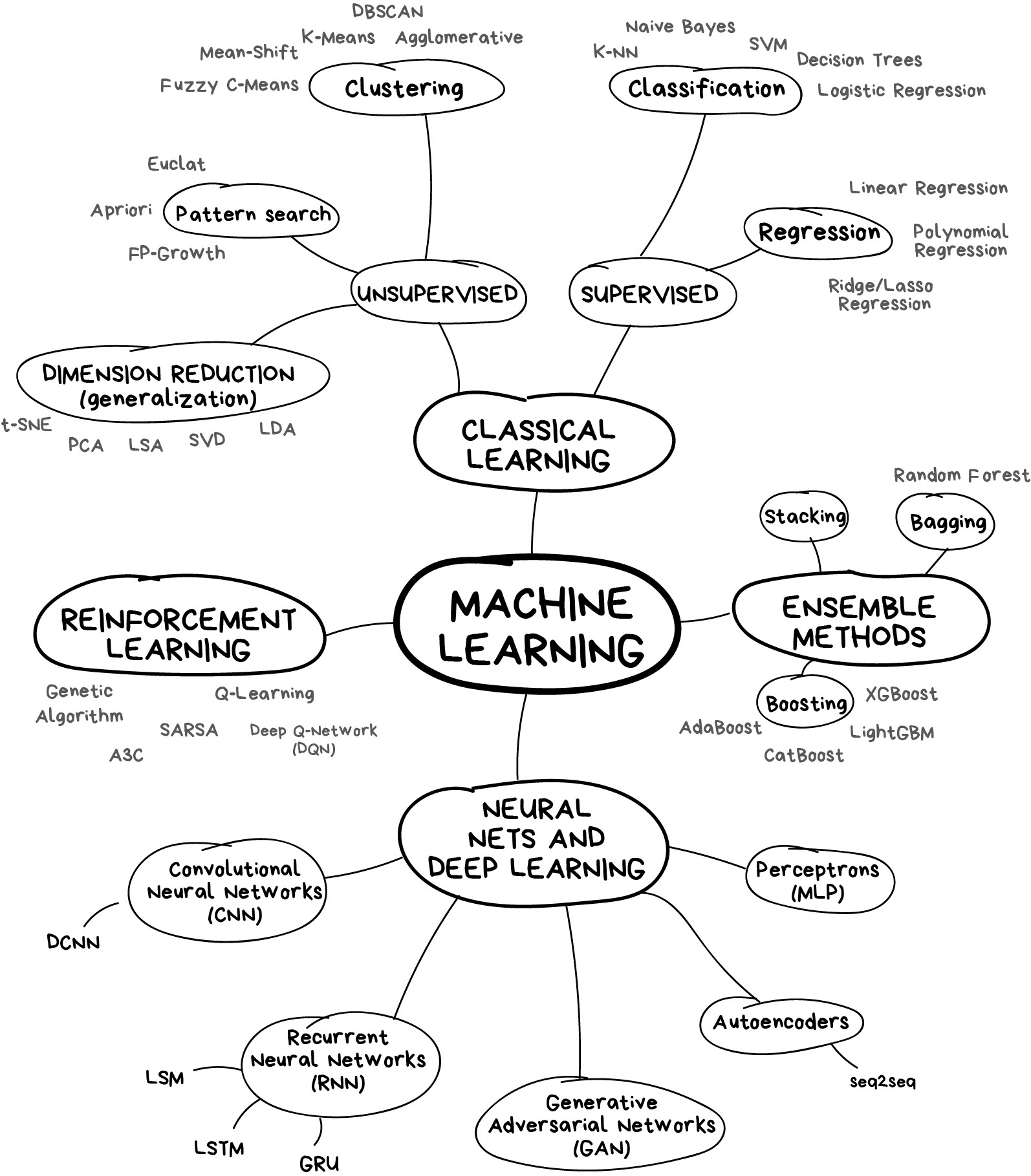
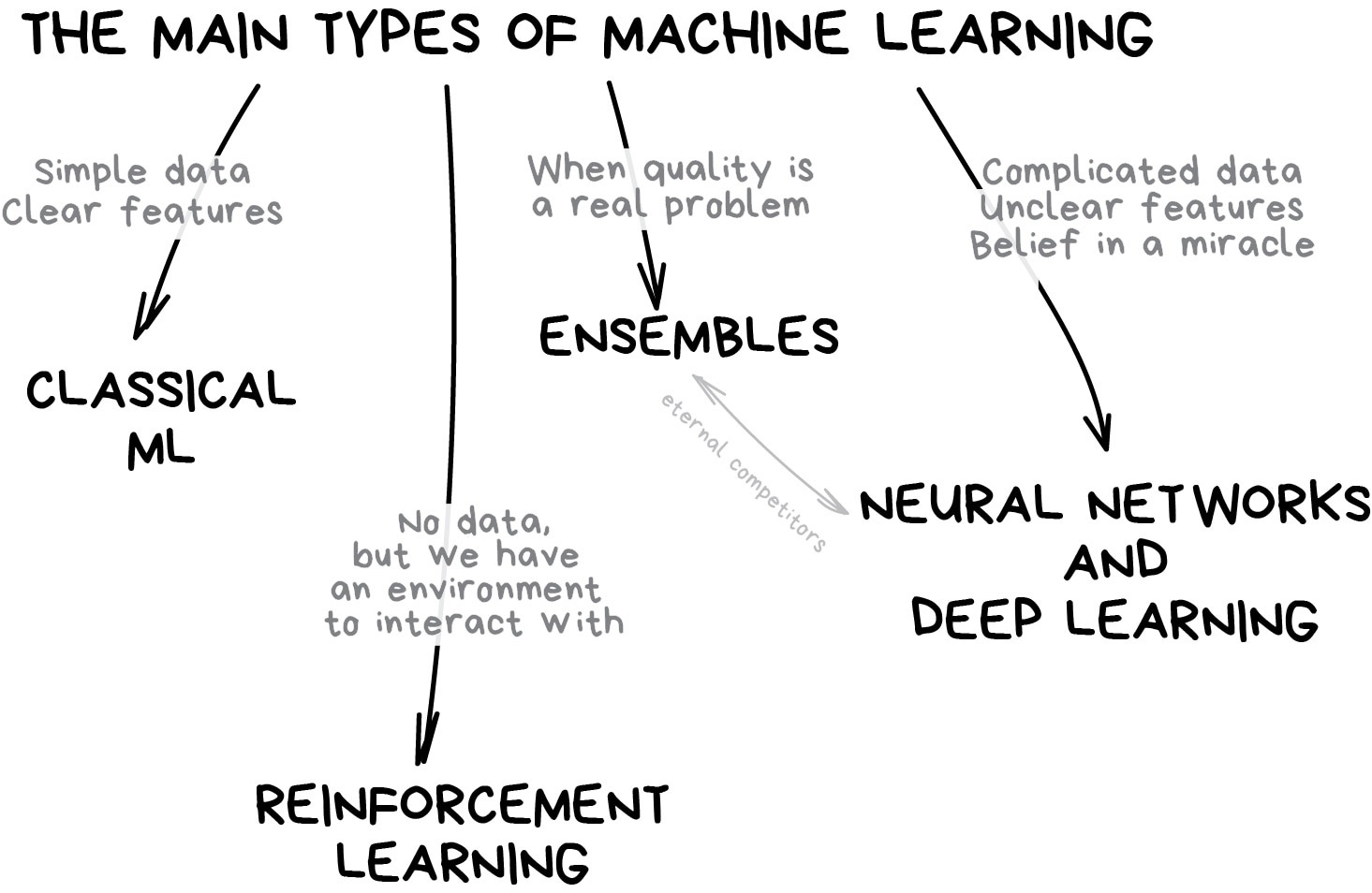
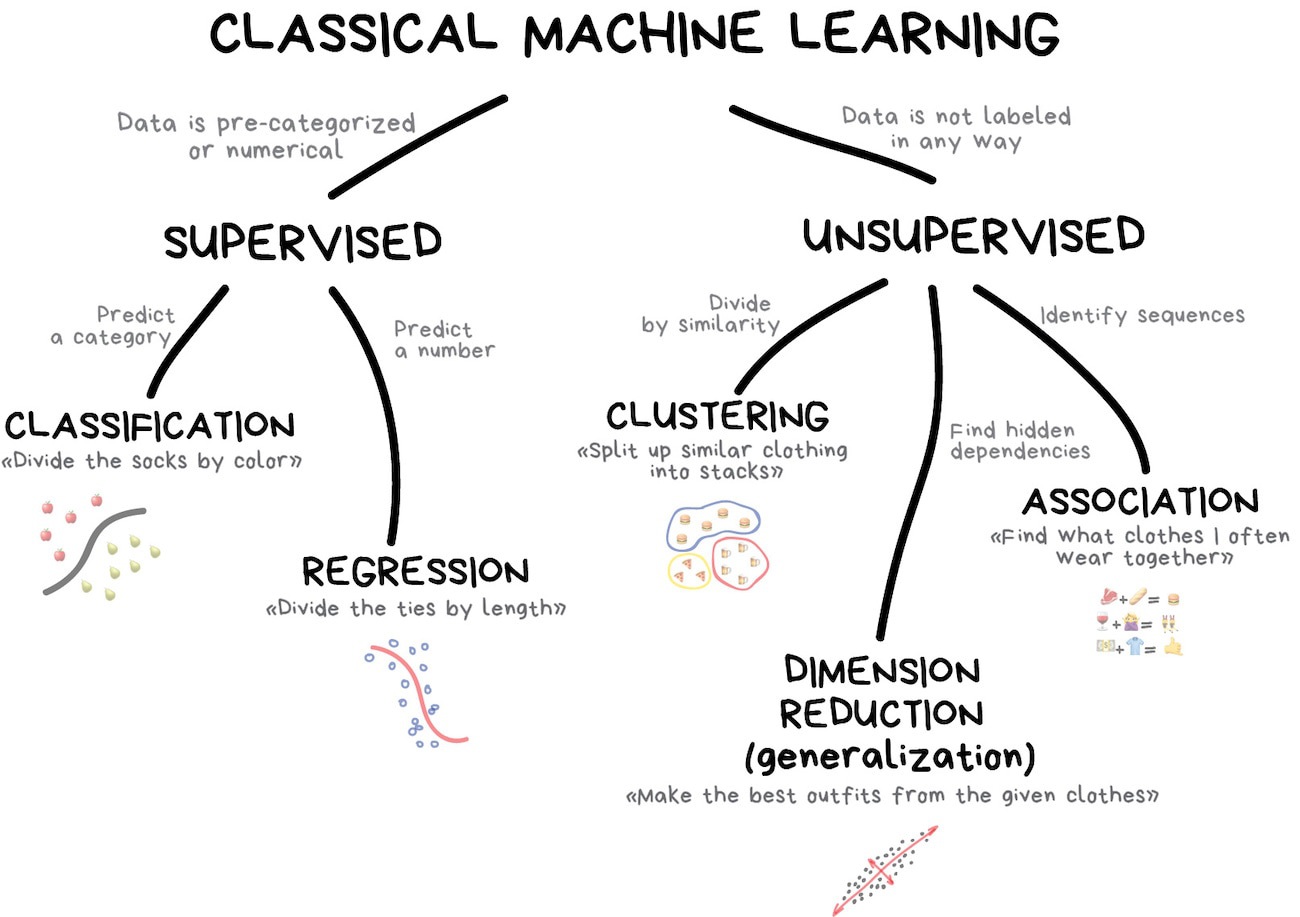
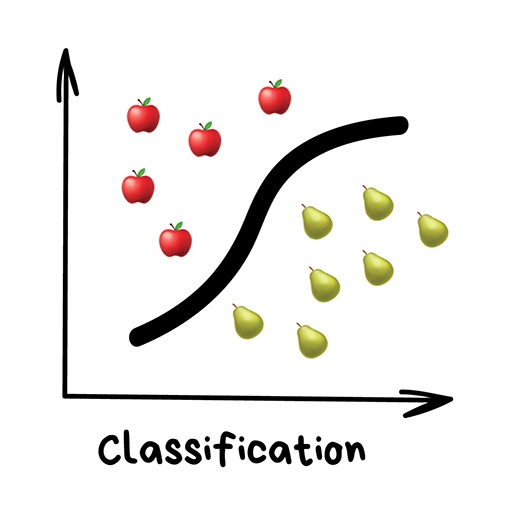
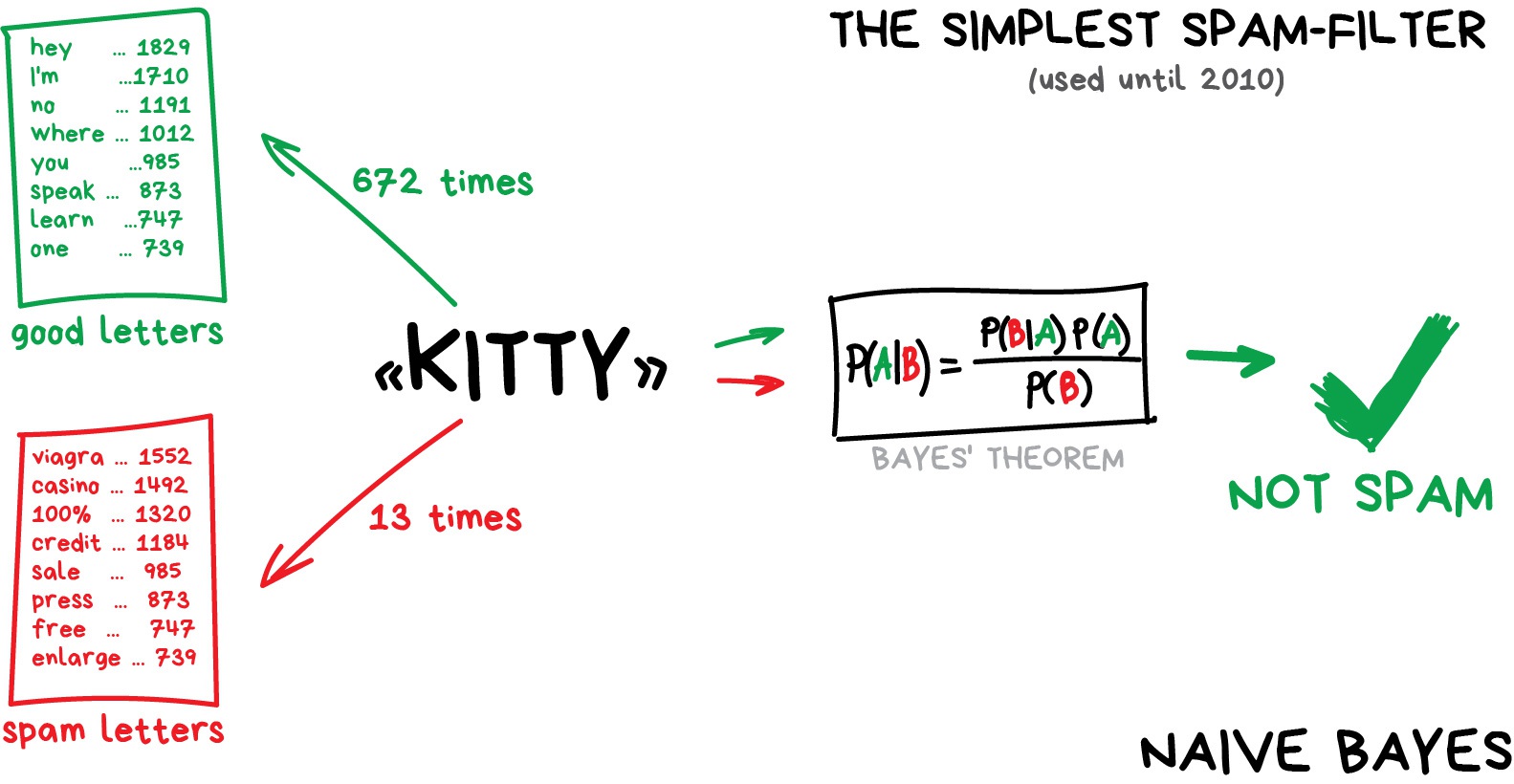
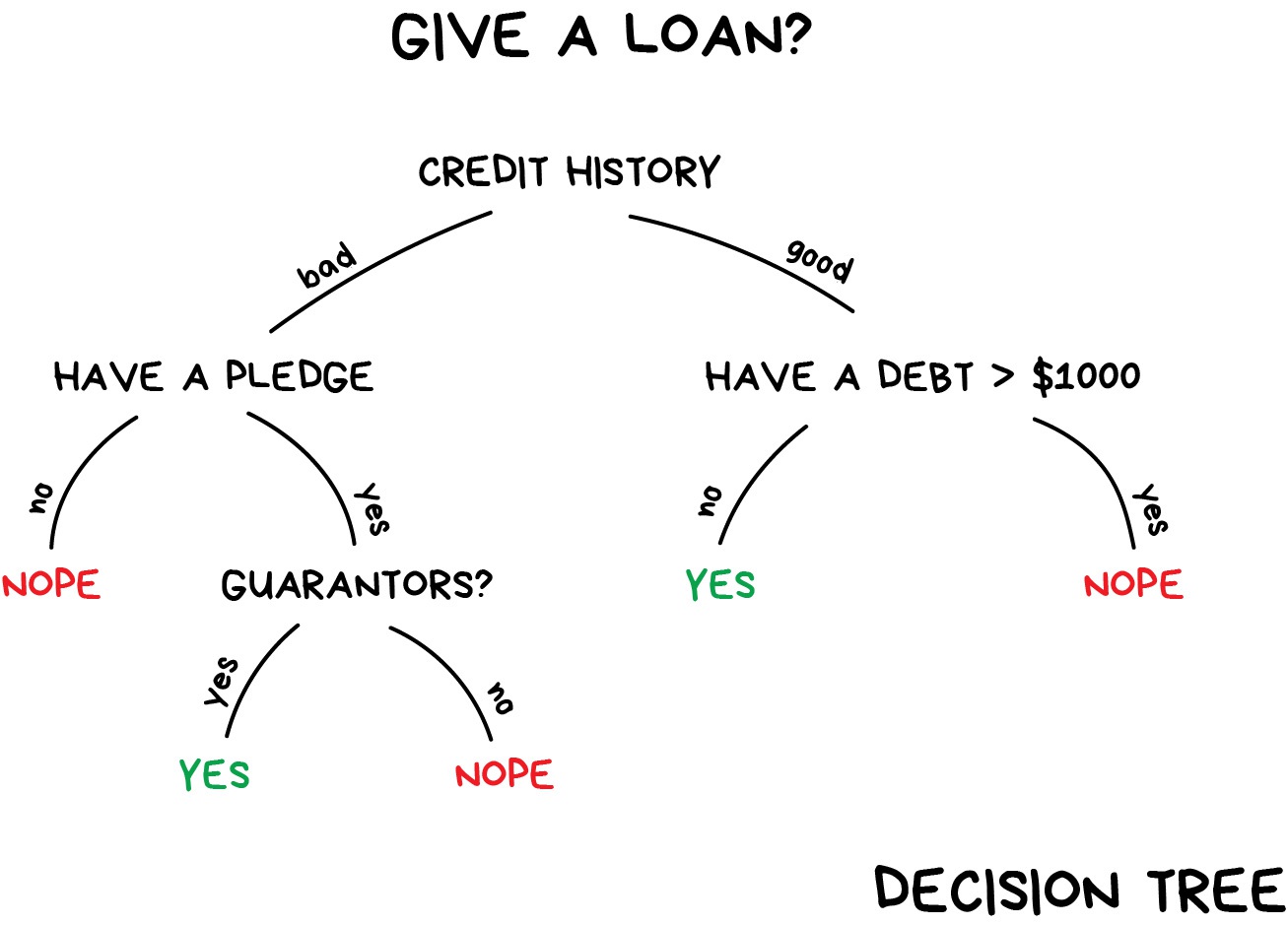
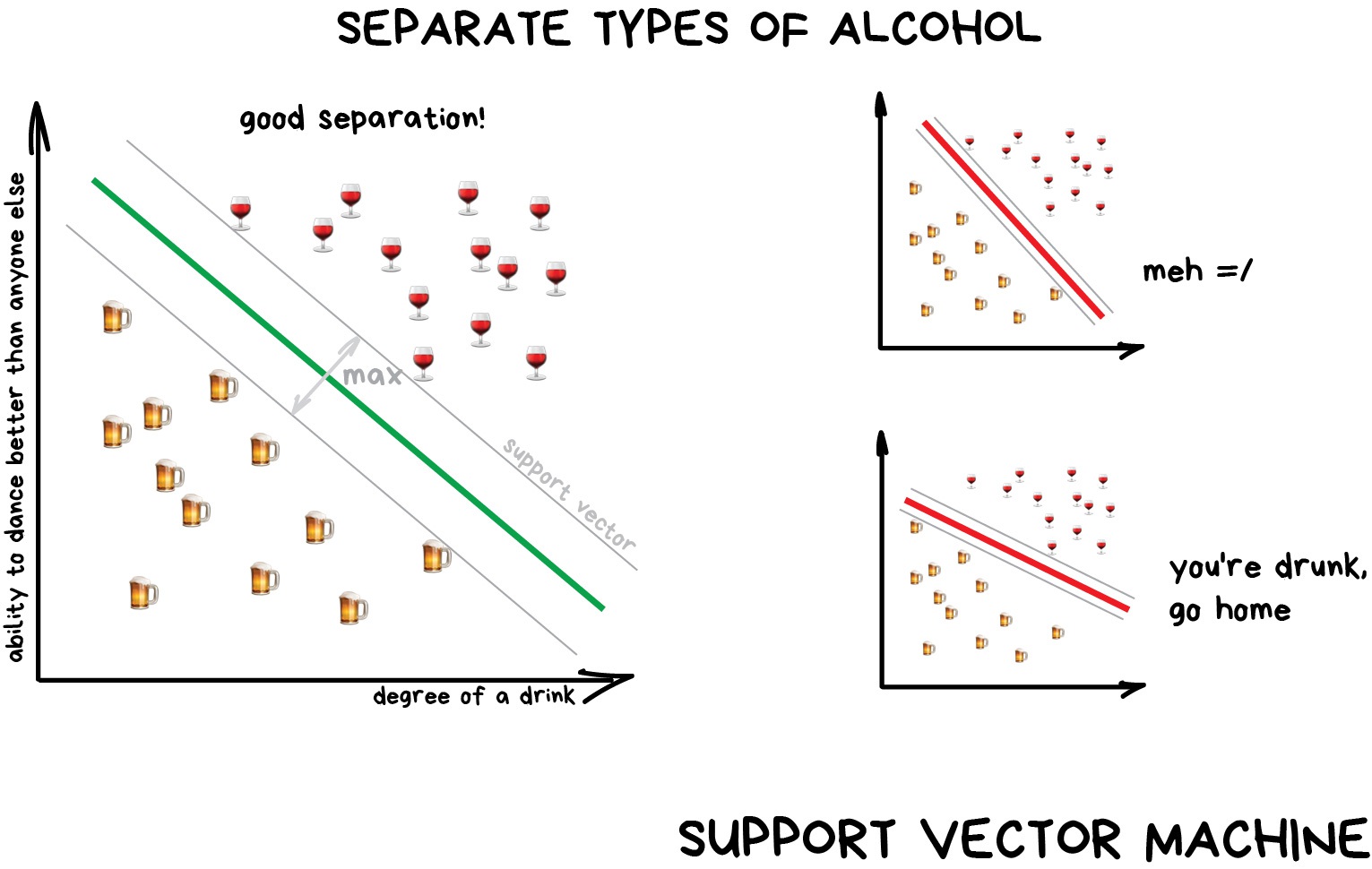
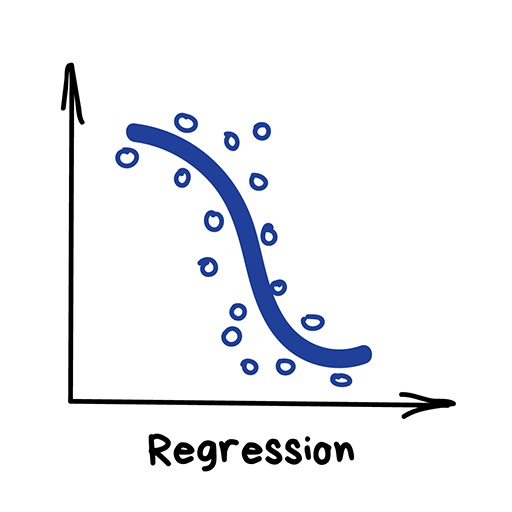
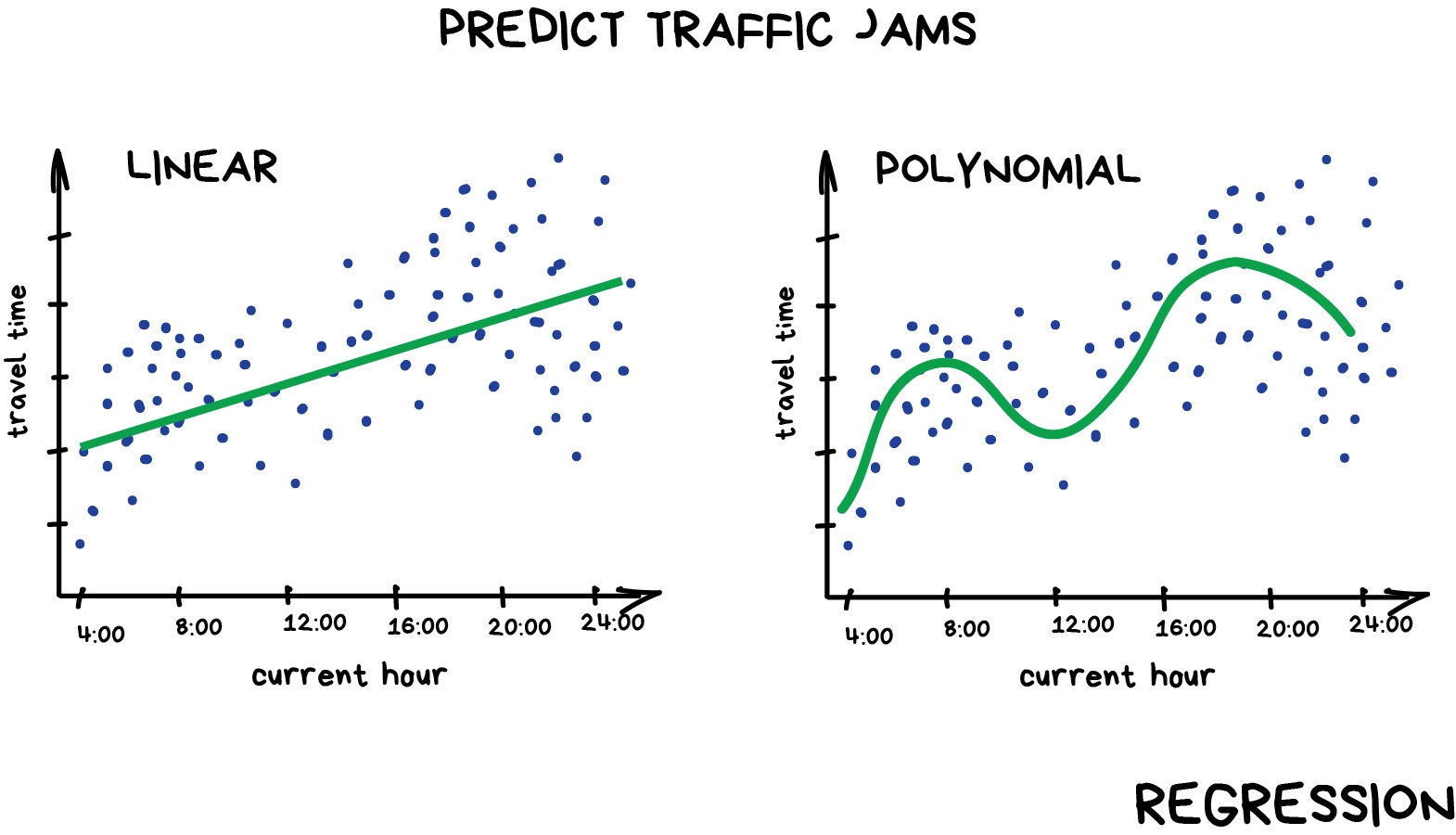
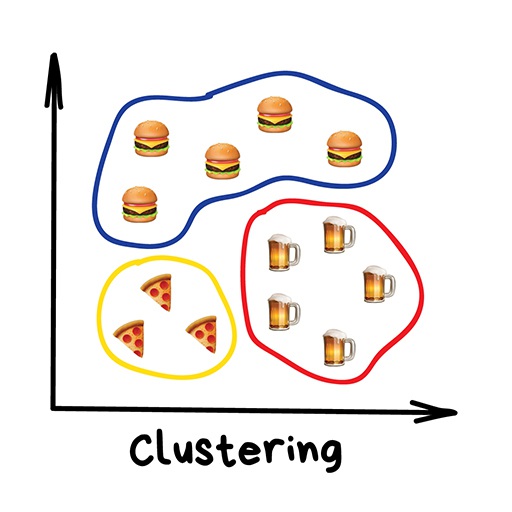
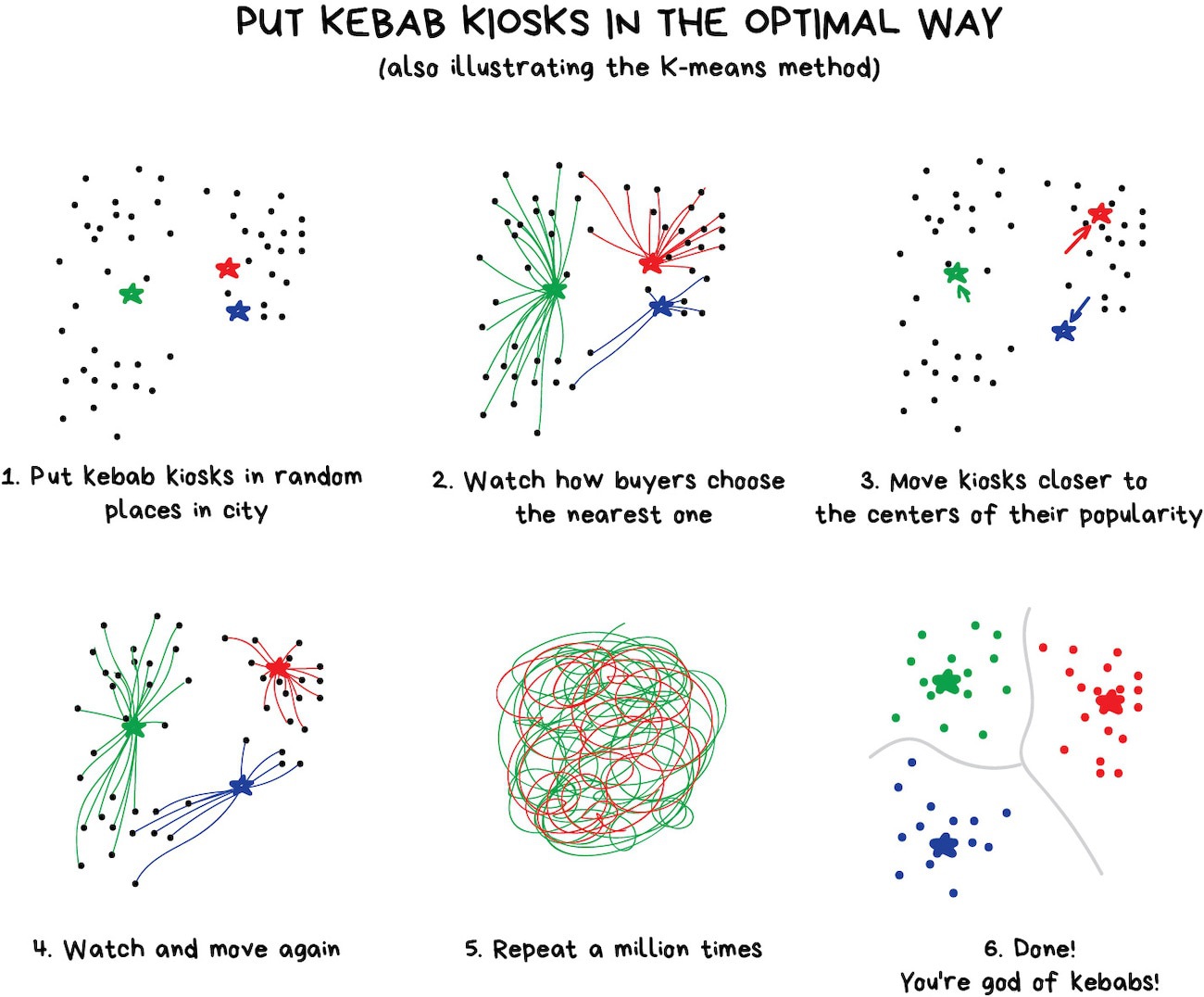
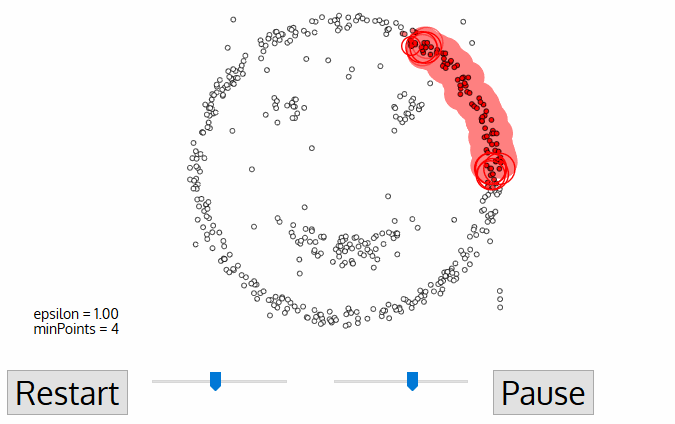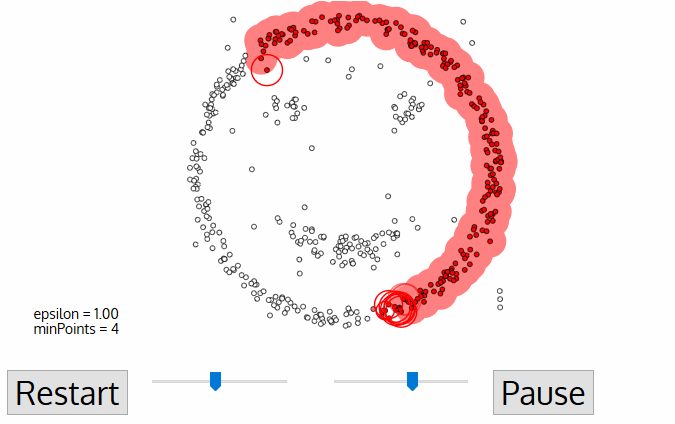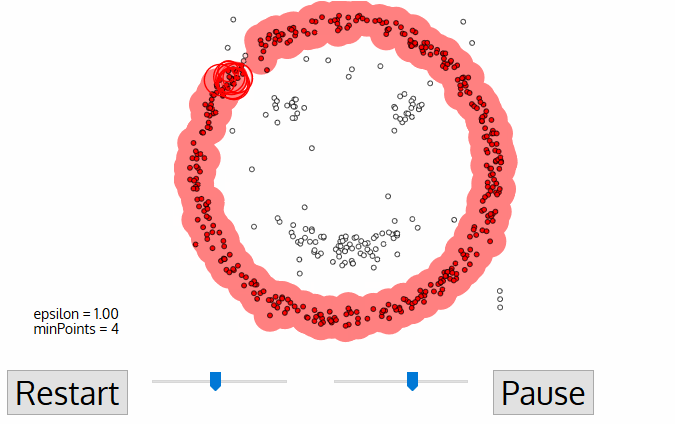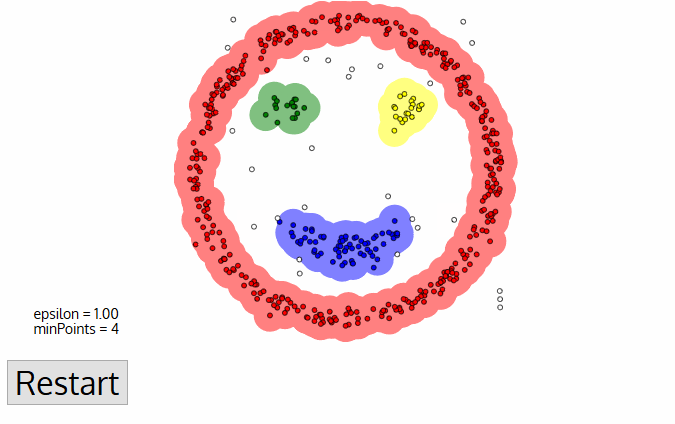


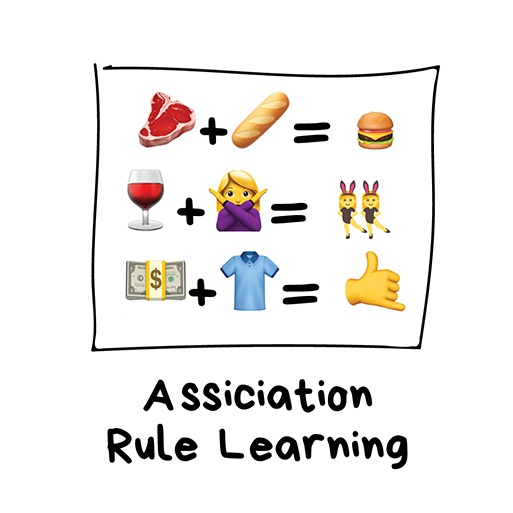

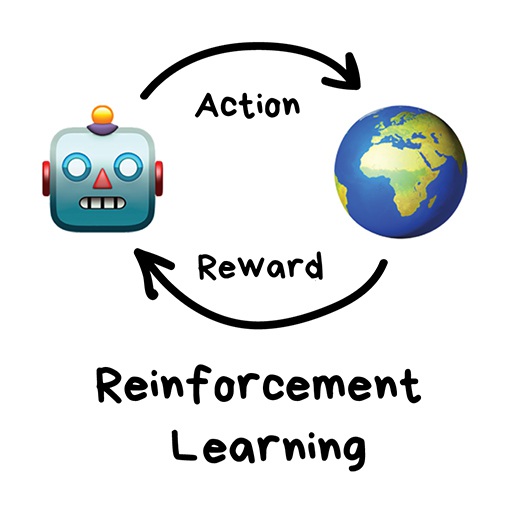

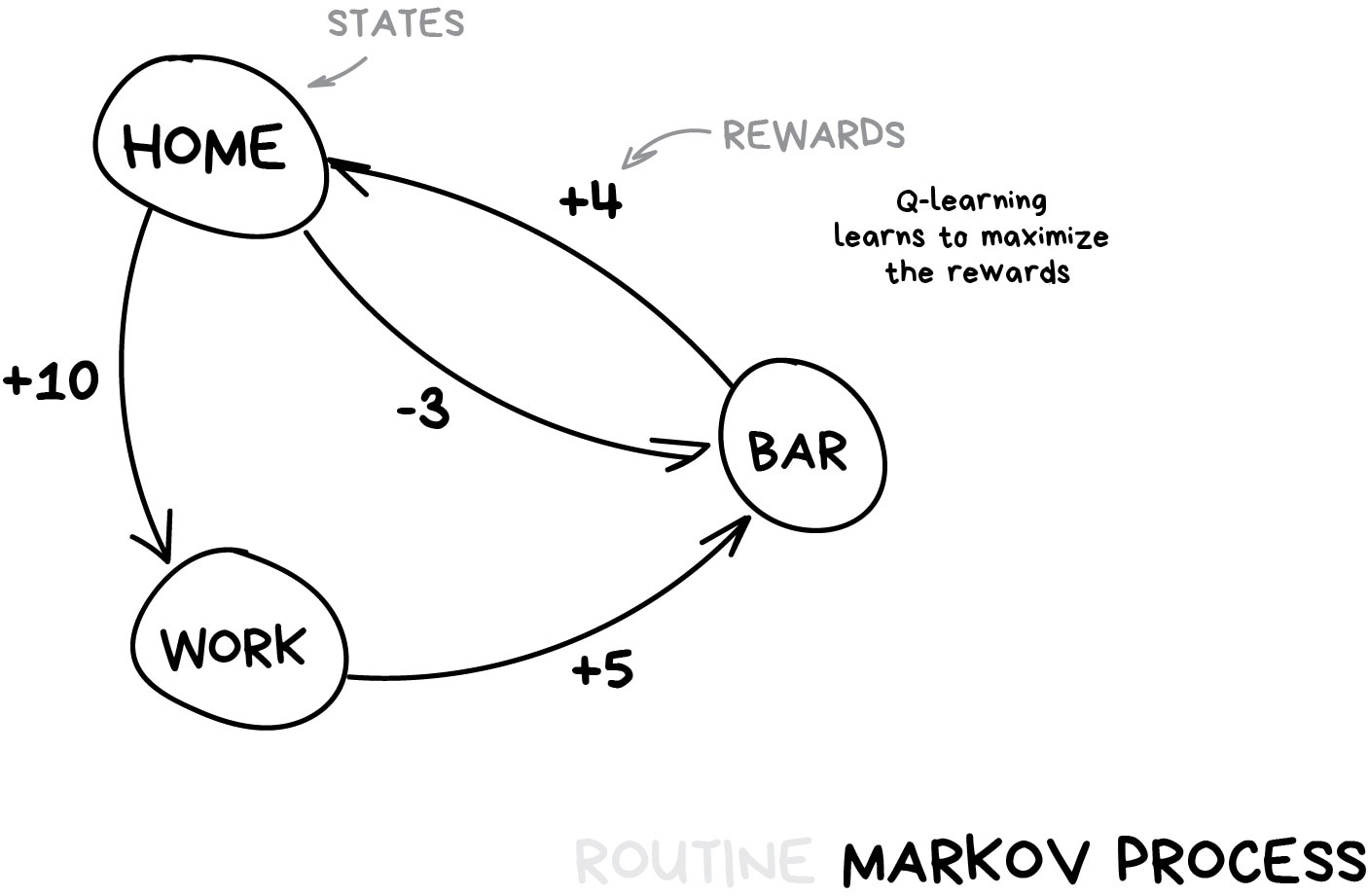
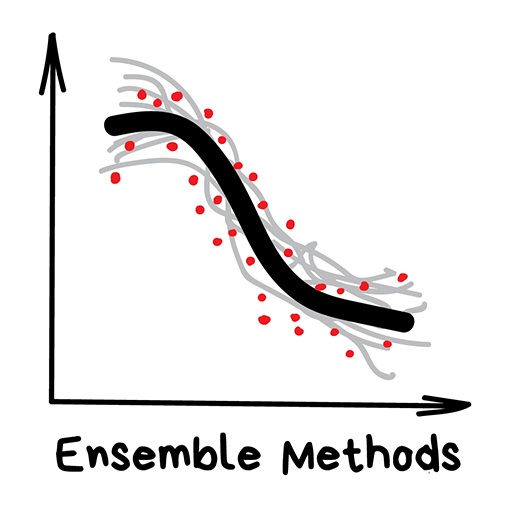
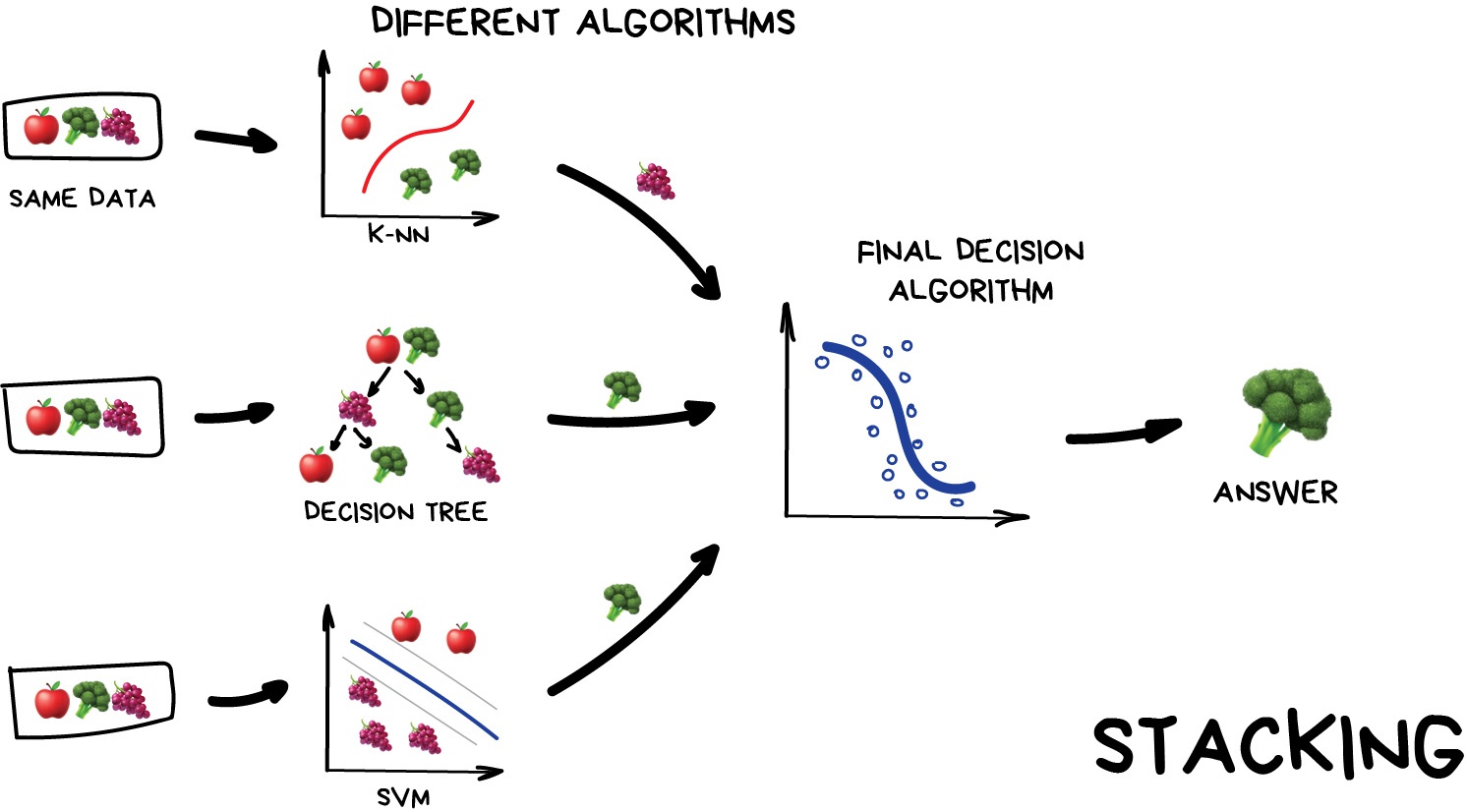
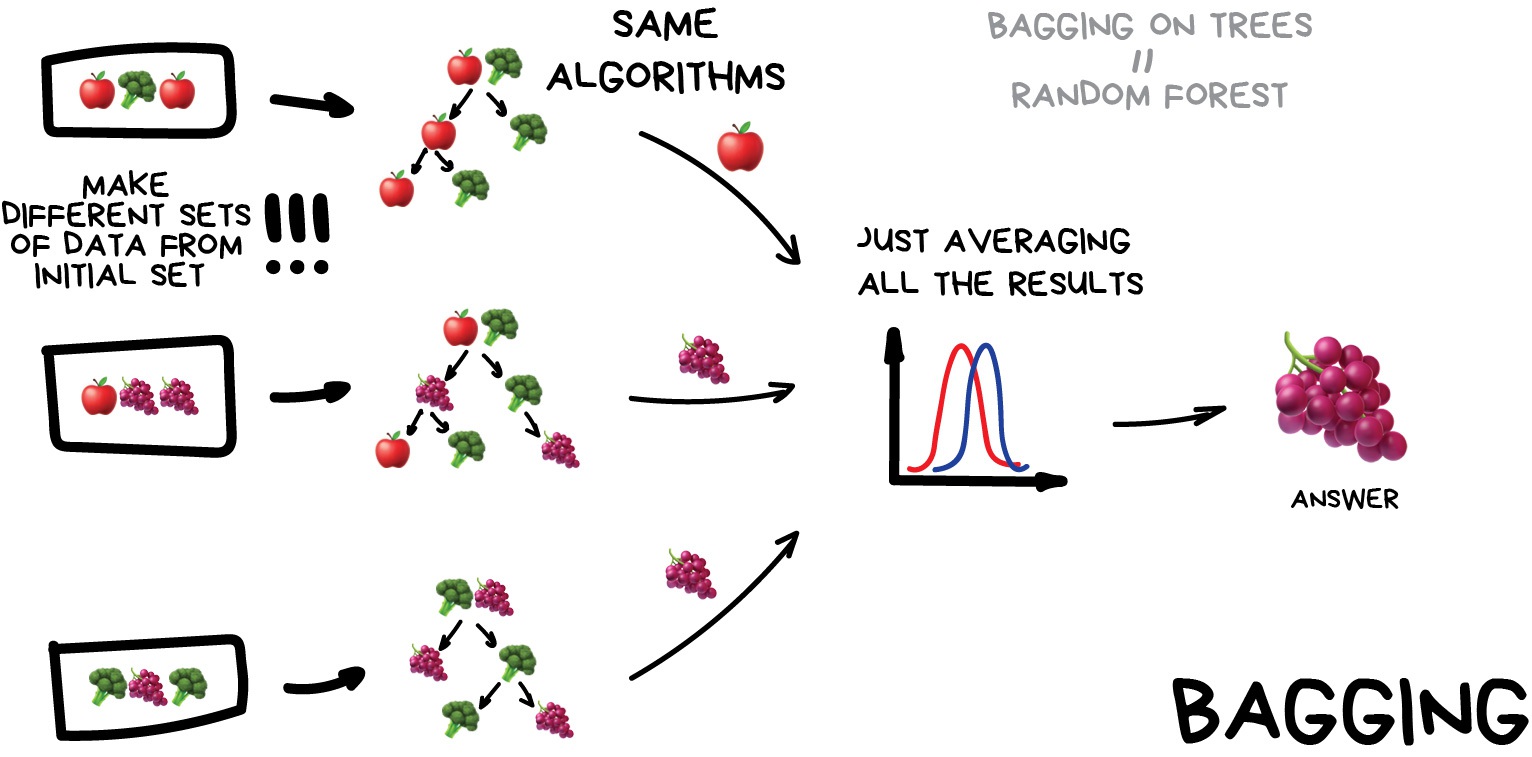

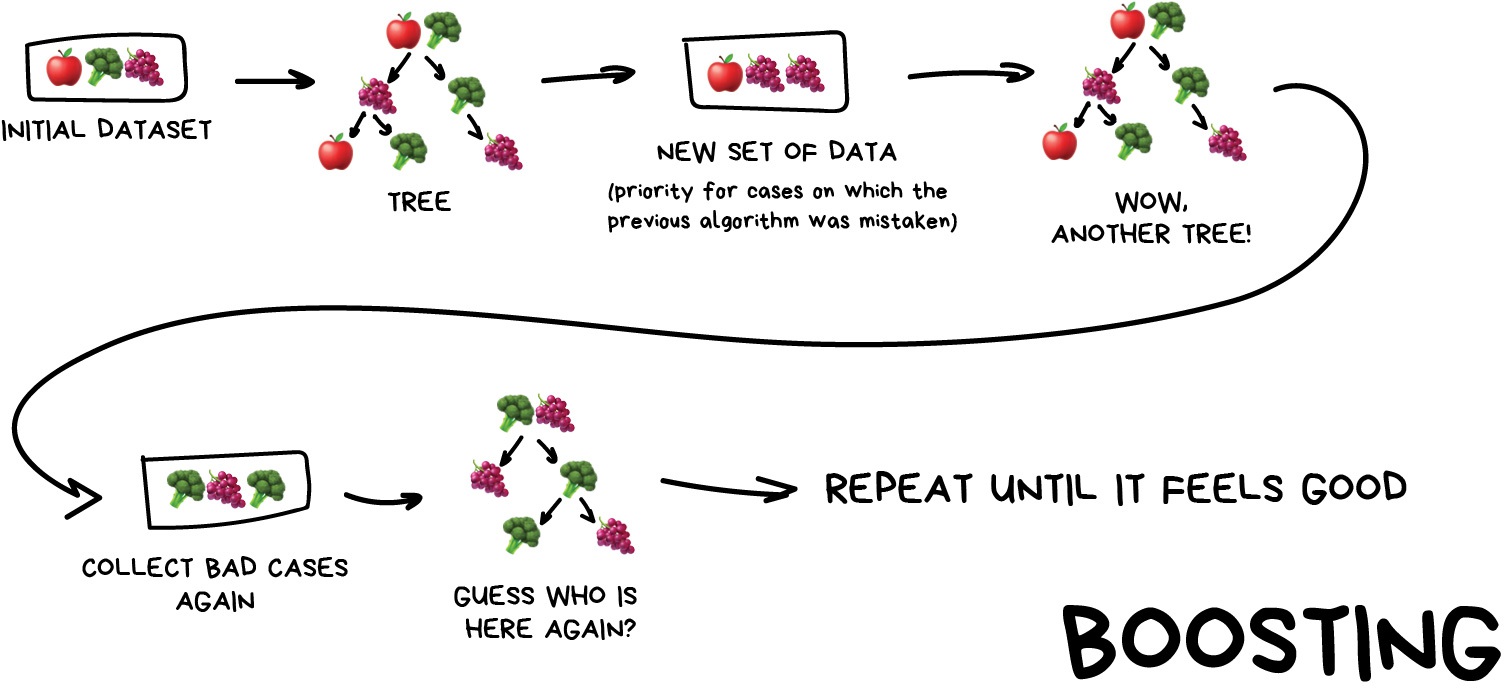
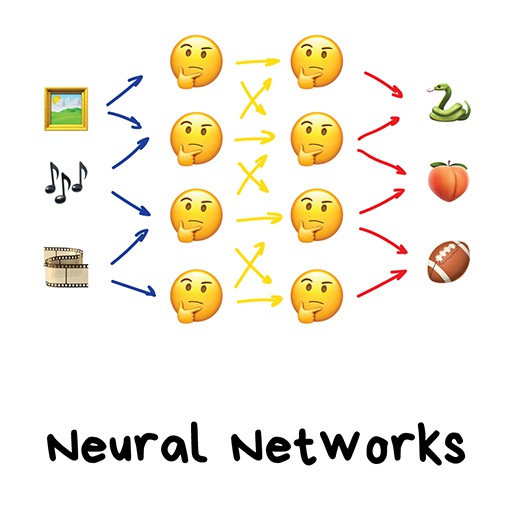
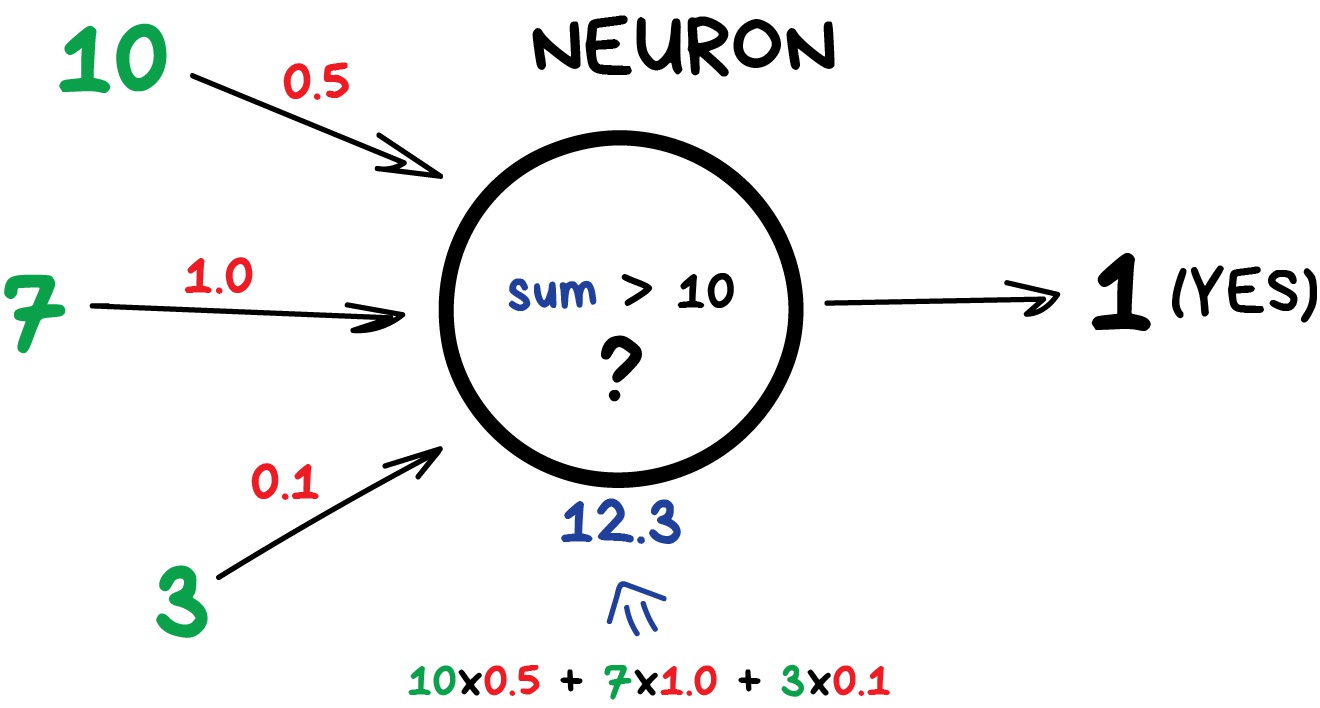
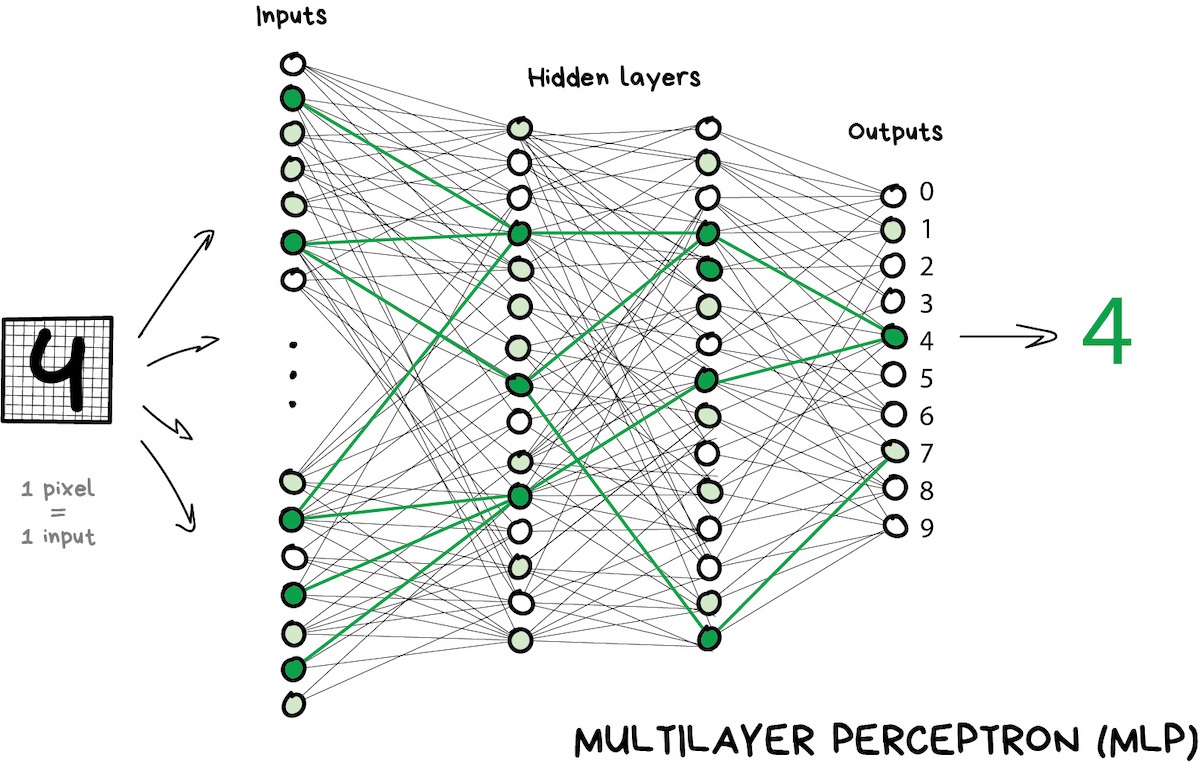

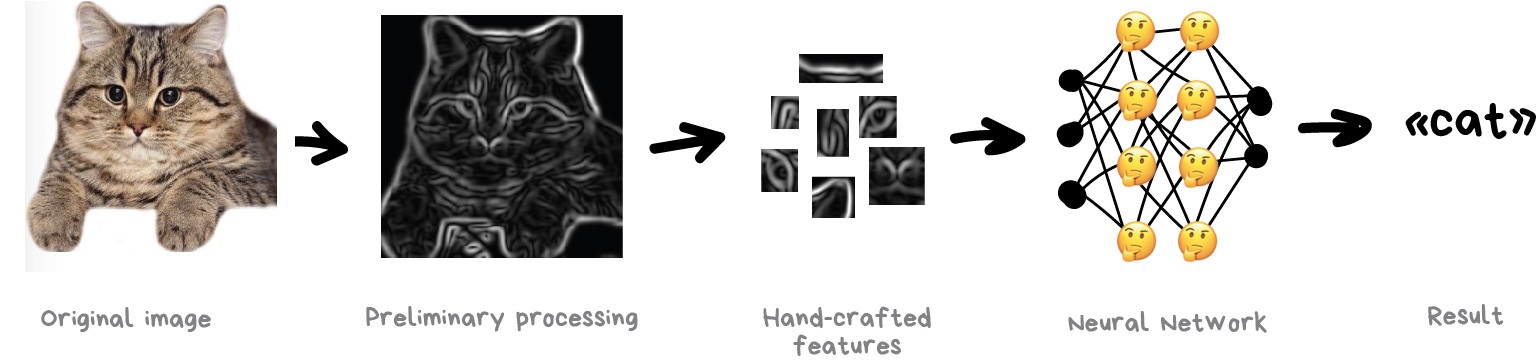
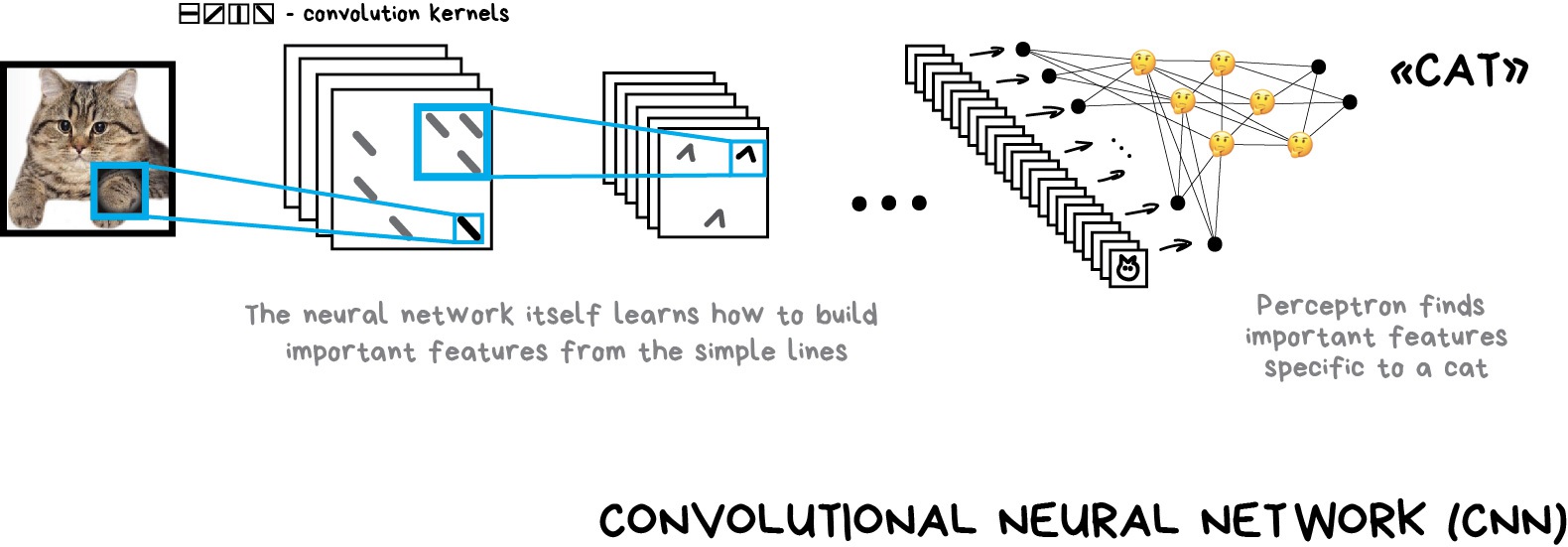

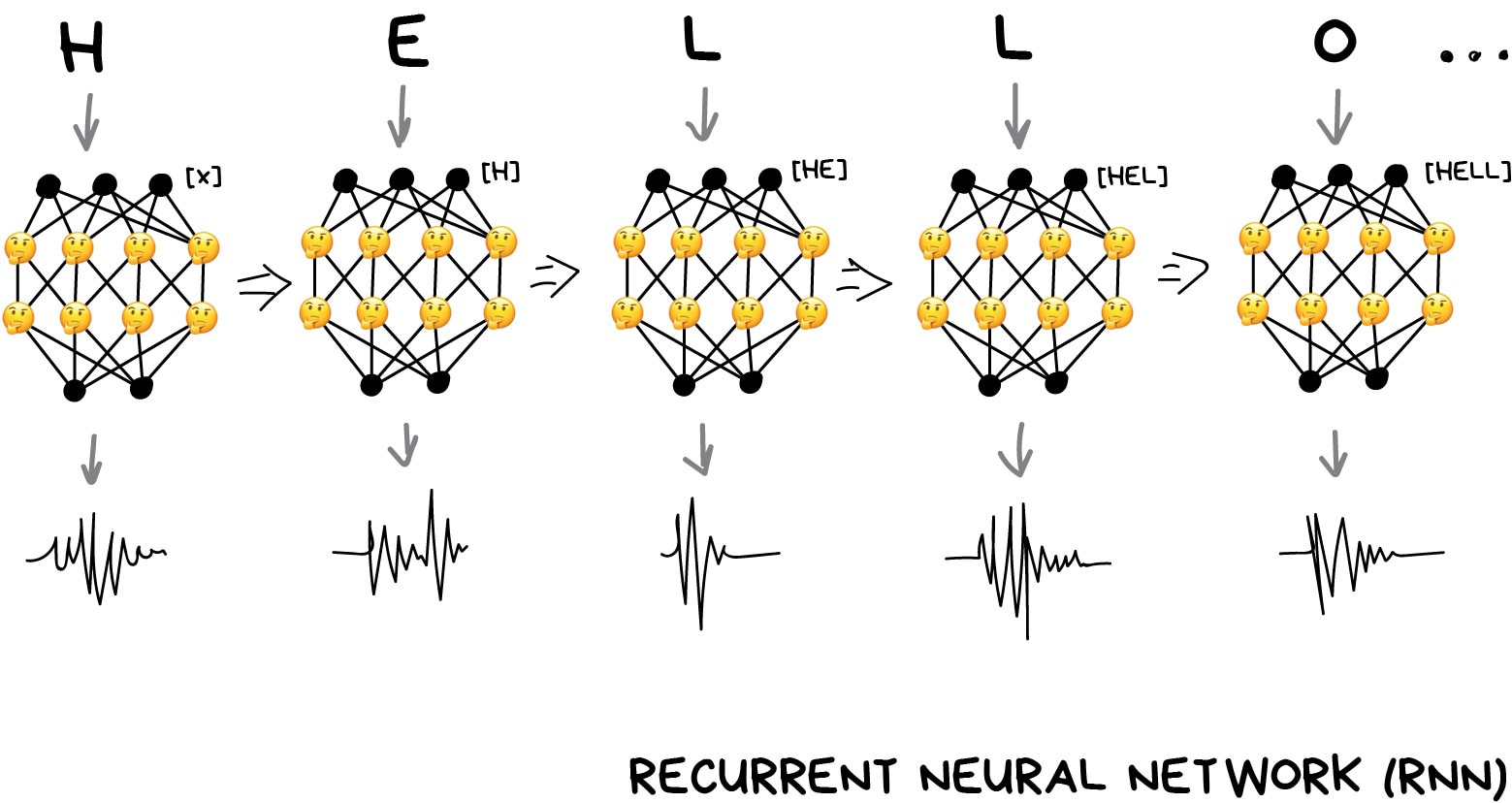

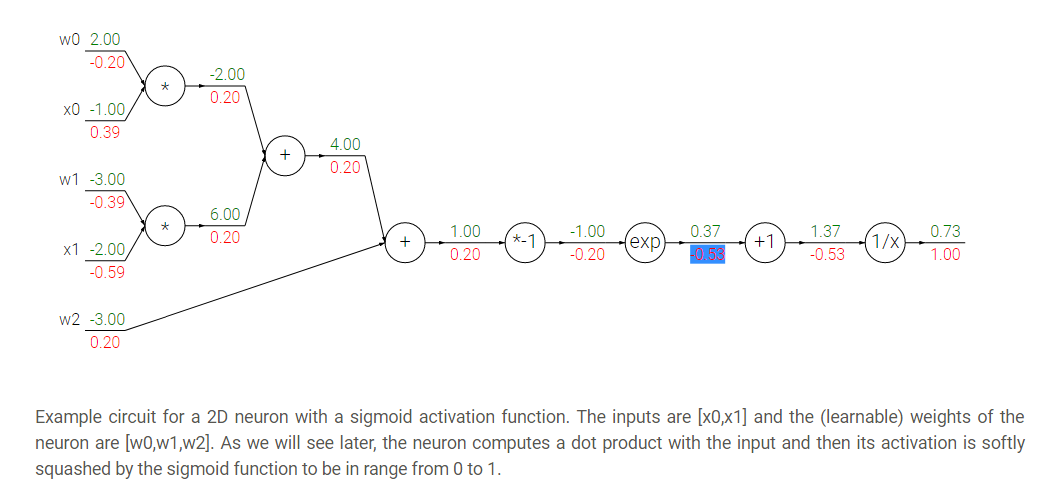
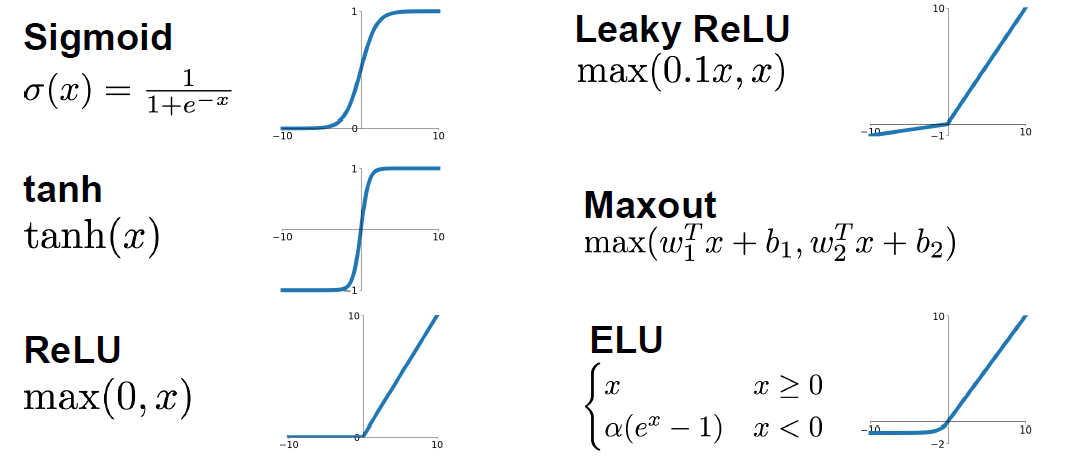
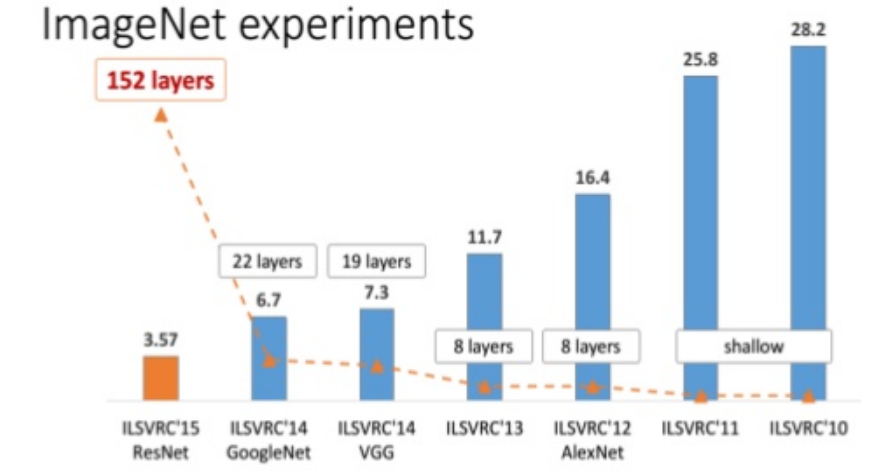
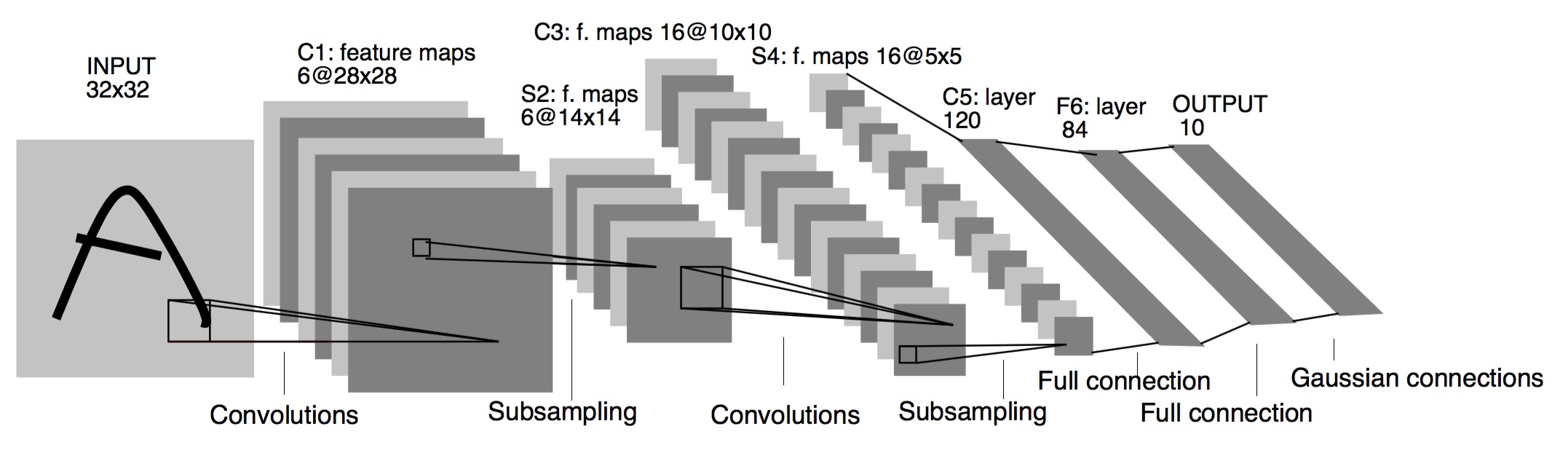

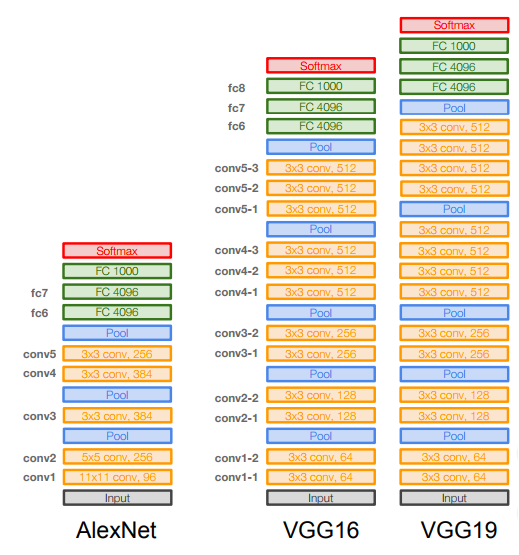
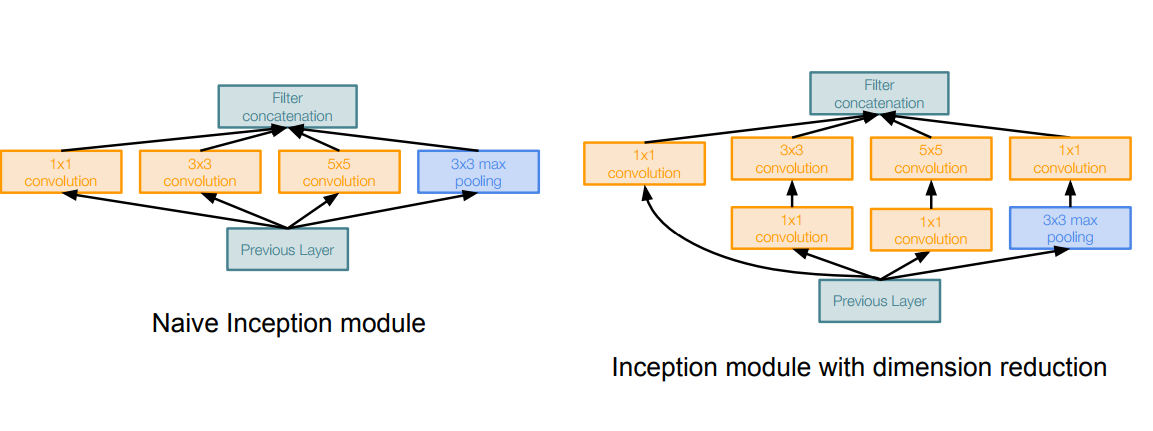
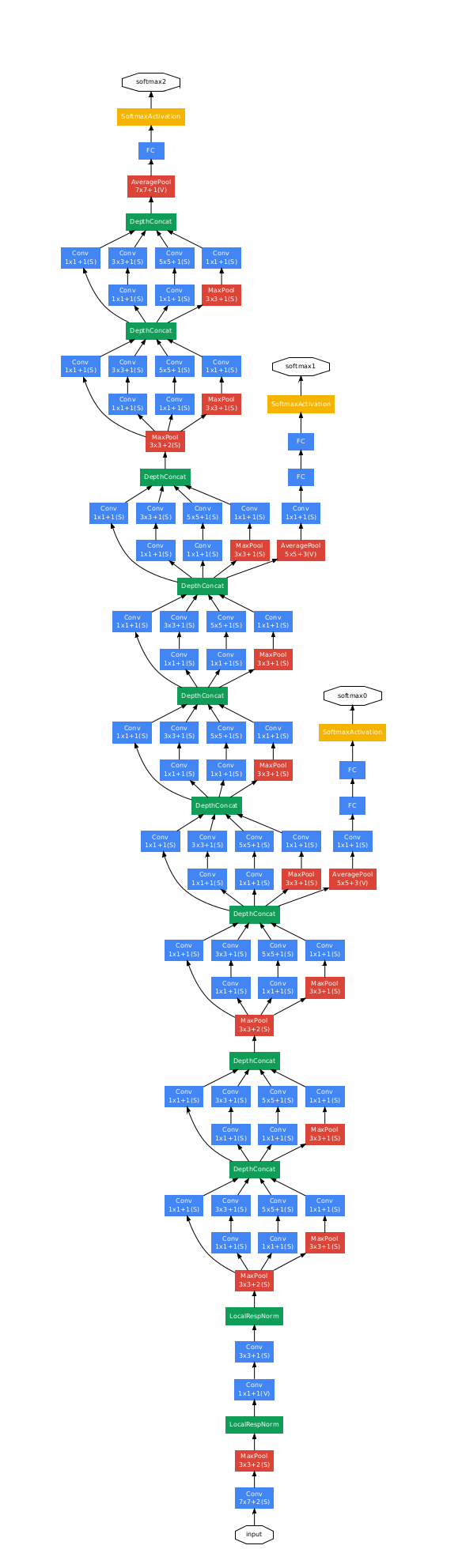
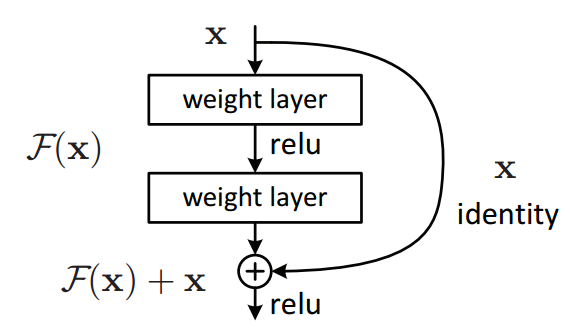
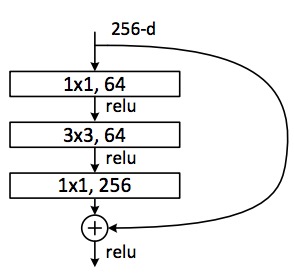
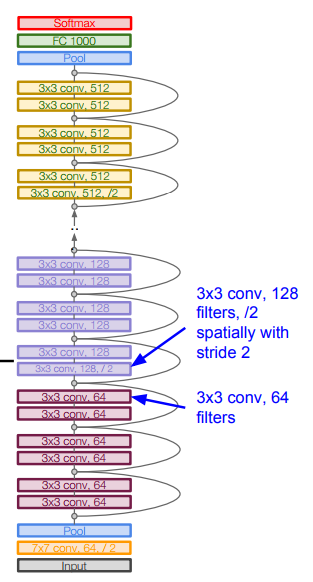
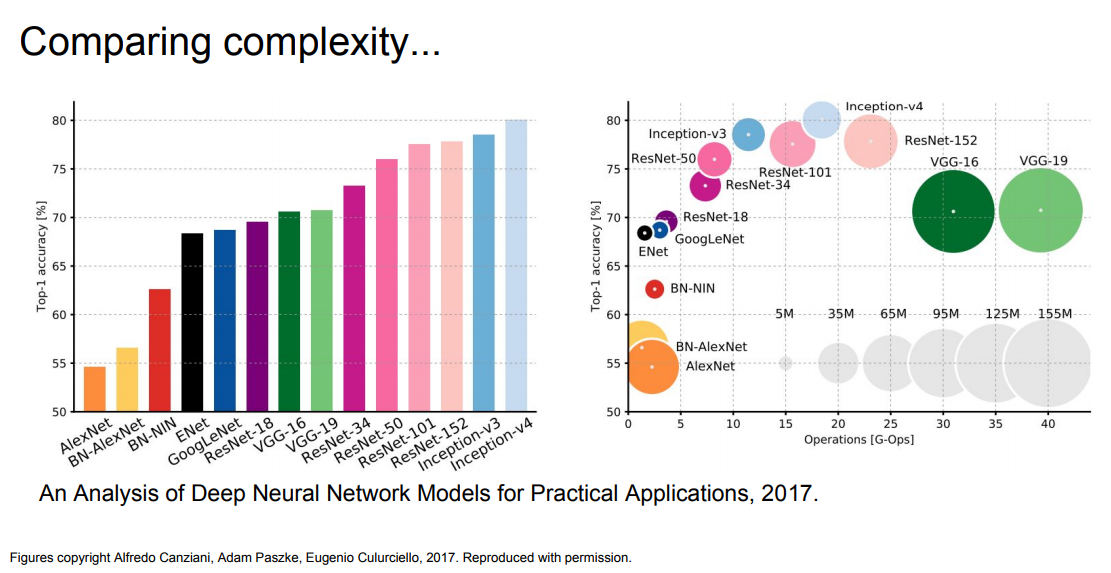
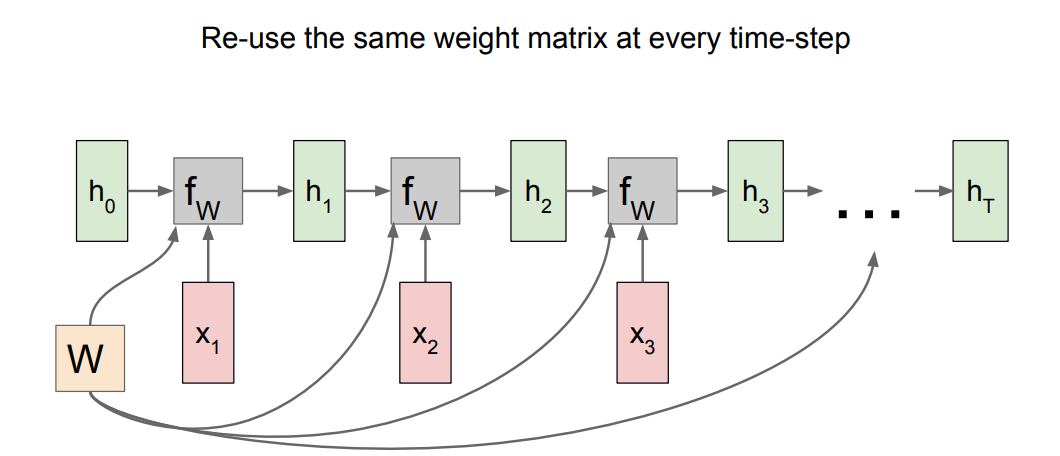
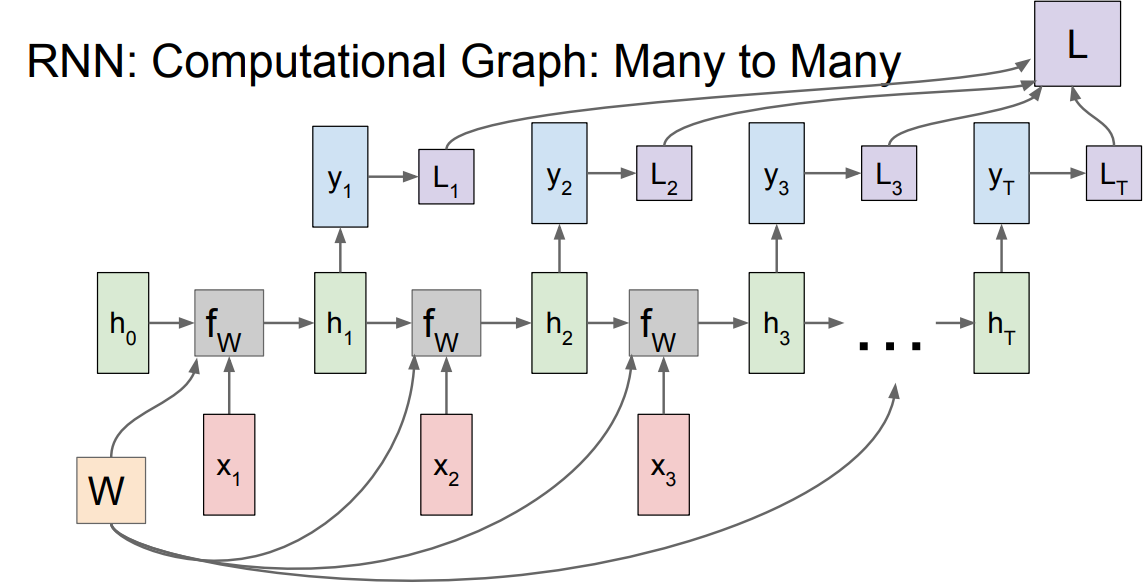
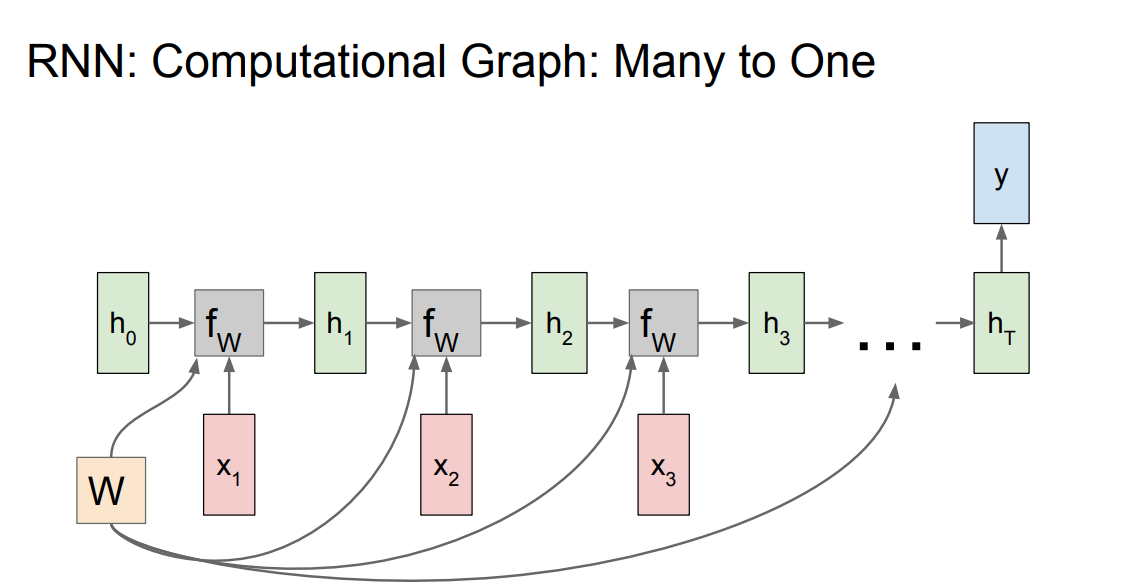
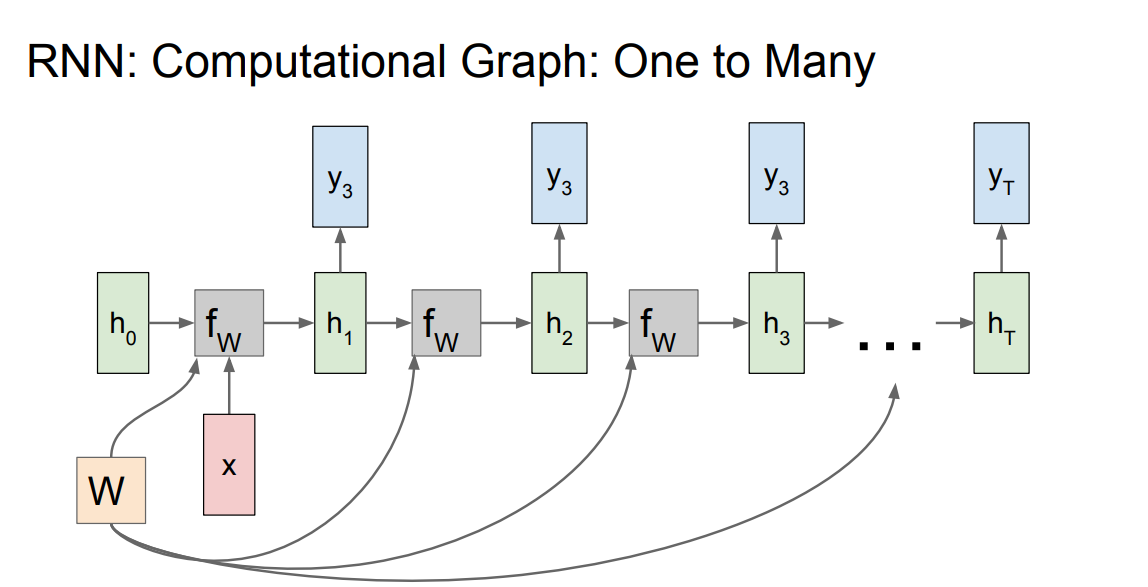
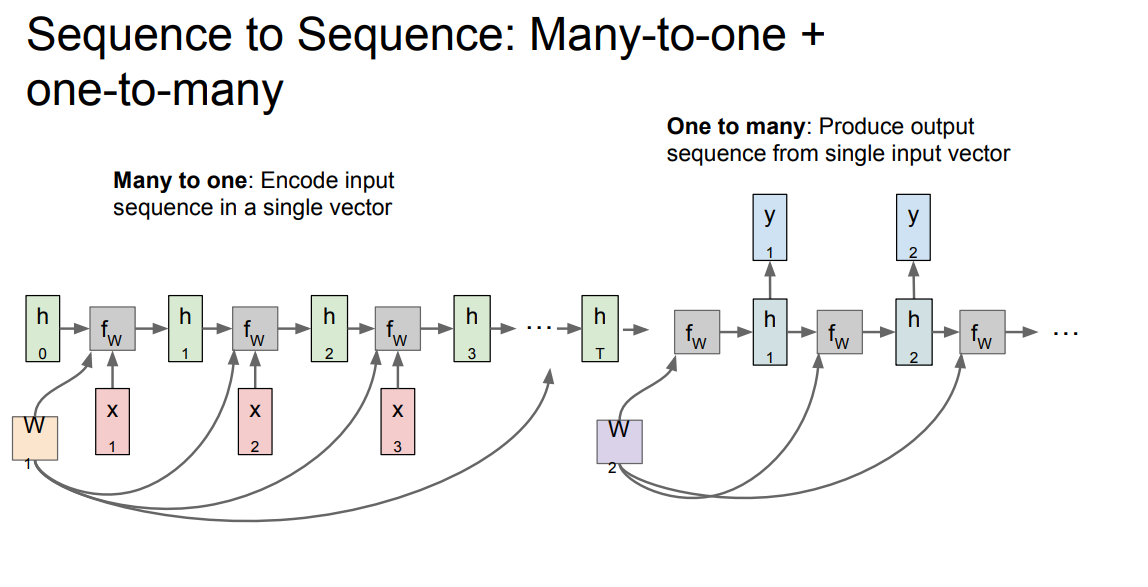
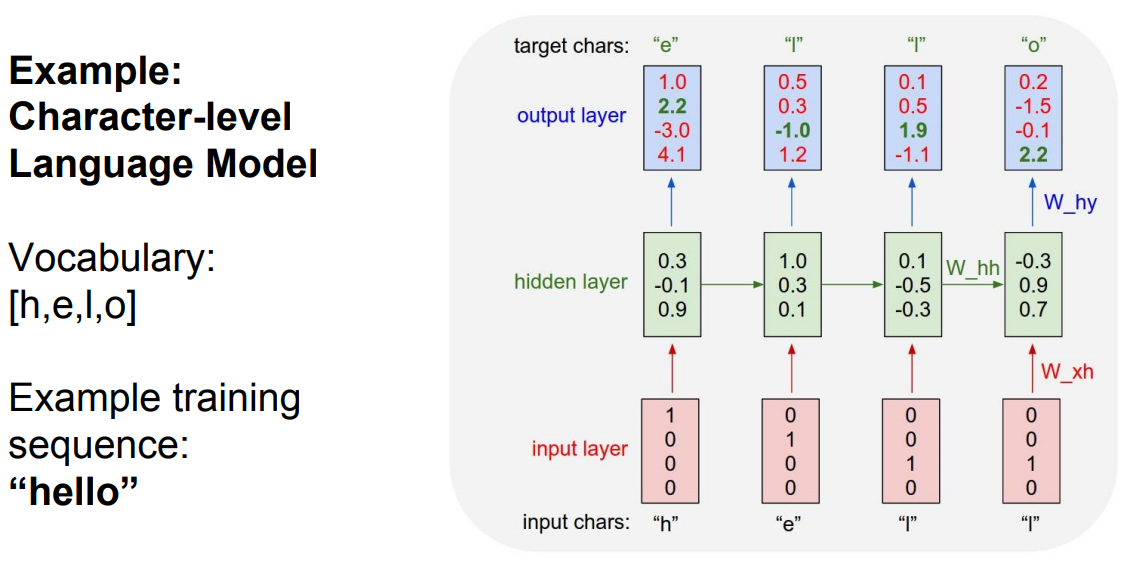
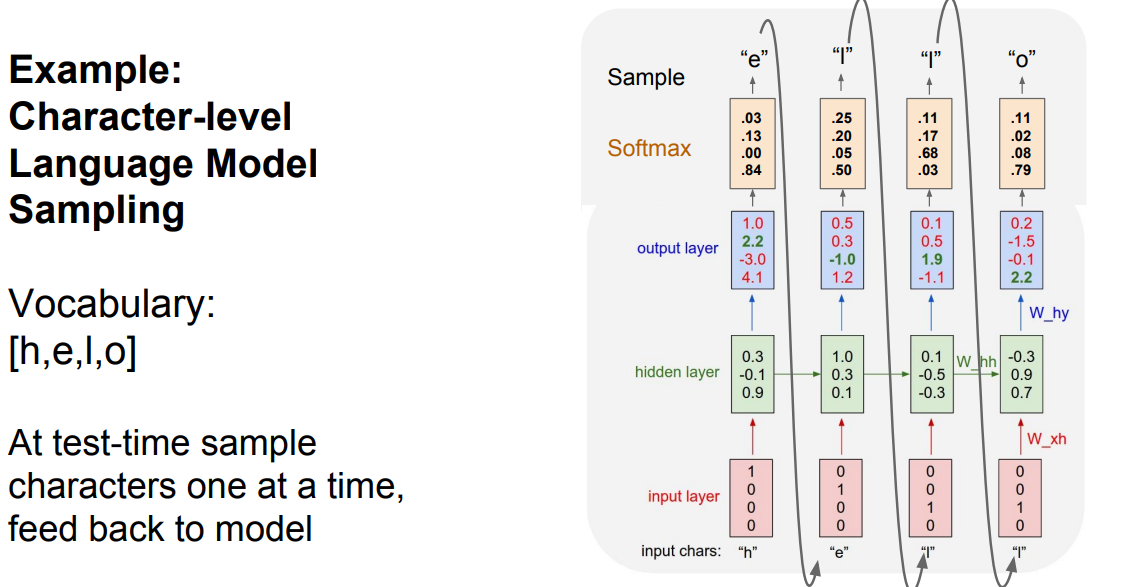
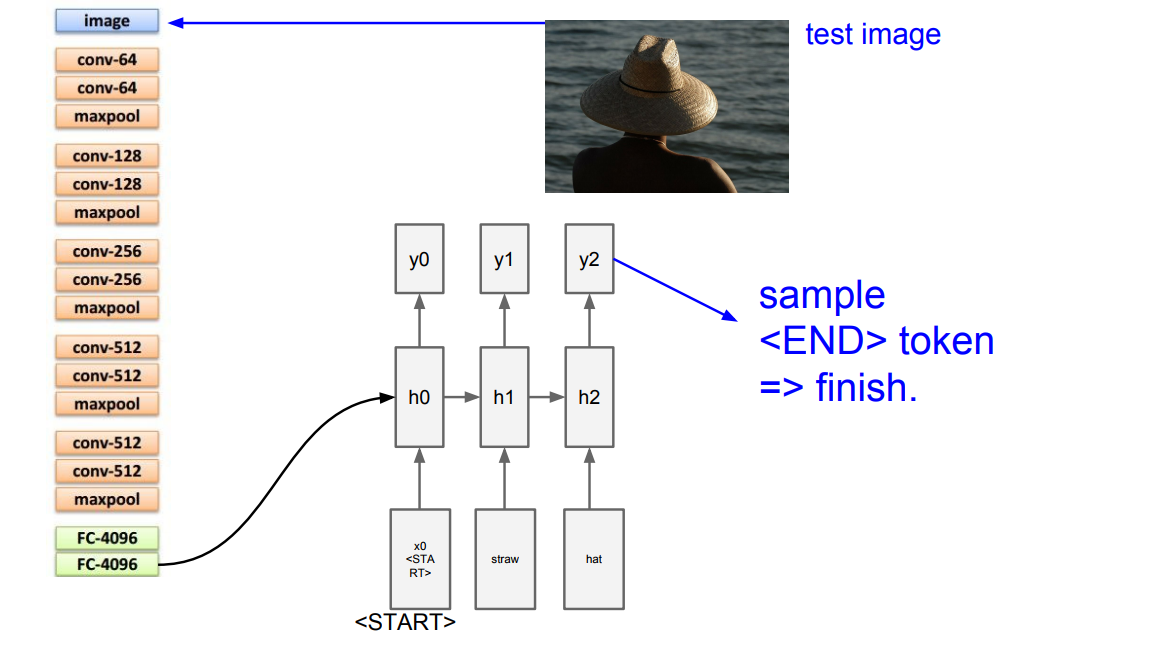
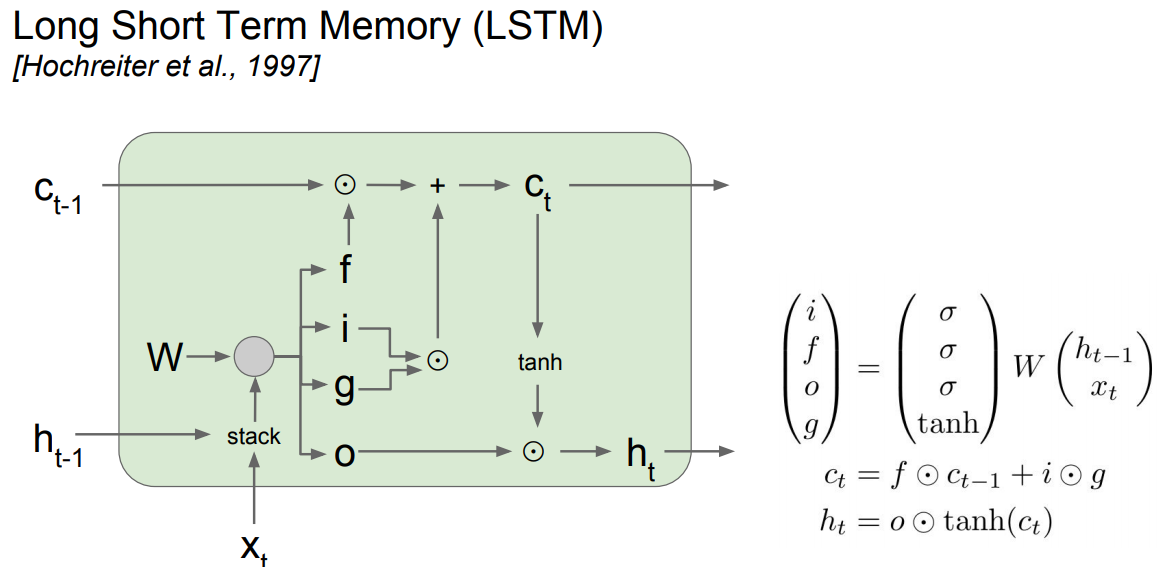
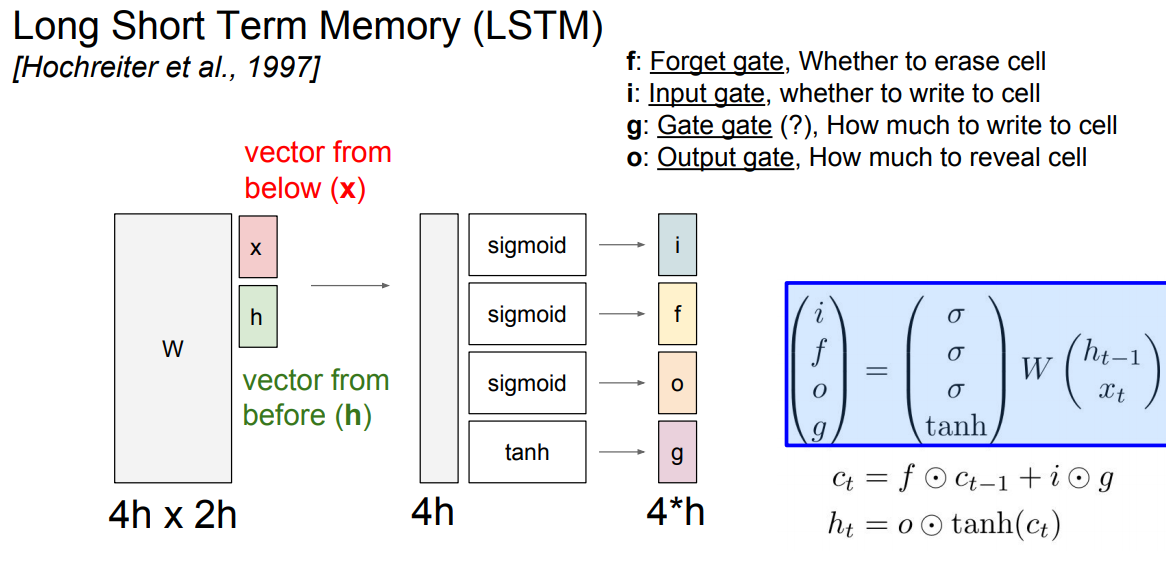

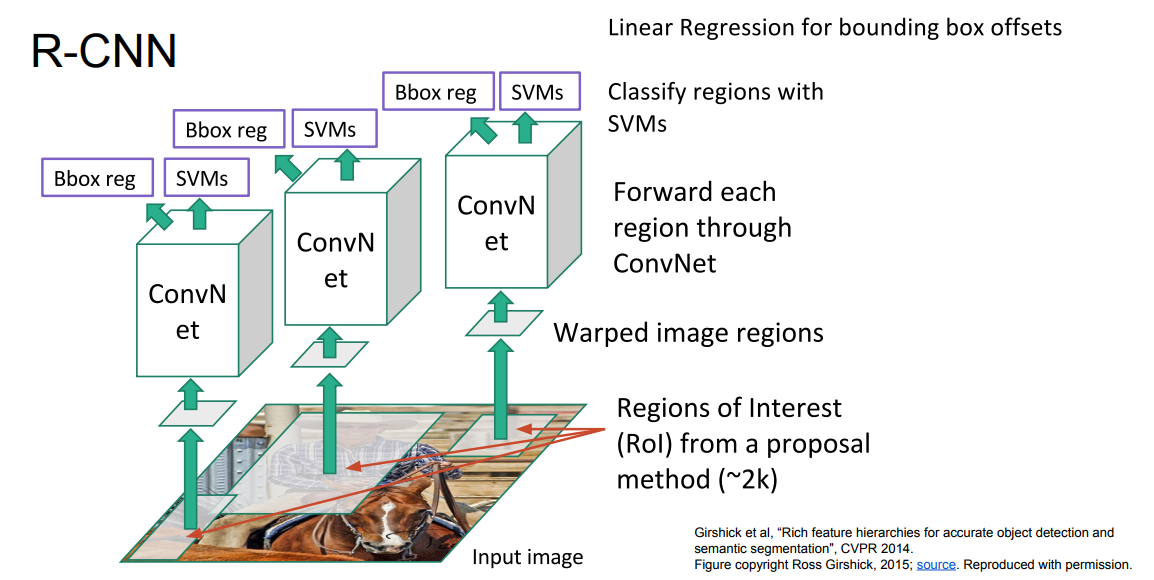
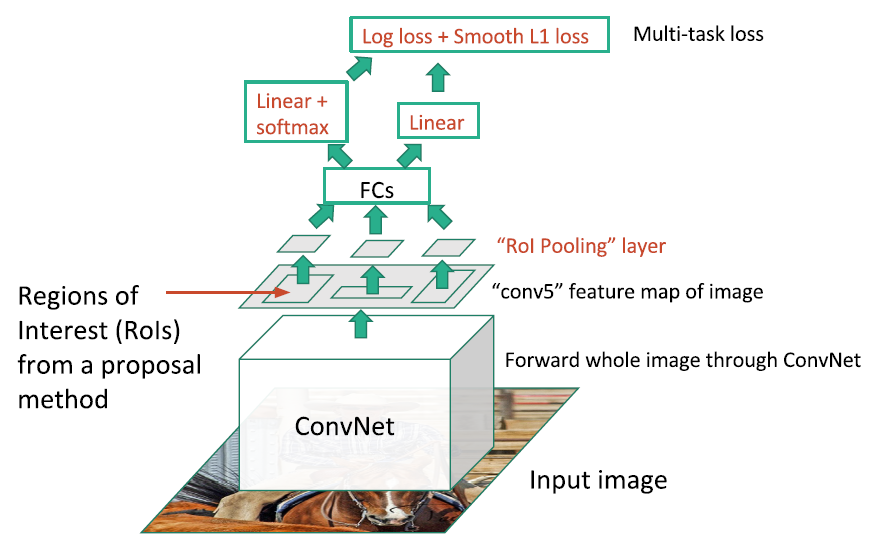





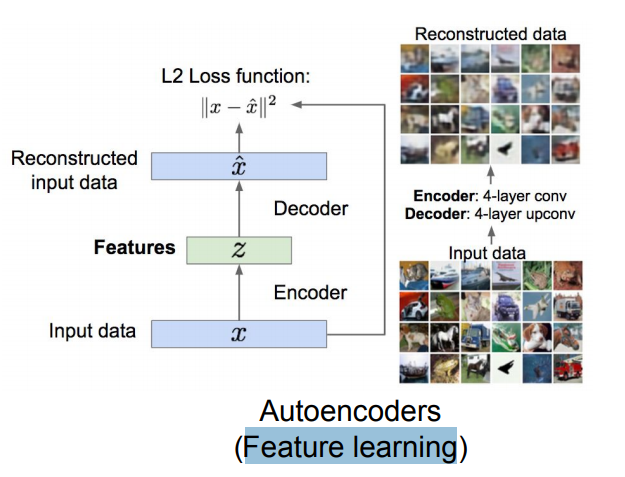
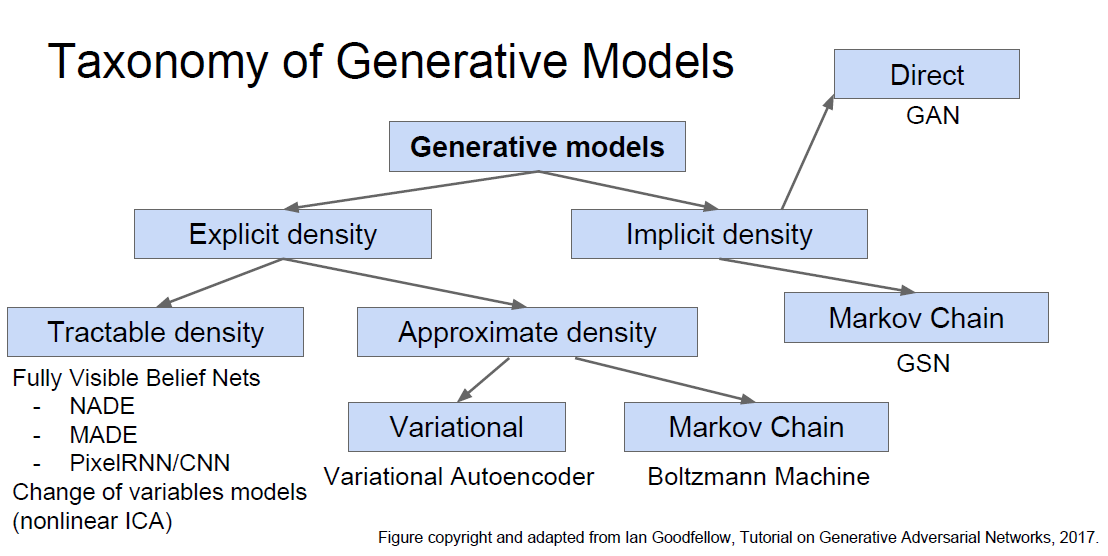

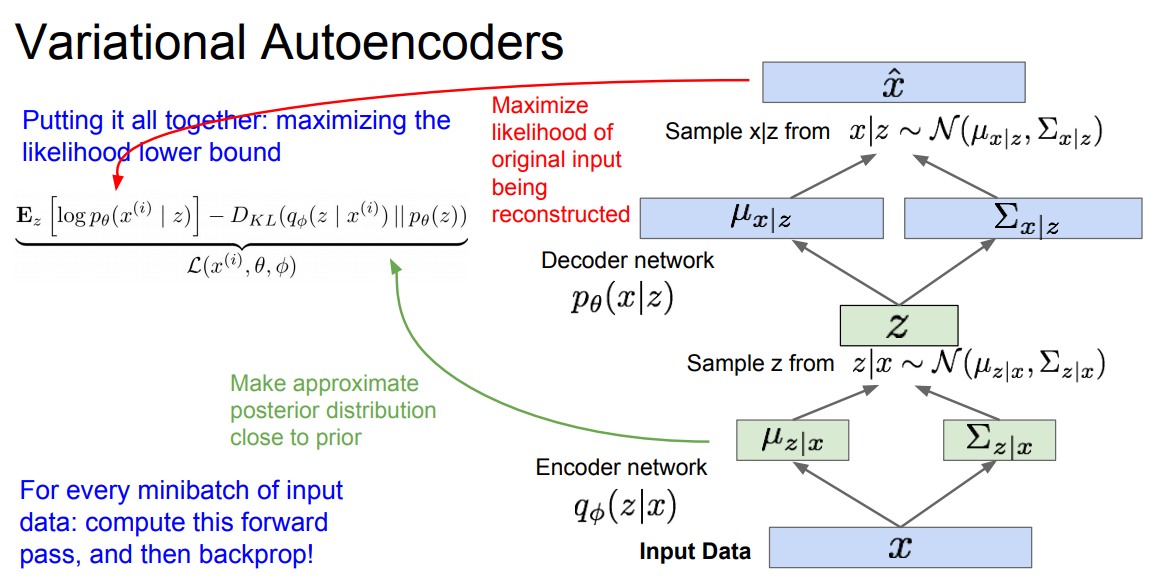


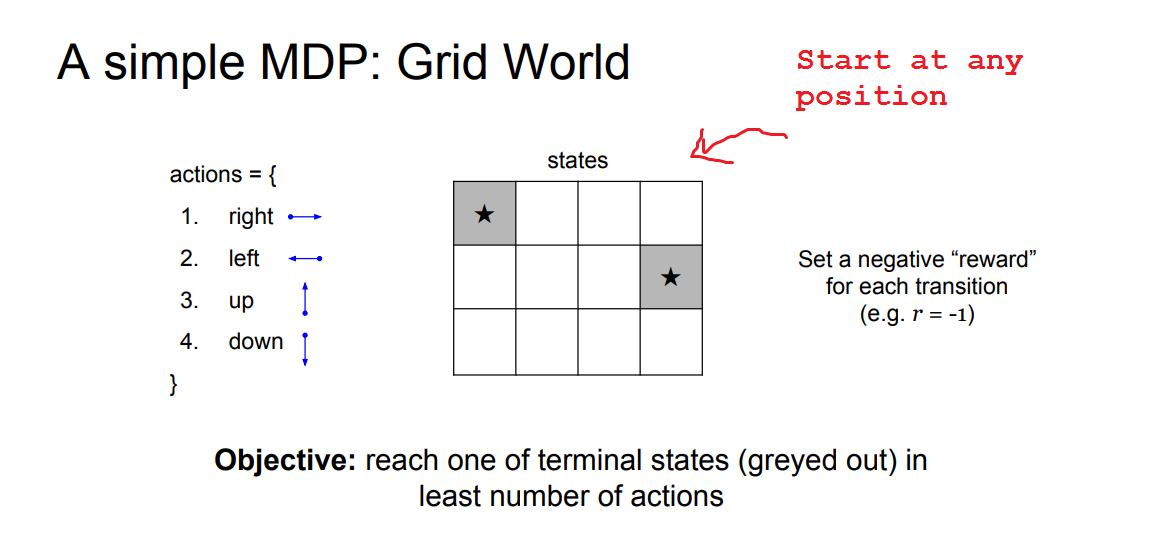
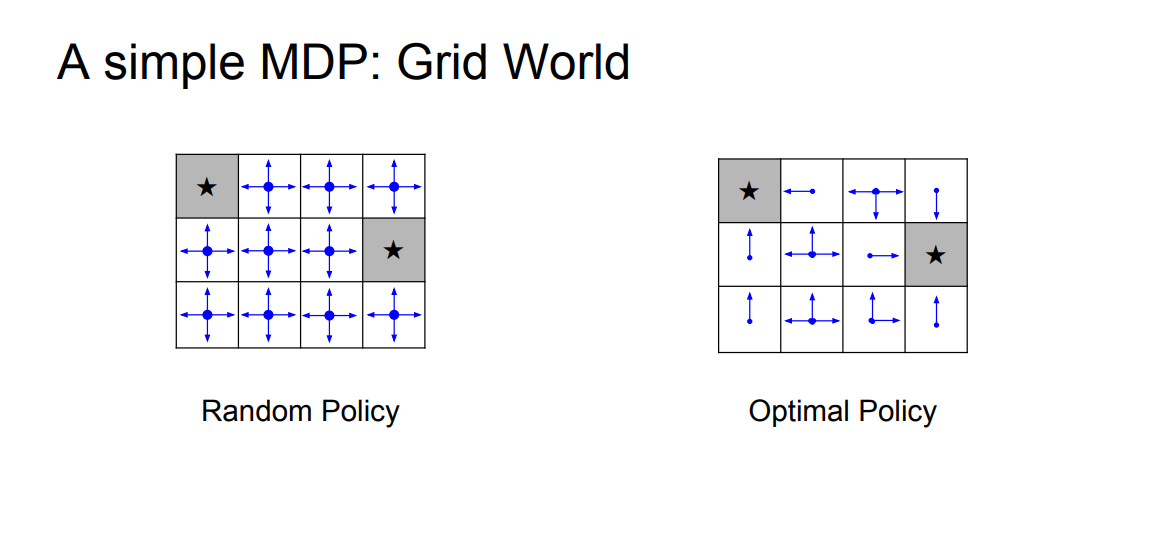


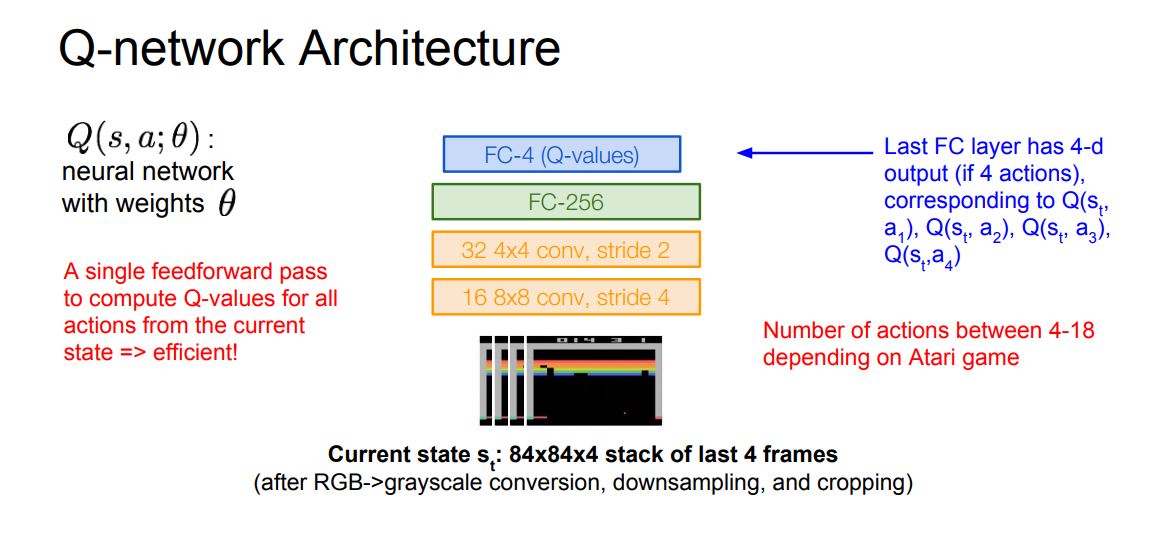



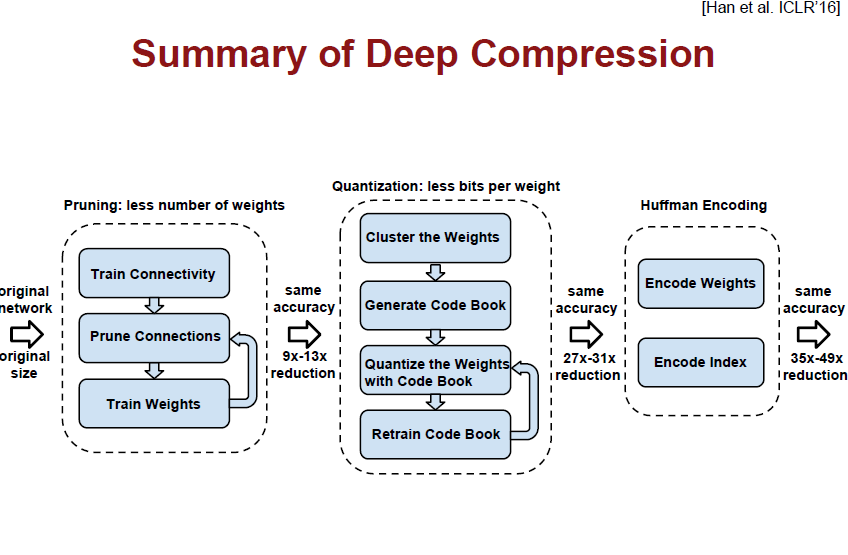
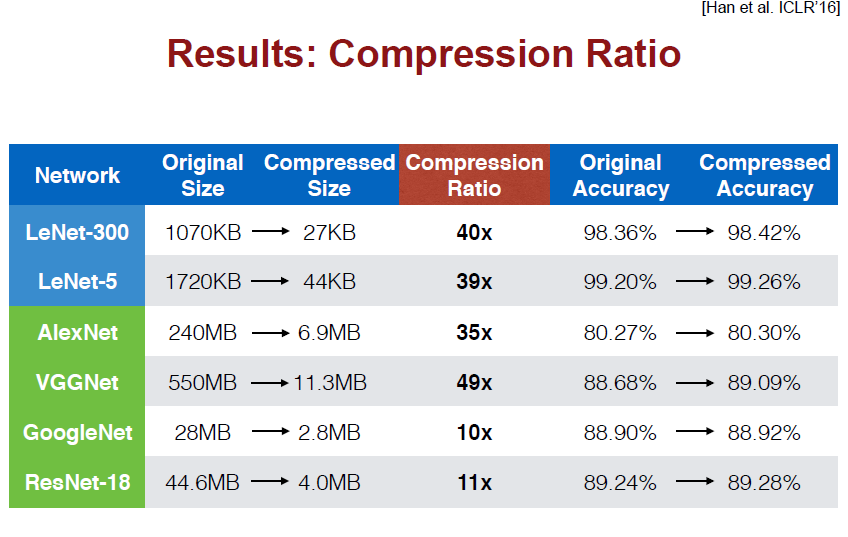
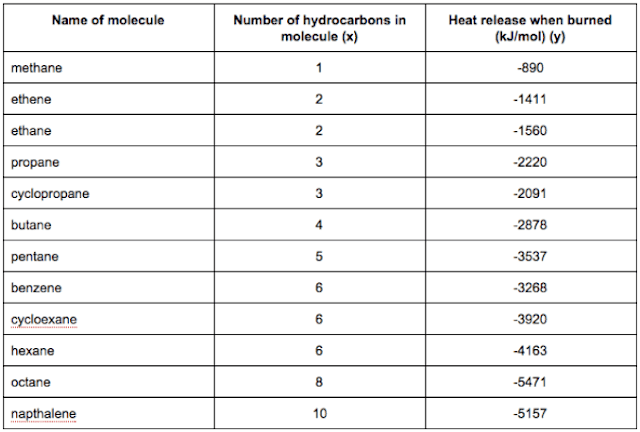
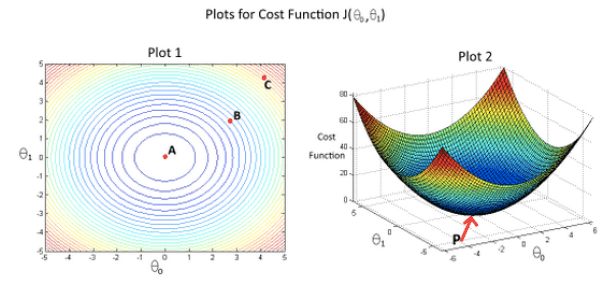
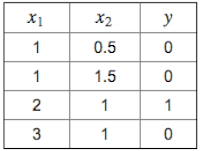
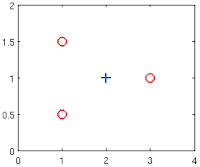
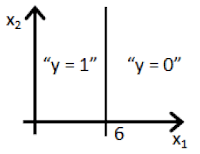
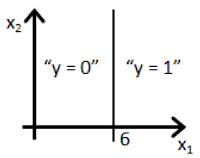
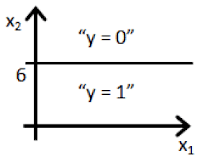
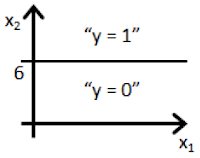
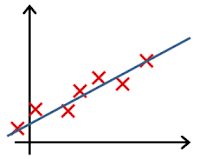
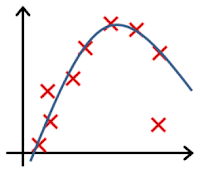
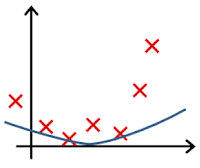
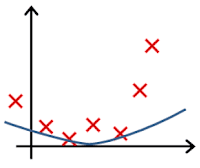
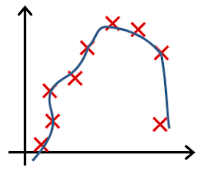
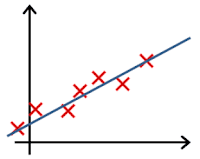
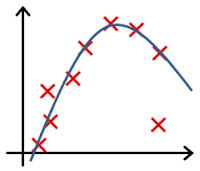
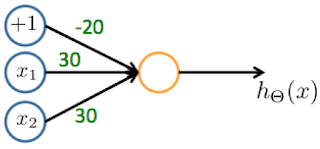
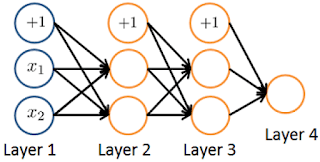
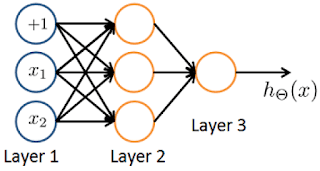

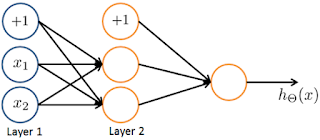
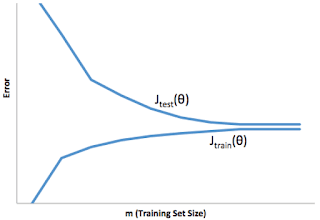
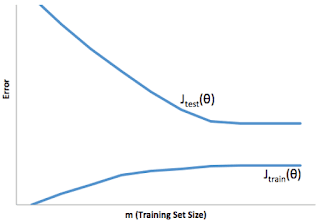


















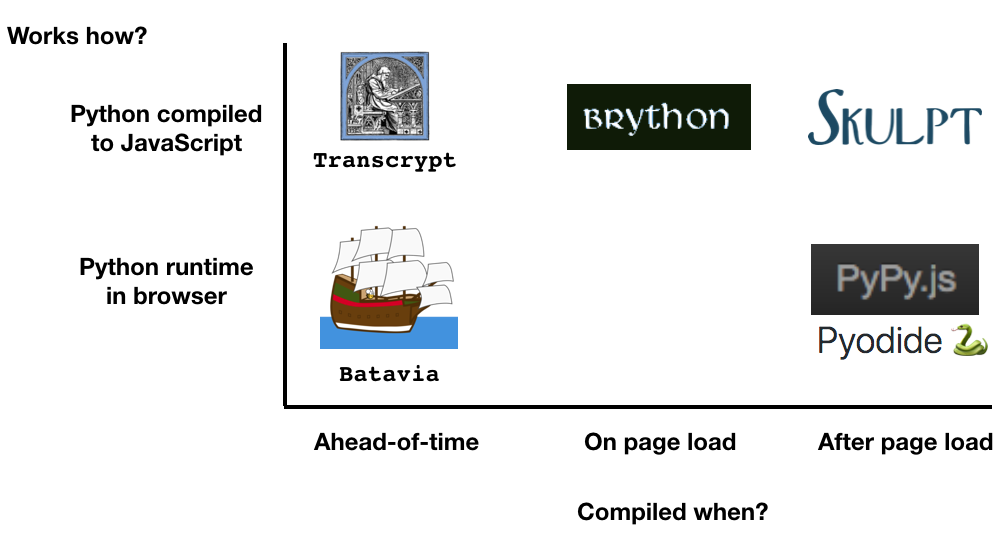
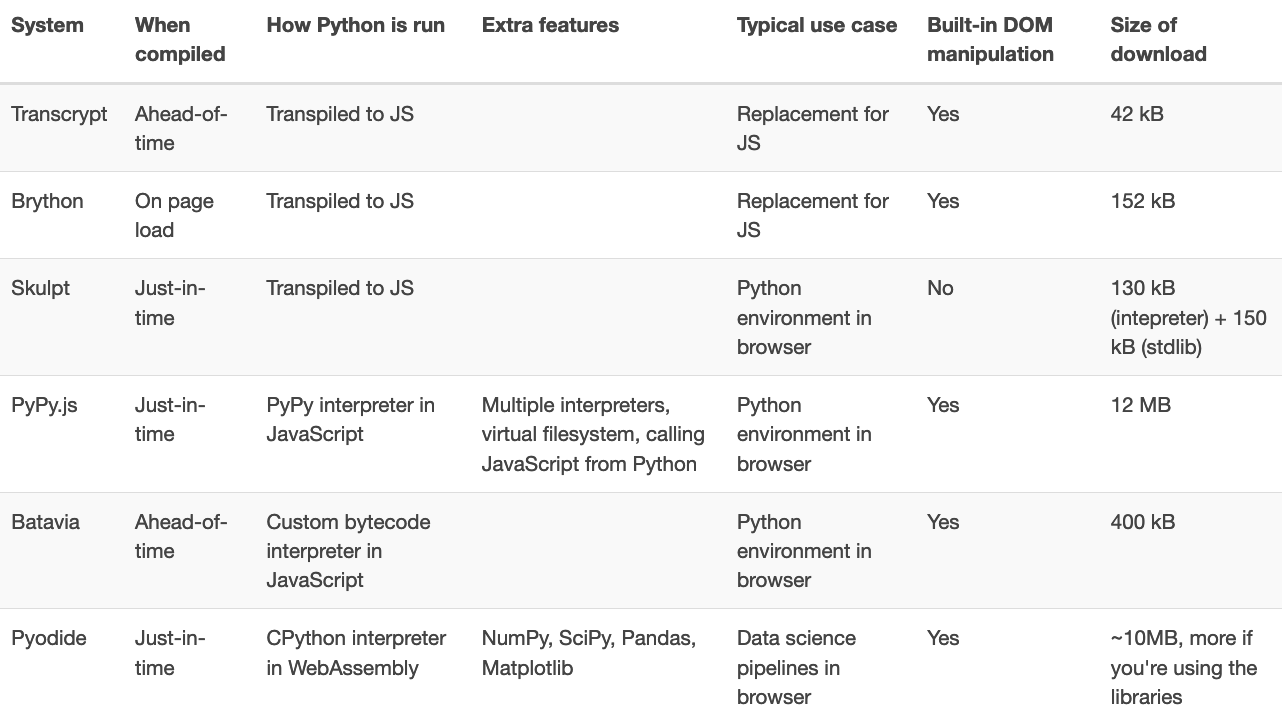

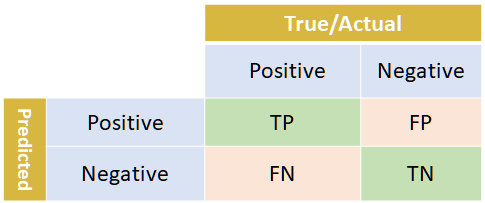


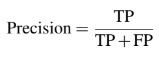
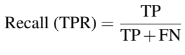

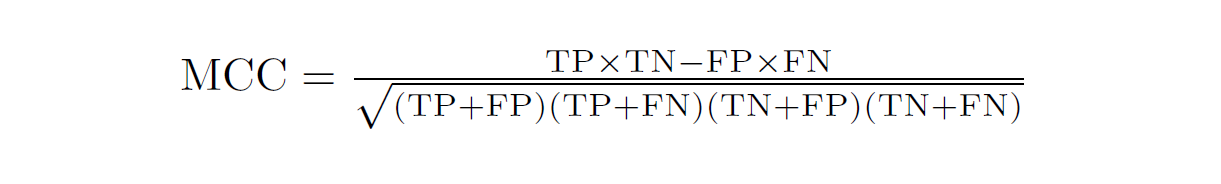
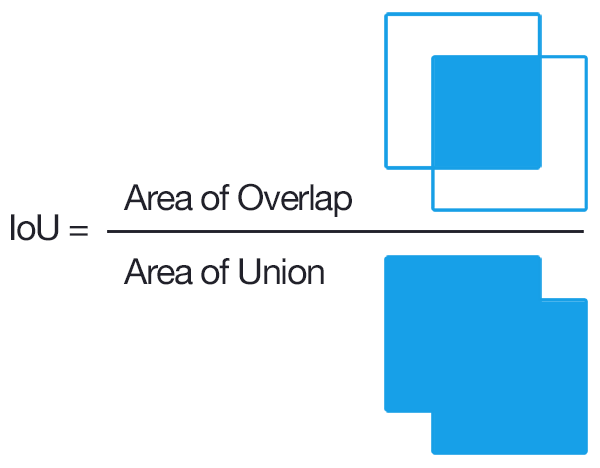

{kind=link}
{kind=link}
{kind=link}